Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Data Factory em Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA incorporada e novas funcionalidades. Se és novo na integração de dados, começa pelo Fabric Data Factory. As cargas de trabalho existentes do ADF podem atualizar para o Fabric para aceder a novas capacidades em ciência de dados, análise em tempo real e relatórios.
Execute os seus pipelines de Azure Machine Learning como um passo nos seus pipelines Azure Data Factory e Synapse Analytics. A atividade Machine Learning Execute Pipeline permite cenários de previsão em lote, como identificar possíveis incumprimentos de empréstimos, determinar sentimento e analisar padrões de comportamento dos clientes.
O vídeo abaixo apresenta uma introdução de seis minutos e uma demonstração desta funcionalidade.
Crie uma atividade de pipeline de execução de Machine Learning com UI
Para utilizar uma atividade Machine Learning Execute Pipeline num pipeline, complete os seguintes passos:
Procure por Machine Learning no painel de Atividades do pipeline e arraste uma atividade Machine Learning Executar Pipeline para o canvas do pipeline.
Selecione a nova atividade Machine Learning Executar Pipeline na tela se ainda não estiver selecionada, e o seu separador Settings, para editar os seus detalhes.
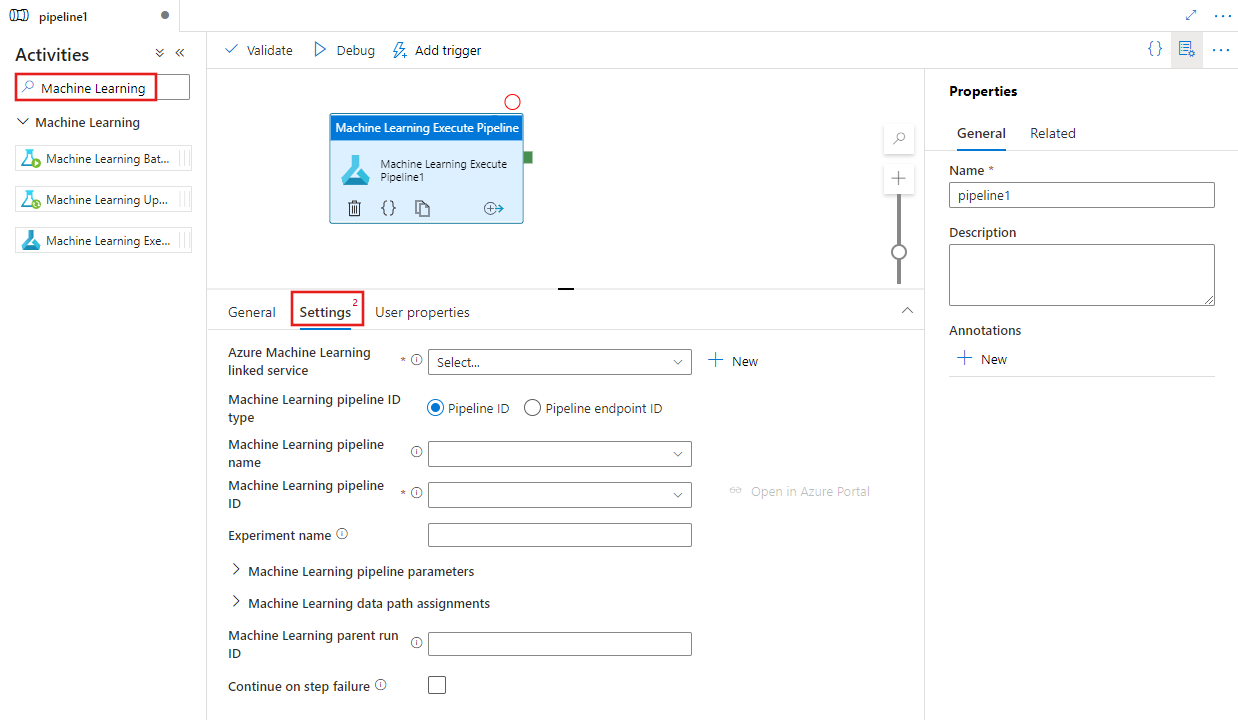
Selecione um serviço existente ou crie um novo serviço ligado ao Azure Machine Learning, e forneça detalhes do pipeline e do experimento, bem como quaisquer parâmetros do pipeline ou atribuições de caminhos de dados necessários para o pipeline.
Sintaxe
{
"name": "Machine Learning Execute Pipeline",
"type": "AzureMLExecutePipeline",
"linkedServiceName": {
"referenceName": "AzureMLService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"mlPipelineId": "machine learning pipeline ID",
"experimentName": "experimentName",
"mlPipelineParameters": {
"mlParameterName": "mlParameterValue"
}
}
}
Propriedades do tipo
| Propriedade | Descrição | Valores permitidos | Necessário |
|---|---|---|---|
| nome | Nome da atividade no processo de desenvolvimento | Cadeia (de carateres) | Sim |
| tipo | O tipo de atividade é 'AzureMLExecutePipeline' | Cadeia (de carateres) | Sim |
| nome do serviço ligado | Serviço Vinculado a Azure Machine Learning | Referência de serviço vinculado | Sim |
| mlPipelineId | ID do Azure Machine Learning pipeline publicado | String (ou expressão com resultType de String) | Sim |
| nome da experiência | Nome da experiência do histórico de execução do pipeline de Machine Learning | String (ou expressão com resultType de String) | Não |
| Parâmetros do mlPipeline | Os pares chave-valor que devem ser passados para o endpoint publicado do pipeline do Azure Machine Learning. As chaves devem corresponder aos nomes dos parâmetros do pipeline definidos no pipeline de Machine Learning publicado | Objeto com pares de valores de chave (ou Expressão com objeto resultType) | Não |
| mlParentRunId | O ID de execução do pipeline pai do Azure Machine Learning | String (ou expressão com resultType de String) | Não |
| dataPathAssignments | Dicionário usado para alterar datapaths no Azure Machine Learning. Permite a comutação de caminhos de dados | Objeto com pares de valores de chave | Não |
| continuarOnStepFailure | Deve continuar a execução de outros passos no pipeline de Machine Learning se um passo falhar? | boolean | Não |
Nota
Para que o utilizador possa preencher os itens suspensos no nome e ID do pipeline de Machine Learning, precisa ter permissão para listar pipelines de Machine Learning. A interface do usuário chama APIs do AzureMLService diretamente usando as credenciais do usuário conectado. O tempo de descoberta dos itens do menu suspenso seria muito maior ao usar Endpoints Privados.
Conteúdos relacionados
Consulte os seguintes artigos que explicam como transformar dados de outras maneiras: