Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Redigeringsprogrammet utan kod gör det enkelt att utveckla ett Stream Analytics-jobb för att bearbeta strömmande data i realtid. Använd dra och släpp-funktioner utan att skriva någon kod. Upplevelsen ger en arbetsyta där du kan ansluta till indatakällor för att snabbt se dina strömmande data. Sedan kan du transformera den innan du skriver till dina destinationer.
Genom att använda redigeringsprogrammet utan kod kan du enkelt:
- Ändra indatascheman.
- Utför dataförberedelseåtgärder som kopplingar och filter.
- Använd avancerade scenarier som tidsfönsterbaserade aggregeringar (rullande, hoppande och sessionsfönster) för grupperingsoperationer.
När du har skapat och kört dina Stream Analytics-jobb kan du enkelt operationalisera produktionsarbetsbelastningar. Använd rätt uppsättning inbyggda mått för övervakning och felsökning. Stream Analytics-jobb faktureras enligt prismodellen när de körs.
Förutsättningar
Innan du utvecklar dina Stream Analytics-jobb med hjälp av redigeringsprogrammet utan kod måste du uppfylla följande krav:
- Strömmande indatakällor och målresurser för Stream Analytics-jobbet måste vara offentligt tillgängliga och kan inte finnas i ett virtuellt Azure-nätverk.
- Du måste ha de behörigheter som krävs för att få åtkomst till strömmande in- och utdataresurser.
- Du måste ha behörighet att skapa och ändra Azure Stream Analytics-resurser.
Kommentar
Redigeringsprogrammet utan kod är för närvarande inte tillgängligt i Kina-regionen.
Azure Stream Analytics-jobb
Ett Stream Analytics-jobb bygger på tre huvudkomponenter: strömmande indata, transformeringar och utdata. Du kan inkludera så många komponenter du vill, till exempel flera indata, parallella grenar med flera transformeringar och flera utdata. Mer information finns i Dokumentation om Azure Stream Analytics.
Kommentar
Följande funktioner och utdatatyper är inte tillgängliga när du använder redigeringsprogrammet utan kod:
- Användardefinierade funktioner.
- Frågeredigering på Azure Stream Analytics frågesida. Du kan dock visa frågan som genereras av redigeringsprogrammet utan kod på frågesidan.
- Lägga till indata och utdata på Azure Stream Analytics in- och utdatasidor. Du kan dock visa indata och utdata som genereras av redigeringsprogrammet utan kod på in- och utdatasidan.
- Följande utdatatyper är inte tillgängliga: Azure Function, Azure Data Lake Storage Gen1, PostgreSQL DB, Service Bus queue/topic, Table Storage.
Använd någon av följande metoder för att komma åt redigeringsprogrammet utan kod för att skapa ditt stream analytics-jobb:
Via Azure Stream Analytics-portalen (förhandsversion): Skapa ett Stream Analytics-jobb och välj sedan redigeringsprogrammet utan kod på fliken Kom igång på översiktssidan eller välj No-code editor i den vänstra panelen.
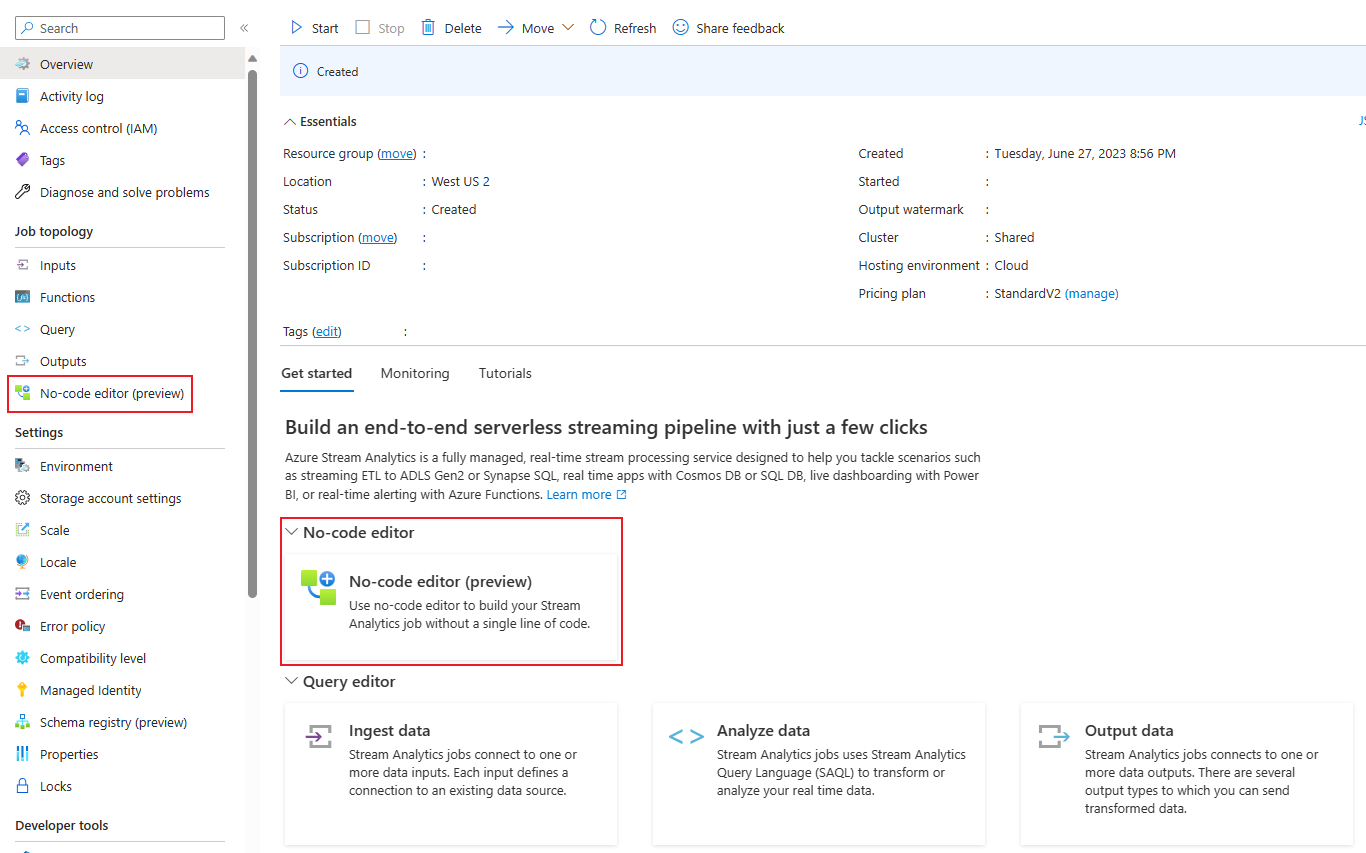
Via Azure Event Hubs-portalen: Öppna en Event Hubs-instans. Välj Bearbeta data och välj sedan valfri fördefinierad mall.
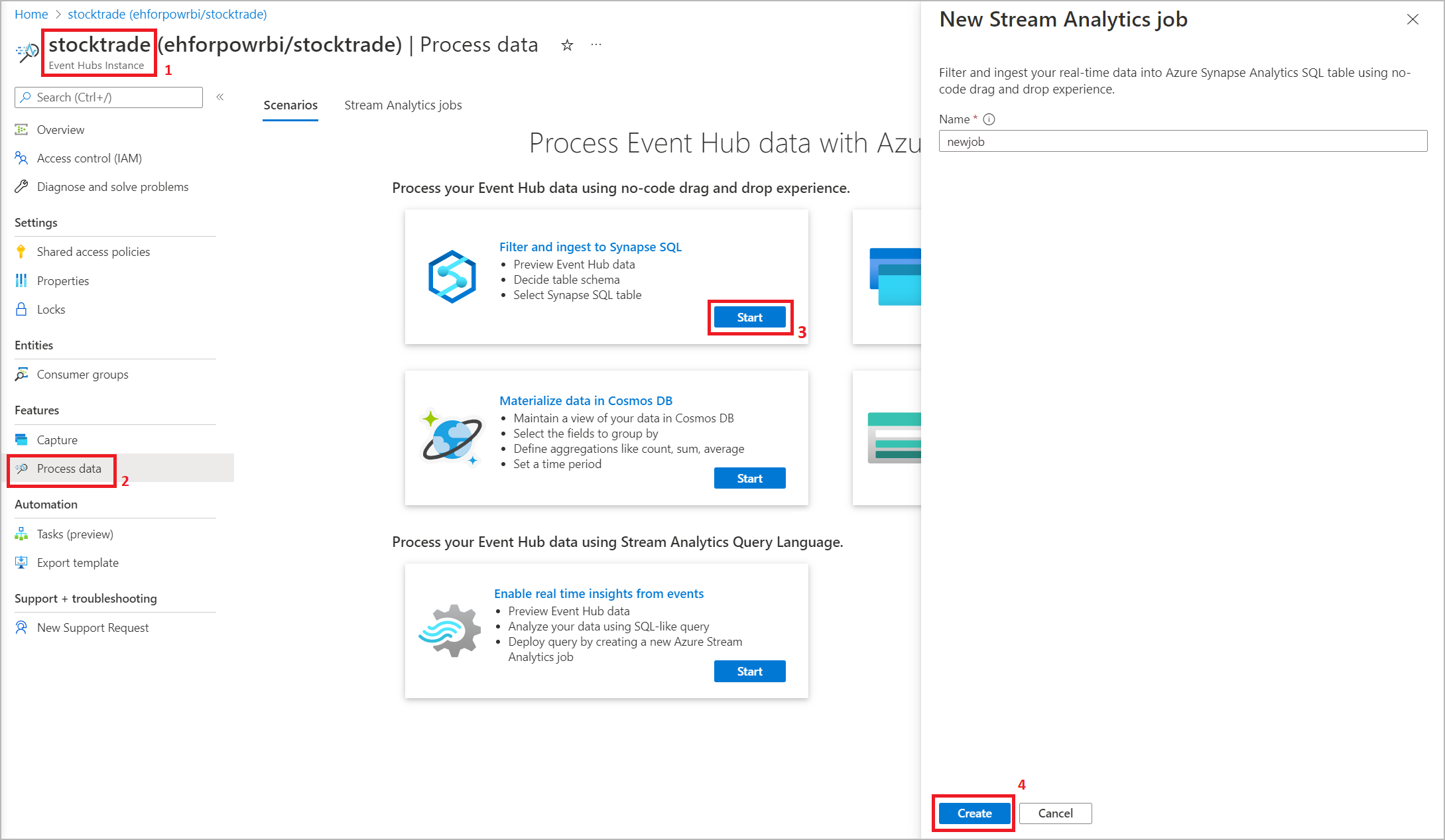
De fördefinierade mallarna kan hjälpa dig att utveckla och köra ett jobb för att hantera olika scenarier, inklusive:
- Samla in data från Event Hubs i Delta Lake-format (förhandsversion)
- Filtrera och mata in till Azure Synapse SQL
- Fånga in data från dina Event Hubs i Parquet-format i Azure Data Lake Storage Gen2
- Materialisera data i Azure Cosmos DB
- Filtrera och mata in till Azure Data Lake Storage Gen2
- Utöka data och mata in till händelsehubben
- Transformera och lagra data till Azure SQL-databas
- Filtrera och mata in till Azure Data Explorer


Följande skärmbild visar ett slutfört Stream Analytics-jobb. Den visar alla avsnitt som är tillgängliga för dig när du skriver.

- Menyfliksområde: I menyfliksområdet följer avsnitt ordningen på en klassisk analysprocess: en händelsehubb som indata (kallas även för en datakälla), transformeringar (strömmande extraherings-, transformerings- och inläsningsåtgärder), utdata, en knapp för att spara förloppet och en knapp för att starta jobbet.
- Diagramvy: Den här vyn är en grafisk representation av ditt Stream Analytics-jobb, från indata till åtgärder till utdata.
- Sidofönster: Beroende på vilken komponent du väljer i diagramvyn visas inställningar för att ändra indata, transformering eller utdata.
- Flikar för dataförhandsgranskning, redigeringsfel, körningsloggar och mått: För varje panel visar dataförhandsgranskningen resultat för det steget (live för indata, på begäran för omvandlingar och utdata). Det här avsnittet sammanfattar även eventuella redigeringsfel eller varningar som du kan ha i ditt jobb när det utvecklas. När du väljer ett fel eller en varning, väljs den transformeringen. Den tillhandahåller även jobbmått för att övervaka hälsotillståndet hos det pågående jobbet.
Strömmande datainmatning
Redigeringsprogrammet utan kod stöder strömmande dataindata från tre typer av resurser:
- Azure Event Hubs
- Azure IoT Hub
- Azure Data Lake Storage Gen2
Mer information om strömmande dataindata finns i Strömma data som indata till Stream Analytics.
Kommentar
Redigeringsprogrammet utan kod i Azure Event Hubs-portalen har bara Event Hub som indataalternativ.

Azure Event Hubs som strömmande indata
Azure Event Hubs är en stordataströmningsplattform och händelseinmatningstjänst. Den kan ta emot och behandla miljoner händelser per sekund. Du kan transformera och lagra data som skickas till en händelsehubb via valfri leverantör av realtidsanalys eller batchbearbetnings- och lagringsadapter.
Om du vill konfigurera en händelsehubb som indata för ditt jobb väljer du ikonen Händelsehubb . En panel visas i diagramvyn, inklusive en sidoruta för dess konfiguration och anslutning.
När du ansluter till händelsehubben i redigeringsprogrammet utan kod skapar du en ny konsumentgrupp (vilket är standardalternativet). Den här metoden hjälper till att förhindra att händelsehubben når gränsen för samtidiga läsare. Mer information om konsumentgrupper och om du bör välja en befintlig konsumentgrupp eller skapa en ny finns i Konsumentgrupper.
Om din händelsehubb är på basic-nivån kan du bara använda den befintliga $Default konsumentgruppen. Om din händelsehubb är på en Standard- eller Premium-nivå kan du skapa en ny konsumentgrupp.
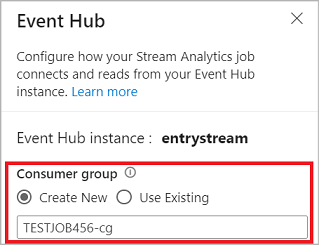
När du ansluter till händelsehubben och väljer Hanterad identitet som autentiseringsläge, beviljas rollen Azure Event Hubs dataägare till den hanterade identiteten för jobbet Stream Analytics. Mer information om hanterade identiteter för en händelsehubb finns i Använda hanterade identiteter för att komma åt en händelsehubb från ett Azure Stream Analytics-jobb.
Hanterade identiteter eliminerar begränsningarna för användarbaserade autentiseringsmetoder. Dessa begränsningar omfattar behovet av att autentisera igen på grund av lösenordsändringar eller förfallodatum för användartoken som inträffar var 90:e dag.
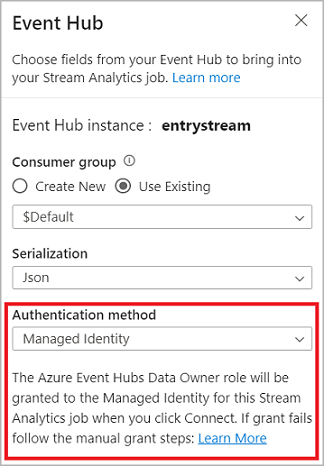
När du har konfigurerat händelsehubbens information och valt Anslut kan du lägga till fält manuellt med hjälp av + Lägg till fält om du känner till fältnamnen. Om du i stället vill identifiera fält och datatyper automatiskt baserat på ett exempel på inkommande meddelanden väljer du Identifiera fält automatiskt. Om du väljer kugghjulssymbolen kan du redigera autentiseringsuppgifterna om det behövs.
När Stream Analytics-jobb identifierar fälten visas de i listan. Du ser också en liveförhandsgranskning av inkommande meddelanden i tabellen Dataförhandsgranskning under diagramvyn.
Ändra indata
Du kan redigera fältnamnen, ta bort fält, ändra datatypen eller ändra händelsetiden (Markera som händelsetid: TIMESTAMP BY-sats om ett datetime-typfält) genom att välja trepunktssymbolen bredvid varje fält. Du kan också expandera, välja och redigera alla kapslade fält från inkommande meddelanden, enligt följande bild.
Tips
Den här processen gäller även för indata från Azure IoT Hub och Azure Data Lake Storage Gen2.

Tillgängliga datatyper är:
- DateTime: Datum- och tidsfält i ISO-format.
- Flyttal: Decimaltal.
- Int: Heltalsnummer.
- Record: Kapslat objekt med flera records.
- Sträng: Text.
Azure IoT Hub som ströminmatning
Azure IoT Hub är en hanterad tjänst i molnet som fungerar som en central meddelandehubb för kommunikation mellan ett IoT-program och dess anslutna enheter. Du kan använda IoT-enhetsdata som skickas till IoT Hub som indata för ett Stream Analytics-jobb.
Kommentar
Du kan använda Azure IoT Hub indata i redigeringsprogrammet utan kod på Azure Stream Analytics portalen.
Om du vill lägga till en IoT-hubb som strömmande indata för ditt jobb väljer du IoT Hub under Indata från menyfliksområdet. Fyll sedan i nödvändig information i den högra panelen för att ansluta IoT Hub till ditt jobb. Mer information om varje fält finns i Strömma data från IoT Hub till Stream Analytics-jobb.

Azure Data Lake Storage Gen2 som strömmande inmatning
Azure Data Lake Storage Gen2 (ADLS Gen2) är en molnbaserad datasjölösning för företag. Den är utformad för att lagra enorma mängder data i valfritt format och för att underlätta analysarbetsbelastningar för stordata. Stream Analytics kan bearbeta data som lagras i ADLS Gen2 som en dataström. Mer information om den här typen av indata finns i Strömma data från ADLS Gen2 till Stream Analytics-jobb.
Kommentar
Du kan använda Azure Data Lake Storage Gen2 indata i redigeringsprogrammet utan kod på Azure Stream Analytics portalen.
Om du vill lägga till en ADLS Gen2 som strömmande indata för ditt jobb väljer du ADLS Gen2 under Indata från menyfliksområdet. Fyll sedan i nödvändig information i den högra panelen för att ansluta ADLS Gen2 till ditt jobb. Mer information om varje fält finns i Strömma data från ADLS Gen2 till Stream Analytics-jobb.

Inmatningar av referensdata
Referensdata är statiska eller ändras långsamt över tid. Vanligtvis använder du den för att utöka inkommande strömmar och göra sökningar i ditt jobb. Du kan till exempel koppla indata från dataströmmar till referensdata, ungefär som du skulle utföra en SQL-koppling för att söka efter statiska värden. Mer information om referensdataindata finns i Använda referensdata för sökningar i Stream Analytics.
Redigeringsprogrammet utan kod stöder nu två referensdatakällor:
- Azure Data Lake Storage Gen2
- Azure SQL Database

Azure Data Lake Storage Gen2 som referensdata
Modellera referensdata som en sekvens av blobar i stigande ordning efter den datum- och tidskombination som anges i blobnamnet. Du kan bara lägga till blobar i slutet av sekvensen med hjälp av ett datum och en tid som är större än den som den sista bloben angav i sekvensen. Definiera blobar i indatakonfigurationen.
Välj först Referens ADLS Gen2 under avsnittet Indata i menyfliksområdet. Information om varje fält finns i avsnittet om Azure Blob Storage i Använda referensdata för sökningar i Stream Analytics.
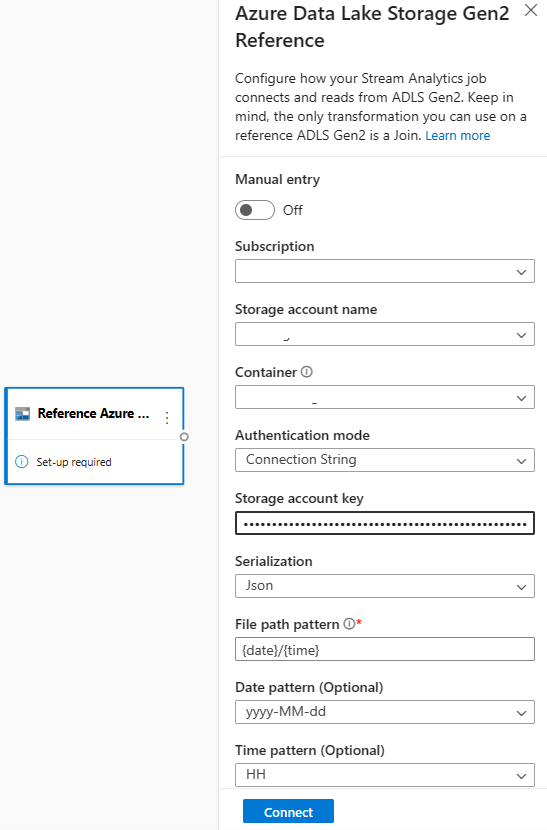
Ladda sedan upp en JSON-matrisfil. Systemet identifierar fälten. Använd dessa referensdata för att utföra transformering med strömmande indata från Event Hubs.

Azure SQL Database som referensdata
Du kan använda Azure SQL Database som referensdata för ditt Stream Analytics-jobb i redigeringsprogrammet utan kod. Mer information finns i avsnittet om SQL Database i Använda referensdata för sökningar i Stream Analytics.
Om du vill konfigurera SQL Database som referensdataindata väljer du Referens SQL Database under avsnittet Indata i menyfliksområdet. Fyll sedan i informationen för att ansluta referensdatabasen och välj tabellen med de kolumner som behövs. Du kan också hämta referensdata från tabellen genom att redigera SQL-frågan manuellt.

Transformeringar
Transformering av strömmande data skiljer sig i sig från batchdatatransformeringar. Nästan alla strömmande data har en tidskomponent som påverkar alla uppgifter för förberedelse av data.
Om du vill lägga till en transformering av strömmande data i jobbet väljer du transformeringssymbolen under avsnittet Åtgärder i menyfliksområdet för omvandlingen. Respektive panel läggs till i diagramvyn. När du har valt den visas sidofönstret för omvandlingen för att konfigurera den.

Filtrera
Använd filtertransformeringen för att filtrera händelser baserat på värdet för ett fält i indata. Beroende på datatypen (tal eller text) behåller omvandlingen de värden som matchar det valda villkoret.

Kommentar
I varje ruta ser du information om vad omvandlingen mer behöver för att vara klar. När du till exempel lägger till en ny panel visas ett meddelande om att installationen krävs . Om du saknar en nodanslutning visas antingen ett felmeddelande eller ett varningsmeddelande .
Hantera fält
Med transformering av hantera fält kan du lägga till, ta bort eller byta namn på fält som kommer in från en indata eller en annan transformering. Med inställningarna i sidofönstret kan du lägga till ett nytt fält genom att välja Lägg till fält eller lägga till alla fält samtidigt.

Du kan också lägga till ett nytt fält med hjälp av inbyggda funktioner för att aggregera data från uppströms. För närvarande stöds de inbyggda funktionerna i String Functions, Date and Time Functions och Mathematical Functions. Mer information om definitionerna av dessa funktioner finns i Inbyggda funktioner (Azure Stream Analytics).

Tips
När du har konfigurerat en panel får du en glimt av inställningarna i panelen i diagramvyn. I området Hantera fält i föregående bild kan du till exempel se de tre första fälten som hanteras och de nya namnen som tilldelats dem. Varje platta har information som är relevant för den.
Aggregera
Använd aggregeringstransformeringen för att beräkna en aggregering (Summa, Minimum, Maximum eller Average) varje gång en ny händelse inträffar under en tidsperiod. Med den här åtgärden kan du också filtrera eller segmentera aggregeringen baserat på andra dimensioner i dina data. Du kan inkludera en eller flera sammansättningar i samma transformering.
Om du vill lägga till en aggregering väljer du transformeringssymbolen. Anslut sedan indata, välj aggregering, lägg till eventuella filter- eller segmentdimensioner och välj den tidsperiod under vilken aggregeringen beräknas. I det här exemplet beräknar du summan av vägtullvärdet beroende på den delstat som fordonet kommer från under de senaste 10 sekunderna.

Om du vill lägga till ytterligare en aggregering i samma transformering väljer du Lägg till mängdfunktion. Filtret eller urvalet gäller för alla aggregeringar i omvandlingen.
Anslut
Använd kopplingstransformeringen för att kombinera händelser från två indata baserat på de fältpar som du väljer. Om du inte väljer ett fältpar baseras kopplingen som standard på tid. Standardvärdet är det som gör att den här omvandlingen skiljer sig från en batch.
Precis som med vanliga kopplingar har du alternativ för din kopplingslogik:
- Inre koppling: Inkludera endast poster från båda tabellerna där paret matchar. I det här exemplet matchar registreringsskylten båda indata.
- Vänster yttre koppling: Inkludera alla poster från den vänstra (första) tabellen och endast posterna från den andra som matchar fältparet. Om det inte finns någon matchning är fälten från den andra inmatningen tomma.
Välj typ av koppling genom att välja symbolen för önskad typ i sidofönstret.
Välj slutligen den period under vilken du vill att kopplingen ska beräknas. I det här exemplet tittar join-operationen på de senaste 10 sekunderna. Ju längre perioden är, desto mindre frekvent är utdata och ju fler bearbetningsresurser du använder för omvandlingen.
Som standard innehåller utdata alla fält från båda tabellerna. Prefix till vänster (första noden) och höger (andra noden) hjälper dig att särskilja källan.

Gruppera efter
Gruppera efter-transformering för att beräkna aggregeringar över alla händelser inom en viss tidsperiod. Du kan gruppera efter värden i ett eller flera fält. Det är som aggregeringstransformeringen men innehåller fler alternativ för aggregeringar. Den innehåller också mer komplexa alternativ för tidsfönster. Precis som aggregering kan du lägga till mer än en aggregering per transformering.
De aggregeringar som är tillgängliga i omvandlingen är:
- Genomsnitt
- Antal
- Maximal
- Minimal
- Percentil (kontinuerlig och diskret)
- Standardavvikelse
- Sum
- Varians
Så här konfigurerar du omvandlingen:
- Välj önskad sammansättning.
- Välj det fält som du vill aggregera på.
- Välj ett valfritt grupperingsfält om du vill hämta aggregeringsberäkningen över en annan dimension eller kategori. Till exempel: Tillstånd.
- Välj din funktion för tidsfönster.
Om du vill lägga till ytterligare en aggregering i samma transformering väljer du Lägg till mängdfunktion. Tänk på att fältet Gruppera efter och fönsterfunktionen gäller för alla aggregeringar i omvandlingen.

En tidsstämpel för slutet av tidsfönstret visas som en del av transformeringsutdata som referens. Mer information om tidsfönster som Stream Analytics-jobb stöder finns i Fönsterfunktioner (Azure Stream Analytics).
Union
Använd unionstransformeringen för att ansluta två eller flera indata. Lägg till händelser som har delade fält (med samma namn och datatyp) i en tabell. Utdata exkluderar fält som inte matchar.
Expandera array
Använd transformeringen Expandera matris för att skapa en ny rad för varje värde i en matris.

Strömmande utdata
Funktionen för kodfritt dra-och-släpp stöder för närvarande flera utdataslussar för att lagra bearbetade realtidsdata.

Azure Data Lake Storage Gen2
Data Lake Storage Gen2 gör Azure Storage till grunden för att skapa företagsdatasjöar i Azure. Den är utformad för att betjäna flera petabyte med information samtidigt som hundratals gigabit dataflöde bibehålls. Det gör att du enkelt kan hantera enorma mängder data. Azure Blob Storage erbjuder en kostnadseffektiv och skalbar lösning för lagring av stora mängder ostrukturerade data i molnet.
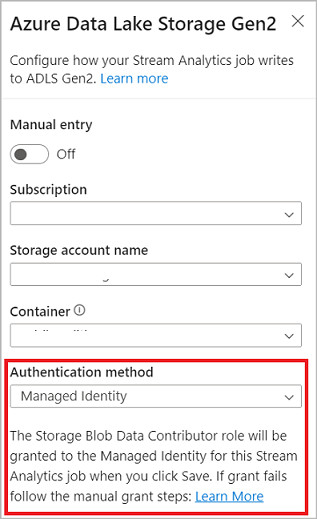
Under avsnittet Utdata i menyfliksområdet väljer du ADLS Gen2 som utdata för ditt Stream Analytics-jobb. Välj sedan den container där du vill skicka utdata för jobbet. Mer information om Azure Data Lake Gen2-utdata för ett Stream Analytics-jobb finns i Blob Storage- och Azure Data Lake Gen2-utdata från Azure Stream Analytics.
Om du ansluter till Azure Data Lake Storage Gen2, om du väljer Hanterad identitet som autentiseringsläge, beviljas rollen Storage Blob Data Contributor till den hanterade identiteten för Stream Analytics-jobbet. Mer information om hanterade identiteter för Azure Data Lake Storage Gen2 finns i Använda hanterade identiteter för att autentisera ditt Azure Stream Analytics-jobb till Azure Blob Storage.
Hanterade identiteter eliminerar begränsningarna för användarbaserade autentiseringsmetoder. Dessa begränsningar omfattar behovet av att autentisera igen på grund av lösenordsändringar eller förfallodatum för användartoken som inträffar var 90:e dag.
Exakt en gång-leverans (förhandsversion) stöds i ADLS Gen2 utan kodredigerarens utdata. Du kan aktivera den i avsnittet Skrivläge i ADLS Gen2-konfigurationen. Mer information om den här funktionen finns i Exactly once delivery (förhandsversion) i Azure Data Lake Gen2.

Skriv till Delta Lake-tabellen (förhandsversion) stöds i ADLS Gen2 eftersom det inte finns några utdata från kodredigeraren. Du kan komma åt det här alternativet i avsnittet Serialisering i ADLS Gen2-konfiguration. Mer information om den här funktionen finns i Skriv till Delta Lake-tabell.

Azure Synapse Analytics
Azure Stream Analytics-jobb kan skicka utdata till en dedikerad SQL-pooltabell i Azure Synapse Analytics och kan bearbeta dataflödeshastigheter på upp till 200 MB per sekund. Stream Analytics har stöd för de mest krävande realtidsanalys- och snabbdatabearbetningsbehoven för arbetsbelastningar som rapportering och dashboards.
Viktigt!
Den dedikerade SQL-pooltabellen måste finnas innan du kan lägga till den som utdata till ditt Stream Analytics-jobb. Tabellens schema måste matcha fälten och deras typer i jobbets utdata.
Under avsnittet Utdata i menyfliksområdet väljer du Synapse som utdata för ditt Stream Analytics-jobb. Välj sedan den SQL-pooltabell där du vill skicka utdata för jobbet. Mer information om Azure Synapse-utdata för ett Stream Analytics-jobb finns i Azure Synapse Analytics-utdata från Azure Stream Analytics.
Azure Cosmos DB
Azure Cosmos DB är en globalt distribuerad databastjänst som erbjuder obegränsad elastisk skalning över hela världen. Den erbjuder även omfattande frågor och automatisk indexering över schemaagnostiska datamodeller.
Under avsnittet Utdata i menyfliksområdet väljer du CosmosDB som utdata för ditt Stream Analytics-jobb. Mer information om Azure Cosmos DB-utdata för ett Stream Analytics-jobb finns i Azure Cosmos DB-utdata från Azure Stream Analytics.
När du ansluter till Azure Cosmos DB och väljer Hanterad identitet som autentiseringsläge, beviljas Deltagarrollen till den hanterade identiteten för Stream Analytics-jobbet. Mer information om hanterade identiteter för Azure Cosmos DB finns i Använda hanterade identiteter för att komma åt Azure Cosmos DB från ett Azure Stream Analytics-jobb (förhandsversion).
Azure Cosmos DB-utdata i redigeringsprogrammet utan kod stöder också autentiseringsmetoden för hanterade identiteter. Den här metoden ger samma fördelar som i ADLS Gen2-utdata.
Azure SQL Database
Azure SQL Database är en fullständigt hanterad paaS-databasmotor (plattform som en tjänst) som hjälper dig att skapa ett datalagringslager med hög tillgänglighet och höga prestanda för program och lösningar i Azure. Genom att använda redigeringsprogrammet utan kod kan du konfigurera Azure Stream Analytics-jobb för att skriva bearbetade data till en befintlig tabell i SQL Database.
Om du vill konfigurera Azure SQL Database som utdata väljer du SQL Database under avsnittet Utdata i menyfliksområdet. Ange sedan den information som behövs för att ansluta till SQL-databasen och välj den tabell som du vill skriva data till.
Viktigt!
Azure SQL Database-tabellen måste finnas innan du kan lägga till den som utdata till ditt Stream Analytics-jobb. Tabellens schema måste matcha fälten och deras typer i jobbets utdata.
Mer information om Azure SQL Database-utdata för ett Stream Analytics-jobb finns i Azure SQL Database-utdata från Azure Stream Analytics.
Event Hubs
Med realtidsdata som kommer till ASA kan redigeringsprogrammet utan kod transformera och utöka data och sedan mata ut data till en annan händelsehubb. Du kan välja Event Hubs-utdata när du konfigurerar ditt Azure Stream Analytics-jobb.
Om du vill konfigurera Event Hubs som utdata väljer du Händelsehubb under avsnittet Utdata i menyfliksområdet. Ange sedan den information som behövs för att ansluta till din händelsehubb som du vill skriva data till.
Mer information om Event Hubs-utdata för ett Stream Analytics-jobb finns i Event Hubs-utdata från Azure Stream Analytics.
Öppna Azure-datautforskaren
Azure Data Explorer är en fullständigt hanterad stordataanalysplattform med höga prestanda som gör det enkelt att analysera stora mängder data. Du kan också använda Azure Data Explorer som utdata för ditt Azure Stream Analytics jobb med hjälp av redigeringsprogrammet utan kod.
Om du vill konfigurera Azure Data Explorer som utdata väljer du avsnittet Azure Data Explorer under avsnittet Outputs i menyfliksområdet. Ange sedan den information som krävs för att ansluta till din Azure Data Explorer databas och ange den tabell som du vill skriva data till.
Viktigt!
Tabellen måste finnas i den valda databasen och tabellens schema måste exakt matcha fälten och deras typer i jobbets utdata.
Mer information om Azure Data Explorer-utdata för ett Stream Analytics-jobb finns i Azure Data Explorer-utdata från Azure Stream Analytics (förhandsversion).
Power BI
Power BI erbjuder en omfattande visualiseringsupplevelse för dataanalysresultatet. Genom att använda Stream Analytics-utdata till Power BI skrivs den bearbetade strömmande datan till en Power BI-strömmande datauppsättning, och sedan kan du använda den för att bygga en Power BI-nära realtidsinstrumentpanel.
Om du vill konfigurera Power BI som utdata väljer du Power BI under avsnittet Outputs i menyfliksområdet. Ange sedan den information som krävs för att ansluta till din Power BI arbetsyta och ange namnen på den strömmande datauppsättningen och tabellen som du vill skriva data till. Mer information om varje fält finns i Power BI-utdata från Azure Stream Analytics.
Dataförhandsgranskning, redigeringsfel, körningsloggar och mått
Funktionen dra och släpp utan kod innehåller verktyg som hjälper dig att skapa, felsöka och utvärdera prestanda för din analyspipeline för strömmande data.
Förhandsversion av livedata för indata
När du ansluter till en indatakälla, till exempel en händelsehubb, och väljer dess panel i diagramvyn (fliken Dataförhandsgranskning ) visas en liveförhandsgranskning av inkommande data om alla följande villkor är sanna:
- Data skickas.
- Indata är korrekt konfigurerade.
- Fält läggs till.
Som du ser i följande skärmbild kan du pausa förhandsgranskningen (1) om du vill se eller öka detaljnivån i något specifikt. Eller så kan du starta den igen om du är klar.
Du kan också se information om en specifik post, en cell i tabellen, genom att välja den och sedan välja Visa/dölj information (2). Skärmbilden visar en detaljerad vy av ett kapslat objekt i en post.

Statisk förhandsgranskning för omvandlingar och utdata
När du har lagt till och konfigurerat några steg i diagramvyn kan du testa deras beteende genom att välja Hämta statisk förhandsversion.

När du väljer knappen utvärderar Stream Analytics-jobbet alla transformeringar och utdata för att se till att de är korrekt konfigurerade. Stream Analytics visar sedan resultatet i förhandsversionen av statiska data, enligt följande bild.

Du kan uppdatera förhandsversionen genom att välja Uppdatera statisk förhandsversion (1). När du uppdaterar förhandsversionen tar Stream Analytics-jobbet nya data från indata och utvärderar alla transformeringar. Sedan skickas utdata igen med alla uppdateringar som du kan ha utfört. Alternativet Visa/dölj information är också tillgängligt (2).
Författarfel
Om du har några redigeringsfel eller varningar visar fliken Redigeringsfel dem, enligt följande skärmbild. Listan innehåller information om felet eller varningen, typen av kort (indata, transformering eller utdata), felnivån och en beskrivning av felet eller varningen.

Körningsloggar
När ett jobb körs visas körningsloggar på varnings-, fel- eller informationsnivå. Dessa loggar är användbara när du vill redigera stream analytics-jobbtopologin eller konfigurationen för felsökning. Aktivera diagnostikloggar och skicka dem till Log Analytics arbetsyta i Settings för att få mer insikter om dina jobb som körs för felsökning.

I följande skärmbildsexempel konfigurerar användaren SQL Database-utdata med ett tabellschema som inte matchar fälten i jobbutdata.

Mått
Om jobbet körs kan du övervaka hälsotillståndet för ditt jobb på fliken Mätvärden. De fyra mätvärden som visas som standard är vattenstämpelsfördröjning, indatahändelser, uppdämda indatahändelser och utdatahändelser. Använd dessa mått för att förstå om händelserna flödar in och ut ur jobbet utan några kvarvarande indata.

Du kan välja fler mått i listan. För att förstå alla mätvärden i detalj, se Azure Stream Analytics-jobbmått.
Starta ett Stream Analytics-jobb
Du kan spara jobbet när som helst när du skapar det. När du har konfigurerat strömmande indata, transformeringar och strömmande utdata för jobbet kan du starta jobbet.
Kommentar
Även om redigeringsprogrammet utan kod på Azure Stream Analytics-portalen är i förhandsversion är Azure Stream Analytics-tjänsten allmänt tillgänglig.

Du kan konfigurera följande alternativ:
-
Starttid för utdata: När du startar ett jobb väljer du en tid för jobbet att börja skapa utdata.
- Nu: Det här alternativet gör startpunkten för utdatahändelseströmmen på samma sätt som när jobbet startar.
- Anpassad: Välj startpunkten för utdata.
- När det senast stoppades: Det här alternativet är tillgängligt när jobbet startades tidigare men stoppades manuellt eller misslyckades. När du väljer det här alternativet används den senaste utdatatiden för att starta om jobbet, så inga data går förlorade.
- Strömningsenheter: Strömningsenheter (SUs) representerar mängden beräkning och minne som tilldelats jobbet medan det körs. Om du inte är säker på hur många SUS:er du ska välja börjar du med tre och justerar efter behov.
- Hantering av utdatafel: Principer för hantering av utdatafel gäller endast när utdatahändelsen som skapas av ett Stream Analytics-jobb inte överensstämmer med schemat för målmottagaren. Konfigurera principen genom att välja Antingen Försök igen eller Släpp. Se utdatafelpolicy för Azure Stream Analytics för mer information.
- Start: Den här knappen startar Stream Analytics-jobbet.

Stream Analytics-jobblista i Azure Event Hubs-portalen
Om du vill se en lista över alla Stream Analytics-jobb som du skapade med hjälp av dra och släpp-funktionen utan kod i Azure Event Hubs-portalen väljer du Bearbeta data>Stream Analytics-jobb.

Här är elementen på fliken Stream Analytics-jobb :
- Filter: Filtrera listan efter jobbnamn.
- Uppdatering: För närvarande uppdateras inte själva listan automatiskt. Använd knappen Uppdatera för att uppdatera listan och se den senaste statusen.
- Jobbnamn: Namnet i det här området är det som du anger i det första steget när du skapar jobb. Du kan inte redigera den. Välj jobbnamnet för att öppna jobbet i dra och släpp-funktionen utan kod, där du kan stoppa jobbet, redigera det och starta det igen.
- Status: Det här området visar jobbets status. Välj Uppdatera överst i listan för att se den senaste statusen.
- Strömningsenheter: Det här området visar antalet enheter för direktuppspelning som du väljer när du startar jobbet.
- Utdatavattenstämpel: Det här området ger en indikator på livlighet för de data som jobbet producerar. Alla händelser före tidsstämpeln beräknas redan.
- Jobbövervakning: Välj Öppna mått för att se de mått som är relaterade till det här Stream Analytics-jobbet. Mer information om de mått som du kan använda för att övervaka ditt Stream Analytics-jobb finns i Azure Stream Analytics-jobbmått.
- Åtgärder: Starta, stoppa eller ta bort jobbet.
Nästa steg
Lär dig hur du använder redigeringsprogrammet utan kod för att hantera vanliga scenarier med hjälp av fördefinierade mallar: