Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Data Factory em Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA incorporada e novas funcionalidades. Se és novo na integração de dados, começa pelo Fabric Data Factory. As cargas de trabalho existentes do ADF podem atualizar para o Fabric para aceder a novas capacidades em ciência de dados, análise em tempo real e relatórios.
Use a atividade Data Flow para transformar e mover dados através do mapeamento de fluxos de dados. Se é novo em fluxos de dados, veja Visão geral do Mapeamento de Fluxo de Dados
Criar uma atividade Data Flow com UI
Para usar uma atividade Data Flow num pipeline, complete os seguintes passos:
Procure por Data Flow no painel de Atividades do pipeline e arraste uma atividade Data Flow para o canvas do pipeline.
Selecione a nova atividade Data Flow na tela se ainda não estiver selecionada, e o seu separador Definições, para editar os seus detalhes.
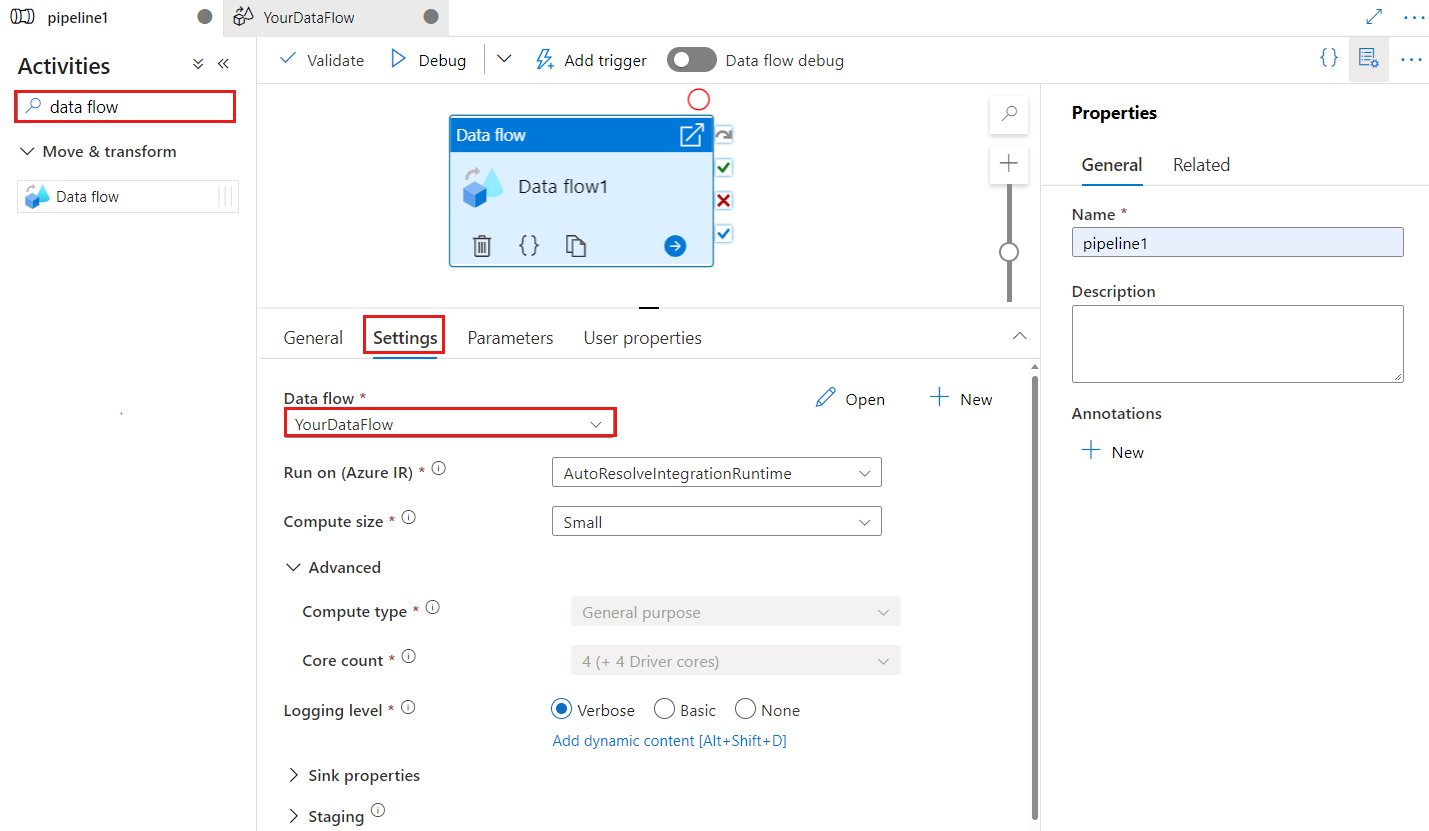
A chave de ponto de verificação é usada para definir o ponto de verificação quando o fluxo de dados é usado para captura de dados alterados. Você pode substituí-lo. As atividades de fluxo de dados usam um valor guid como chave de ponto de verificação em vez de "nome do pipeline + nome da atividade" para que o estado de captura das alterações de dados dos clientes possa ser sempre acompanhado, mesmo que haja ações de renomeação. Toda a atividade de fluxo de dados existente usa a chave de padrão antiga para compatibilidade com versões anteriores. A opção de chave de ponto de verificação após a publicação de uma nova atividade de fluxo de dados, com o recurso de captura de alterações de dados habilitado, é mostrada abaixo.
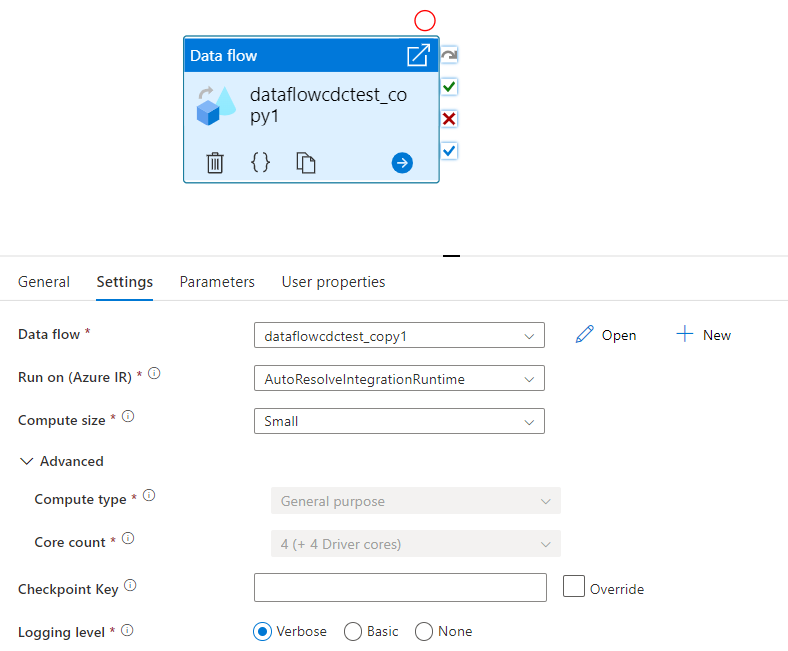
Selecione um fluxo de dados existente ou crie um novo usando o botão Novo. Selecione outras opções conforme necessário para concluir a configuração.
Sintaxe
{
"name": "MyDataFlowActivity",
"type": "ExecuteDataFlow",
"typeProperties": {
"dataflow": {
"referenceName": "MyDataFlow",
"type": "DataFlowReference"
},
"compute": {
"coreCount": 8,
"computeType": "General"
},
"traceLevel": "Fine",
"runConcurrently": true,
"continueOnError": true,
"staging": {
"linkedService": {
"referenceName": "MyStagingLinkedService",
"type": "LinkedServiceReference"
},
"folderPath": "my-container/my-folder"
},
"integrationRuntime": {
"referenceName": "MyDataFlowIntegrationRuntime",
"type": "IntegrationRuntimeReference"
}
}
Propriedades do tipo
| Propriedade | Descrição | Valores permitidos | Necessário |
|---|---|---|---|
| fluxo de dados | A referência ao Data Flow em execução | DataFlowReference | Sim |
| tempo de execução de integração | O ambiente de computação em que o fluxo de dados é executado. Se não for especificado, utiliza-se o runtime de integração do Azure com autoresolvimento. | IntegrationRuntimeReference | Não |
| compute.coreCount | O número de núcleos usados no cluster do Spark. Só pode ser especificado se for usado o runtime de integração do Azure com autoresolve | 8, 16, 32, 48, 80, 144, 272 | Não |
| compute.computeType | O tipo de cálculo usado no cluster Spark. Só pode ser especificado se for usado o runtime de integração do Azure com autoresolve | Geral | Não |
| staging.linkedService | Se estiver a usar uma fonte ou sink do Azure Synapse Analytics, especifique a conta de armazenamento usada para o staging do PolyBase. Se a sua Conta de Armazenamento Azure estiver configurada com o endpoint de serviço VNet, deve usar autenticação de identidade gerida com "permitir serviços confiáveis da Microsoft" ativado no armazenamento, consulte Impacto de usar Endpoints de Serviço VNet com Azure Storage. Também aprende as configurações necessárias para Azure Blob e Azure Data Lake Storage Gen2 respetivamente. |
LinkedServiceReference | Só se o fluxo de dados for lido ou escrito num Azure Synapse Analytics |
| staging.folderPath | Se estiveres a usar uma fonte ou sink do Azure Synapse Analytics, o caminho da pasta na conta de armazenamento de blobs usada para staging com o PolyBase | String | Só se o fluxo de dados ler ou escrever em Azure Synapse Analytics |
| traceLevel | Definir o nível de registro da execução da atividade de fluxo de dados | Bom, grosseiro, nenhum | Não |
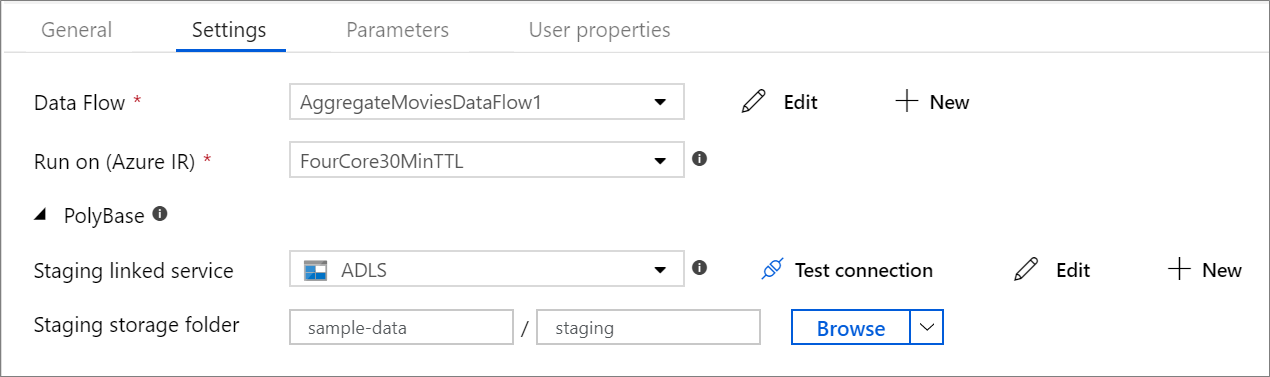
Dimensione dinamicamente a computação do fluxo de dados em tempo de execução
As propriedades Core Count e Compute Type podem ser definidas dinamicamente para se ajustarem ao tamanho dos dados de origem recebidos em tempo de execução. Use atividades de pipeline como Pesquisa ou Obter Metadados para encontrar o tamanho dos dados do conjunto de dados de origem. Depois, use Adicionar Conteúdo Dinâmico nas propriedades de atividade do Data Flow. Você pode escolher tamanhos de computação pequenos, médios ou grandes. Opcionalmente, escolha "Personalizado" e configure os tipos de computação e o número de núcleos manualmente.

Aqui está um breve tutorial em vídeo explicando essa técnica:
Runtime de integração do Data Flow
Escolha qual Integration Runtime usar para a execução da sua atividade Data Flow. Por defeito, o serviço utiliza o Azure Integration Runtime com resolução automática e quatro núcleos de trabalho. Este IR tem um tipo de computação de uso geral e é executado na mesma região que sua instância de serviço. Para pipelines operacionalizados, é altamente recomendado que crie os seus próprios Runtimes de Integração com o Azure que definam regiões específicas, tipo de computação, contagem de núcleos e TTL para a execução da atividade do fluxo de dados.
Um tipo mínimo de computação de Propósito Geral com uma configuração de 8+8 (16 v-cores totais) e um tempo de vida (TTL) de 10 minutos é a recomendação mínima para a maioria das cargas de trabalho de produção. Ao definir um TTL pequeno, o Azure IR pode manter um cluster pré-aquecido que evita o tempo de início prolongado de vários minutos, característico de um cluster frio. Para mais informações, consulte o Azure Integration Runtime.

Importante
A seleção do Integration Runtime na atividade de Data Flow aplica-se apenas a execuções acionadas do seu pipeline. A depuração do seu pipeline com fluxos de dados é realizada no cluster especificado na sessão de depuração.
PolyBase
Se estiver a usar Azure Synapse Analytics como destino ou fonte, deve escolher um local temporário para a sua carga em lote PolyBase. O PolyBase permite o carregamento em lote em massa em vez de carregar os dados linha por linha. O PolyBase reduz drasticamente o tempo de carregamento do Azure Synapse Analytics.
Chave de ponto de verificação
Ao usar a opção de captura de alterações para fontes de fluxo de dados, o ADF mantém e gerencia o ponto de verificação para você automaticamente. A chave de ponto de verificação padrão é um hash do nome do fluxo de dados e do nome do pipeline. Se você estiver usando um padrão dinâmico para suas tabelas ou pastas de origem, talvez queira substituir esse hash e definir seu próprio valor de chave de ponto de verificação aqui.
Nível de registo
Se não precisar que todas as execuções de pipeline das suas atividades de fluxo de dados registem totalmente todos os logs de telemetria detalhados, pode, opcionalmente, definir o seu nível de registo como "Básico" ou "Nenhum". Ao executar seus fluxos de dados no modo "Detalhado" (padrão), você está solicitando que o serviço registre totalmente a atividade em cada nível de partição individual durante a transformação de dados. Esta pode ser uma operação cara, portanto, ativar o modo detalhado apenas durante a solução de problemas pode melhorar o fluxo geral de dados e o desempenho do processo de pipeline. O modo "Básico" registra apenas as durações de transformação, enquanto "Nenhum" fornece apenas um resumo das durações.

Propriedades do lavatório
O recurso de agrupamento em fluxos de dados permite que você defina a ordem de execução de seus coletores, bem como agrupe coletores usando o mesmo número de grupo. Para ajudar a gerenciar grupos, você pode pedir ao serviço para executar coletores, no mesmo grupo, em paralelo. Você também pode definir o grupo de coletores para continuar mesmo depois que um dos coletores encontrar um erro.
O comportamento padrão dos coletores de fluxo de dados é executar cada coletor sequencialmente, de maneira serial, e falhar o fluxo de dados quando um erro for encontrado no coletor. Além disso, todos os coletores são padronizados para o mesmo grupo, a menos que você entre nas propriedades de fluxo de dados e defina prioridades diferentes para os coletores.

Apenas na primeira fila
Esta opção só está disponível para fluxos de dados que tenham coletores de cache habilitados para "Saída para atividade". A saída do fluxo de dados que é injetado diretamente no seu pipeline é limitada a 2MB. Definir "somente primeira linha" ajuda a limitar a saída de dados do fluxo de dados ao injetar a saída da atividade de fluxo de dados diretamente no pipeline.
Parametrização de fluxos de dados
Conjuntos de dados parametrizados
Se o fluxo de dados usar conjuntos de dados parametrizados, defina os valores dos parâmetros na guia Configurações .

Fluxos de dados parametrizados
Se o fluxo de dados for parametrizado, defina os valores dinâmicos dos parâmetros de fluxo de dados na guia Parâmetros . Você pode usar a linguagem de expressão de pipeline ou a linguagem de expressão de fluxo de dados para atribuir valores de parâmetros dinâmicos ou literais. Para mais informações, consulte Data Flow Parâmetros.
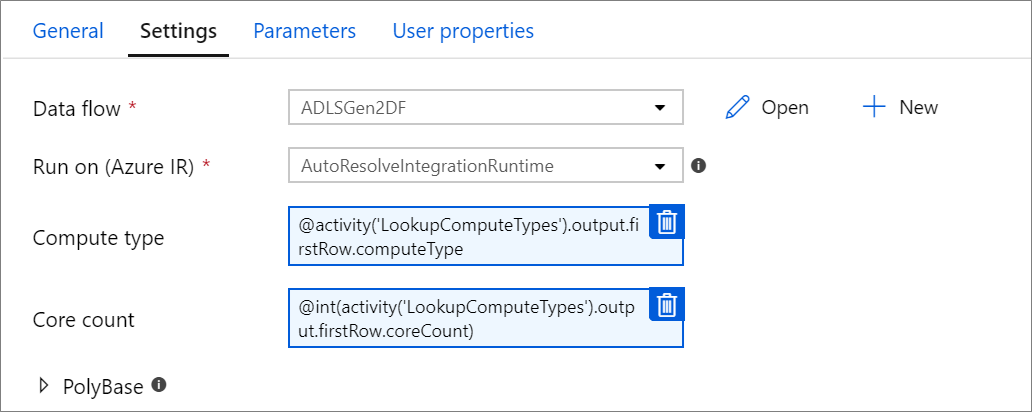
Propriedades de computação parametrizadas.
Pode parametrizar a contagem de núcleos ou o tipo de computação se usar o runtime de integração do Azure com autoresolve e especificar valores para compute.coreCount e compute.computeType.
Depuração de pipeline da atividade do Fluxo de Dados
Para executar um pipeline de depuração com uma atividade Data Flow, deve ativar o modo de depuração de Data Flow através do controle deslizante Data Flow Debug na barra superior. O modo de depuração permite executar o fluxo de dados em um cluster ativo do Spark. Para obter mais informações, consulte Modo de depuração.

O pipeline de debug é executado no cluster de depuração ativo, não no ambiente de execução de integração especificado nas definições de atividade do Data Flow. Você pode escolher o ambiente de computação de depuração ao iniciar o modo de depuração.
Monitorização da atividade do Data Flow
A atividade Data Flow tem uma experiência especial de monitorização onde pode visualizar o particionamento, o tempo de fase e a rastreabilidade dos dados. Abra o painel de monitorização através do ícone de óculos em Ações. Para obter mais informações, consulte Monitorando fluxos de dados.
A atividade Use Data Flow resulta numa atividade subsequente
A atividade de fluxo de dados produz métricas relativas ao número de linhas gravadas em cada coletor e linhas lidas de cada fonte. Esses resultados são retornados na output seção do resultado da execução da atividade. As métricas retornadas estão no formato do json abaixo.
{
"runStatus": {
"metrics": {
"<your sink name1>": {
"rowsWritten": <number of rows written>,
"sinkProcessingTime": <sink processing time in ms>,
"sources": {
"<your source name1>": {
"rowsRead": <number of rows read>
},
"<your source name2>": {
"rowsRead": <number of rows read>
},
...
}
},
"<your sink name2>": {
...
},
...
}
}
}
Por exemplo, para chegar ao número de linhas gravadas em um coletor chamado 'sink1' em uma atividade chamada 'dataflowActivity', use @activity('dataflowActivity').output.runStatus.metrics.sink1.rowsWritten.
Para obter o número de linhas lidas de uma fonte chamada 'source1' que foi usada nesse coletor, use @activity('dataflowActivity').output.runStatus.metrics.sink1.sources.source1.rowsRead.
Nota
Se um coletor tiver zero linhas escritas, ele não aparecerá nas métricas. A existência pode ser verificada usando a contains função. Por exemplo, contains(activity('dataflowActivity').output.runStatus.metrics, 'sink1') verifica se alguma linha foi gravada no sink1.
Conteúdos relacionados
Veja as atividades de fluxo de controle suportadas: