Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Data Factory em Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA incorporada e novas funcionalidades. Se és novo na integração de dados, começa pelo Fabric Data Factory. As cargas de trabalho existentes do ADF podem atualizar para o Fabric para aceder a novas capacidades em ciência de dados, análise em tempo real e relatórios.
A atividade do Spark no Data Factory e nas pipelines do Synapse executa um programa Spark no seu próprio ou sob demanda cluster HDInsight. Este artigo baseia-se no artigo de atividades de transformação de dados, que apresenta uma visão geral da transformação de dados e das atividades de transformação suportadas. Quando você usa um serviço vinculado do Spark sob demanda, o serviço cria automaticamente um cluster do Spark para você processar os dados no momento certo e, em seguida, exclui o cluster assim que o processamento for concluído.
Adicionar uma atividade do Spark a um pipeline com a interface do usuário
Para usar uma atividade do Spark em um pipeline, conclua as seguintes etapas:
Procure Spark no painel Atividades do pipeline e arraste uma atividade Spark para o canvas do pipeline.
Selecione a nova atividade do Spark na tela, se ainda não estiver selecionada.
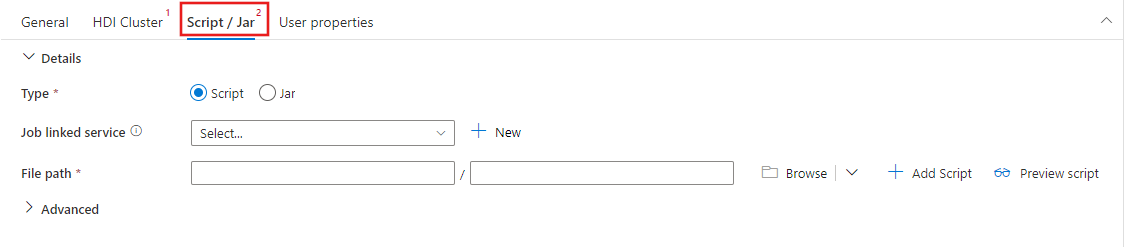
Selecione o separador Cluster HDI para selecionar ou criar um novo serviço ligado a um cluster HDInsight que será usado para executar a atividade Spark.
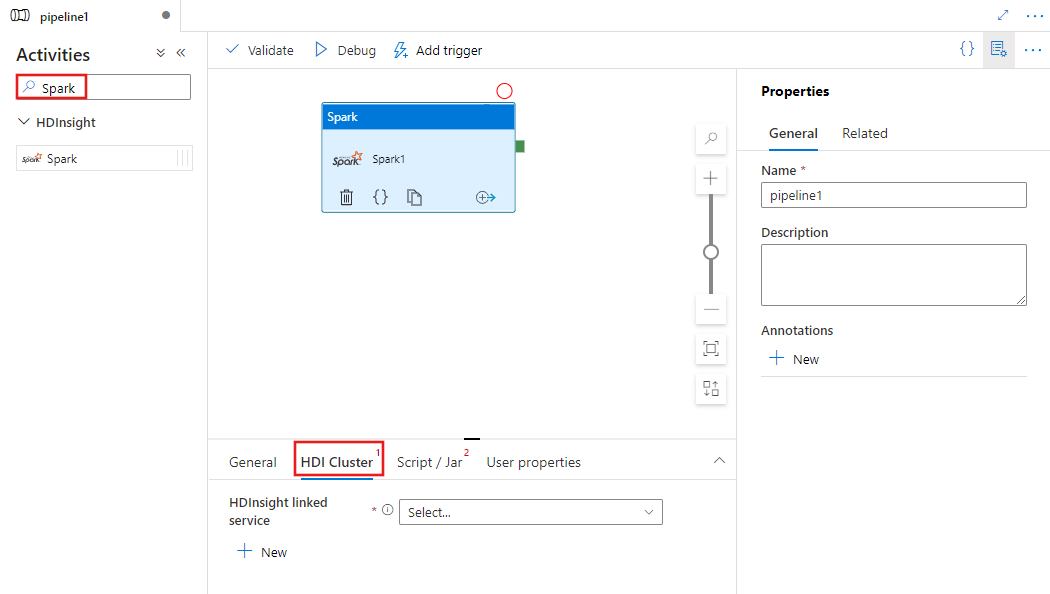
Selecione o separador Script / Jar para selecionar ou criar um novo serviço ligado a um emprego numa conta Azure Storage que irá alojar o seu script. Especifique um caminho para o arquivo a ser executado lá. Você também pode configurar detalhes avançados, incluindo um usuário proxy, configuração de depuração e argumentos e parâmetros de configuração do Spark a serem passados para o script.
Propriedades da atividade de faísca
Aqui está a definição JSON de exemplo de uma atividade Spark:
{
"name": "Spark Activity",
"description": "Description",
"type": "HDInsightSpark",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"sparkJobLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"rootPath": "adfspark",
"entryFilePath": "test.py",
"sparkConfig": {
"ConfigItem1": "Value"
},
"getDebugInfo": "Failure",
"arguments": [
"SampleHadoopJobArgument1"
]
}
}
A tabela a seguir descreve as propriedades JSON usadas na definição JSON:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| nome | Nome da atividade no fluxo de trabalho. | Sim |
| descrição | Texto que descreve o que a atividade faz. | Não |
| tipo | Para Spark Activity, o tipo de atividade é HDInsightSpark. | Sim |
| nomeDoServiçoVinculado | Nome do Serviço Vinculado do HDInsight Spark no qual o programa Spark é executado. Para saber mais sobre esse serviço vinculado, consulte o artigo Serviços vinculados de computação. | Sim |
| SparkJobLinkedService | O serviço associado do Azure Storage que contém o ficheiro de trabalho Spark, dependências e registos. Apenas os serviços ligados Azure Blob Storage e ADLS Gen2 são suportados aqui. Se você não especificar um valor para essa propriedade, o armazenamento associado ao cluster HDInsight será usado. O valor desta propriedade só pode ser um serviço ligado ao Azure Storage. | Não |
| rootPath | O contentor e pasta do Azure Blob que contém o ficheiro Spark. O nome do arquivo diferencia maiúsculas de minúsculas. Consulte a seção de estrutura de pastas (próxima seção) para obter detalhes sobre a estrutura dessa pasta. | Sim |
| entryFilePath | Caminho relativo para a pasta raiz do código/pacote do Spark. O ficheiro de entrada deve ser ou um ficheiro Python ou um ficheiro .jar. | Sim |
| className | Classe principal Java/Spark da aplicação | Não |
| Argumentos | Uma lista de argumentos de linha de comando para o programa Spark. | Não |
| proxyUser | A conta de utilizador a representar para executar o programa Spark | Não |
| sparkConfig | Especifique valores para as propriedades de configuração do Spark listadas no tópico: Configuração do Spark - Propriedades do aplicativo. | Não |
| getDebugInfo | Especifica quando os ficheiros de registo Spark são copiados para o armazenamento Azure usado pelo cluster HDInsight (ou) especificado pelo sparkJobLinkedService. Valores permitidos: Nenhum, Sempre ou Falha. Valor padrão: Nenhum. | Não |
Estrutura de pastas
As tarefas Spark são mais extensíveis do que as tarefas Pig/Hive. Para trabalhos Spark, podes fornecer múltiplas dependências como pacotes jar (colocados no Java CLASSPATH), ficheiros Python (colocados no PYTHONPATH) e quaisquer outros ficheiros.
Crie a seguinte estrutura de pastas no armazenamento Azure Blob referenciado pelo serviço ligado HDInsight. Em seguida, carregue arquivos dependentes para as subpastas apropriadas na pasta raiz representada por entryFilePath. Por exemplo, carregar ficheiros Python para a subpasta pyFiles e ficheiros jar para a subpasta jars da pasta raiz. Em tempo de execução, o serviço espera a seguinte estrutura de pastas no armazenamento Blob do Azure:
| Caminho | Descrição | Obrigatório | Tipo |
|---|---|---|---|
. (raiz) |
O caminho raiz do trabalho do Spark no serviço vinculado de armazenamento | Sim | Pasta |
| <definido pelo utilizador> | O caminho apontando para o ficheiro de entrada da tarefa do Spark | Sim | Ficheiro |
| ./jars | Todos os ficheiros desta pasta são carregados e colocados no classpath do Java do cluster. | Não | Pasta |
| ./pyFiles | Todos os arquivos sob esta pasta são carregados e colocados no PYTHONPATH do cluster | Não | Pasta |
| ./ficheiros | Todos os arquivos sob esta pasta são carregados e colocados no diretório de trabalho do executor | Não | Pasta |
| ./arquivos | Todos os arquivos nesta pasta são descompactados | Não | Pasta |
| ./logs | A pasta que contém logs do cluster Spark. | Não | Pasta |
Aqui está um exemplo de armazenamento contendo dois ficheiros de trabalho Spark no Azure Blob Storage referenciado pelo serviço ligado HDInsight.
SparkJob1
main.jar
files
input1.txt
input2.txt
jars
package1.jar
package2.jar
logs
archives
pyFiles
SparkJob2
main.py
pyFiles
scrip1.py
script2.py
logs
archives
jars
files
Conteúdos relacionados
Consulte os seguintes artigos que explicam como transformar dados de outras maneiras: