適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
Data Factory in Microsoft Fabric は、よりシンプルなアーキテクチャ、組み込みの AI、および新機能を備えた次世代のAzure Data Factoryです。 データ統合を初めて使用する場合は、Fabric Data Factory から始めます。 既存の ADF ワークロードをFabricにアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
Azure Data Factoryまたは Synapse Analytics pipeline の HDInsight MapReduce アクティビティは独自のまたは on-demand HDInsight クラスターで MapReduce プログラムを呼び出します。 この記事は、データ変換とサポートされる変換アクティビティの概要を説明する、 データ変換アクティビティ に関する記事に基づいています。
詳細については、Azure Data Factory および Synapse Analytics の概要に関する記事を参照し、この記事を読む前にチュートリアル「Tutorial: transform data」を参照してください。
HDInsight Pig と Hive アクティビティを使用してパイプラインから HDInsight クラスター上の Pig/Hive スクリプトを実行する方法の詳細については、Pig と Hive に関する記事をご覧ください。
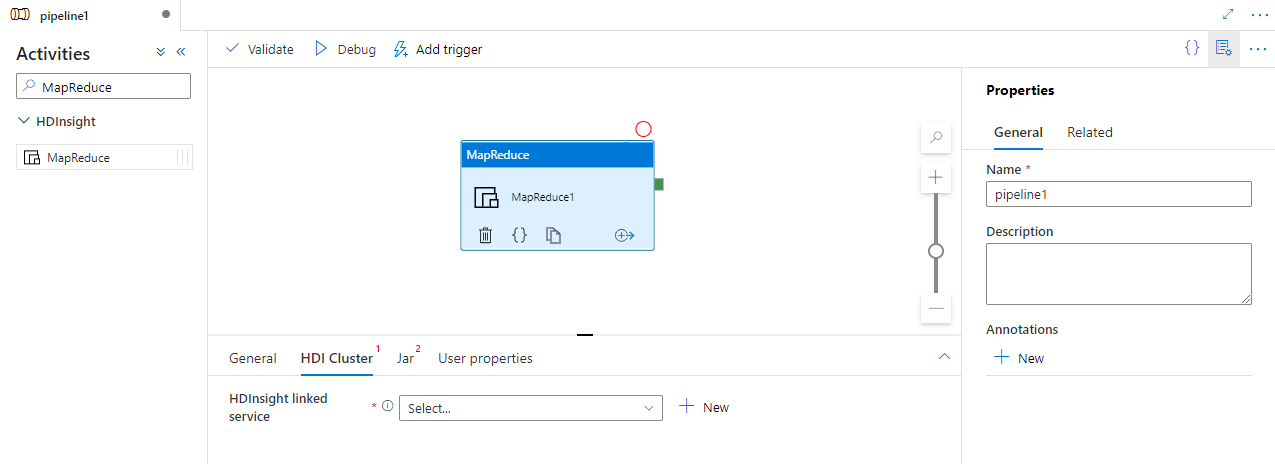
UI を使用して HDInsight MapReduce アクティビティをパイプラインに追加する
HDInsight MapReduce アクティビティをパイプラインに使用するには、次の手順を実行します。
パイプラインのアクティビティ ウィンドウ内で MapReduce を検索し、MapReduce アクティビティをパイプライン キャンバスにドラッグします。
まだ選択されていない場合は、キャンバスで新しい MapReduce アクティビティを選択します。
[HDI クラスター] タブを選択して、HDInsight クラスターに対する新しいリンクされたサービスを選択または作成します。このサービスは、MapReduce を実行するのに使用されます。
Jar タブを選択して、スクリプトをホストするAzure Storage アカウントに新しい Jar のリンクされたサービスを選択または作成します。 そこで実行するクラス名と、ストレージの場所内のファイル パスを指定します。 Jar ライブラリの場所、デバッグ構成や、スクリプトに渡される引数とパラメーターなど、詳細を構成することもできます。
![MapReduce アクティビティの [Jar] タブの UI を示しています。](media/transform-data-using-hadoop-map-reduce/map-reduce-script-configuration.png)
構文
{
"name": "Map Reduce Activity",
"description": "Description",
"type": "HDInsightMapReduce",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"className": "org.myorg.SampleClass",
"jarLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"jarFilePath": "MyAzureStorage/jars/sample.jar",
"getDebugInfo": "Failure",
"arguments": [
"-SampleHadoopJobArgument1"
],
"defines": {
"param1": "param1Value"
}
}
}
構文の詳細
| プロパティ | 内容 | 必須 |
|---|---|---|
| 名前 | アクティビティの名前 | はい |
| 説明 | アクティビティの用途を説明するテキストです。 | いいえ |
| 型 | MapReduce アクティビティの場合、アクティビティの種類は HDinsightMapReduce です | はい |
| linkedServiceName | リンクされたサービスとして登録されている HDInsight クラスターへの参照。 このリンクされたサービスの詳細については、計算のリンクされたサービスに関する記事をご覧ください。 | はい |
| className | 実行するクラスの名前 | はい |
| jarLinkedService | Jar ファイルの格納に使用するAzure Storageリンクされたサービスへの参照。 ここでは、Azure Blob Storage および ADLS Gen2 リンクされたサービスのみがサポートされています。 このリンクされたサービスを指定しない場合は、HDInsight のリンクされたサービスで定義されているAzure Storageリンクされたサービスが使用されます。 | いいえ |
| jarFilePath | jarLinkedService によって参照されるAzure Storageに格納されている Jar ファイルへのパスを指定します。 ファイル名は大文字と小文字が区別されます。 | はい |
| jarlibs | jarLinkedService で定義されたAzure Storageに格納されているジョブによって参照される Jar ライブラリ ファイルへのパスの文字列配列。 ファイル名は大文字と小文字が区別されます。 | いいえ |
| getDebugInfo | ログ ファイルが、hdInsight クラスターで使用されるAzure Storage (または jarLinkedService で指定) にコピーされるタイミングを指定します。 使用できる値は以下の通りです。None、Always、または Failure。 既定値:[なし] : | いいえ |
| 引数 | Hadoop ジョブの引数の配列を指定します。 引数はコマンド ライン引数として各タスクに渡されます。 | いいえ |
| 定義する | Hive スクリプト内で参照するキーと値のペアとしてパラメーターを指定します。 | いいえ |
例
HDInsight MapReduce アクティビティを使用して、HDInsight クラスター上で MapReduce jar ファイルを実行できます。 次のサンプルのパイプラインの JSON 定義では、Mahout JAR ファイルを実行するために HDInsight アクティビティが構成されます。
{
"name": "MapReduce Activity for Mahout",
"description": "Custom MapReduce to generate Mahout result",
"type": "HDInsightMapReduce",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"className": "org.apache.mahout.cf.taste.hadoop.similarity.item.ItemSimilarityJob",
"jarLinkedService": {
"referenceName": "MyStorageLinkedService",
"type": "LinkedServiceReference"
},
"jarFilePath": "adfsamples/Mahout/jars/mahout-examples-0.9.0.2.2.7.1-34.jar",
"arguments": [
"-s",
"SIMILARITY_LOGLIKELIHOOD",
"--input",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/input",
"--output",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/output/",
"--maxSimilaritiesPerItem",
"500",
"--tempDir",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/temp/mahout"
]
}
}
arguments セクションで MapReduce プログラムに任意の引数を指定できます。 実行時に、MapReduce フレームワークのいくつかの引数 (mapreduce.job.tags など) が表示されます。 MapReduce の引数と区別するために、次の例のように、オプションと値の両方を引数として使用することを検討してください (-s、--input、--output などがオプションであり、直後に値が続きます)。
関連するコンテンツ
別の手段でデータを変換する方法を説明している次の記事を参照してください。