Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Este artigo explica como alterar a versão do modelo e as definições no construtor de prompts. A versão do modelo e as definições podem afetar o desempenho e o comportamento do modelo de IA generativa.
Seleção de Modelo
Você pode alterar o modelo selecionando Modelo na parte superior do construtor de prompts. O menu pendente permite-lhe selecionar entre os modelos de IA generativa que geram respostas ao seu pedido personalizado.
Usar prompts em Power Apps ou Power Automate consome créditos de criação de prompts, enquanto usar prompts em Copilot Studio consome créditos do Copilot. Saiba mais em Licenciamento e créditos de gerador de prompts na documentação do AI Builder.
Visão geral
A tabela seguinte descreve os diferentes modelos disponíveis.
Os modelos têm diferentes disponibilidades entre regiões e são periodicamente atualizados. Saiba mais em Disponibilidade de modelos por região e atualizações do Prompt.
Nota
- O GPT-4o mini e o GPT-4o continuam a ser usados em regiões governamentais dos EUA. Estes modelos seguem as regras de licenciamento e oferecem funcionalidades comparáveis ao GPT-4.1 mini e GPT-4.1, respetivamente.
- Os modelos Anthropic são alojados fora da Microsoft e estão sujeitos aos termos e à gestão de dados da Anthropic. Saiba mais em Escolha um modelo externo como modelo principal de IA.
| Modelo GPT | Licenciamento | Funcionalidades | Categoria |
|---|---|---|---|
| GPT-4.1 mini (modelo padrão) | Taxa básica | Preparado com dados até junho de 2024. Introduza até 128K tokens. | Mini |
| GPT-4.1 | Taxa padrão | Preparado com dados até junho de 2024. O contexto suporta até 128 milhares de tokens. | Geral |
| Bate-papo GPT-5 | Taxa padrão | Treinado com dados até setembro de 2024. O contexto suporta até 128 milhares de tokens. | Geral |
| Raciocínio GPT-5 | Tarifa premium | Treinado com dados até setembro de 2024. O contexto permite até 400 mil tokens. | Profundo |
| Raciocínio GPT-5.2 | Tarifa premium | Preparado com dados até outubro de 2024. O contexto permite até 400 mil tokens. | Profundo |
| Chat GPT-5.3 | Taxa padrão | Modelo gerido. O contexto suporta até 128 milhares de tokens. | Geral |
| Claude Soneto 4.6 | Taxa padrão | Modelo externo da Anthropic. Contexto permitido até 200 mil tokens. | Geral |
| Claude Opus 4.6 | Tarifa premium | Modelo externo da Anthropic. Contexto permitido até 200 mil tokens. | Profundo |
| Grok 4.1 Rápido (Sem raciocínio) (consulte a nota importante abaixo) | Taxa padrão | Modelo externo do xAI. | Geral |
Importante
As avaliações de segurança e IA responsável da Microsoft concluíram que o Grok-4.1 Rápido (Não Raciocínio) estava menos alinhado do que outros modelos avaliados, resultando em (i) maiores riscos de que o modelo produza conteúdo potencialmente prejudicial e (ii) pontuações mais baixas nos benchmarks de segurança e jailbreak. O Grok-4.1 Fast (Non-Reasoning) pode produzir conteúdo explícito, e tem uma maior propensão para fazê-lo do que outros modelos. Os clientes devem cumprir tanto o Código de Conduta dos Serviços Empresariais de IA da Microsoft como os Termos de Serviço Empresariais da xAI, incluindo a Política de Uso Aceitável. Além disso, podem existir categorias de danos que este modelo pode causar que não estão abrangidas pelos sistemas de segurança de conteúdos da Microsoft. Assim, como em todos os modelos experimentais, o Grok-4.1 Rápido (Não Raciocínio) não é recomendado para uso em produção e os clientes devem rever as Limitações dos modelos experimentais e de pré-visualização e realizar as suas próprias avaliações antes de escolher o Grok-4.1 Rápido (Não Raciocínio).
Licenciamento
Em agentes, fluxos ou aplicações, os prompts que usam modelos consomem Créditos do Copilot, independentemente da fase de lançamento em que os modelos se encontrem. Saiba mais sobre Faturação de tarifas e gestão.
Se tiver créditos AI Builder, o sistema consome-os primeiro quando os prompts são usados no Power Apps e no Power Automate. Quando são usados prompts no Copilot Studio, o sistema não consome créditos do AI Builder. Saiba mais em Visão geral de licenciamento na documentação AI Builder.
Fases de lançamento
Os modelos passam por diferentes fases de lançamento. Pode experimentar novos modelos experimentais e de pré-visualização inovadores, ou escolher um modelo fiável e amplamente testado e disponível.
| Etiqueta | Descrição |
|---|---|
| Experimental | Destinado à experimentação, e não à produção. Sujeito a termos de pré-visualização, pode ter limitações de disponibilidade e qualidade. |
| Pré-visualização | Eventualmente torna-se um modelo de disponibilidade geral, mas atualmente não é recomendado para utilização em produção. Sujeito a termos de pré-visualização, pode ter limitações de disponibilidade e qualidade. |
| Sem etiqueta | Disponibilidade geral. Pode utilizar este modelo para utilização em escala e em produção. Na maioria dos casos, os modelos com disponibilidade geral não têm limitações de disponibilidade e qualidade, mas alguns ainda podem ter algumas limitações, como a disponibilidade regional. Importante: Os modelos Claude da Anthropic estão na fase experimental, apesar de não apresentarem uma etiqueta. |
| Predefinição | O modelo predefinido para todos os agentes e, normalmente, o modelo de melhor desempenho com disponibilidade geral. O modelo predefinido é atualizado periodicamente à medida que novos modelos mais capazes ficam em disponibilidade geral. Os agentes também utilizam o modelo predefinido como uma contingência se um modelo selecionado estiver desligado ou indisponível. |
Modelos experimentais e de pré-visualização podem mostrar variabilidade no desempenho, qualidade da resposta, latência ou consumo de mensagens. Podem exceder o limite de tempo ou estar indisponíveis. Estão sujeitos a termos de pré-visualização.
Categorização
A tabela seguinte descreve as diferentes categorias de modelos.
| Categoria | Mini | Geral | Profundo |
|---|---|---|---|
| Desempenho | Bom para a maioria das tarefas | Superior para tarefas complexas | Treinados para tarefas de raciocínio |
| Velocidade | Processamento mais rápido | Pode ser mais lento devido à complexidade | Mais lento, uma vez que raciocina antes de responder |
| Casos de uso | Resumos, tarefas de informações, imagem e processamento de documentos | Processamento de documentos e imagens, tarefas avançadas de criação de conteúdos | Tarefas de análise de dados e raciocínio, processamento de documentos e imagens |
Escolha um mini modelo quando precisar de uma solução económica para tarefas moderadamente complexas, tiver recursos computacionais limitados ou exigir processamento mais rápido. Os mini modelos são ideais para projetos com restrições orçamentais e aplicações como apoio ao cliente ou análise eficiente de código.
Escolha um modelo geral quando estiver a lidar com tarefas altamente complexas e multimodais que exigem desempenho superior e análise detalhada. É a melhor escolha para projetos de grande escala onde a precisão e as capacidades avançadas são cruciais. Um modelo geral também é uma boa escolha quando tem orçamento e recursos computacionais para o suportar. Os modelos gerais são também preferíveis para projetos de longo prazo que podem aumentar em complexidade ao longo do tempo.
Os modelos profundos destacam-se para projetos que requerem capacidades avançadas de raciocínio. São adequadas para cenários que exigem resolução sofisticada de problemas e pensamento crítico. Os modelos Profundos destacam-se em ambientes onde o raciocínio com nuances, a tomada de decisões complexas e a análise detalhada são importantes.
Escolha entre os modelos com base na disponibilidade da região, funcionalidades, casos de uso e custos. Saiba quais os modelos disponíveis na sua região e os calendários de reforma dos modelos em disponibilidade de modelos por região e atualizações. Saiba mais sobre preços na Tabela de Taxas de Capacidades AI Builder.
Definições do modelo
Pode aceder ao painel de definições selecionando os três pontos (...) >Definições no topo do criador de prompts. Também pode alterar as seguintes definições:
- Temperatura: temperaturas mais baixas conduzem a resultados previsíveis. Temperaturas mais elevadas permitem respostas mais diversas ou criativas.
- Recuperação de registos: O número de registos recuperados para as suas origens de conhecimento.
- Incluir ligações na resposta: quando selecionada, a resposta inclui citações de ligação para o registos obtidos.
- Ativar interpretador de código: Quando selecionado, o interpretador de código para gerar e executar código está ativado.
- Nível de moderação de conteúdo: O nível mais baixo gera mais respostas, mas pode conter conteúdo prejudicial. O nível mais elevado de moderação de conteúdo aplica um filtro mais rigoroso para restringir conteúdos prejudiciais e gera menos respostas.
Temperatura
Defina a temperatura para o modelo de IA generativa usando o slider. Varia entre 0 e 1. Este valor orienta o modelo de IA generativa sobre a quantidade de criatividade (1) vs. resposta determinística (0) que fornece.
Nota
A definição de temperatura não está disponível para o modelo de raciocínio GPT-5. Por este motivo, a barra deslizante é desativada quando se seleciona o modelo de raciocínio GPT-5.
A temperatura é um parâmetro que controla a aleatoriedade da saída gerada pelo modelo de IA. Uma temperatura mais baixa resulta em saídas mais previsíveis e conservadoras. Em comparação, uma temperatura mais elevada permite mais criatividade e diversidade nas respostas. É uma forma de afinar o equilíbrio entre aleatoriedade e determinismo na saída do modelo.
Por predefinição, a temperatura é 0, como nos pedidos criados anteriormente.
| Temperatura | Caraterística | Utilizar no |
|---|---|---|
| 0 | Resultados mais previsíveis e conservadores. As respostas são mais consistentes. |
Pedidos que exigem alta precisão e menor variabilidade. |
| 1 | Mais criatividade e diversidade nas respostas. Respostas mais variadas e, por vezes, mais inovadoras. |
Pedidos que criam novo conteúdo pronto a utilizar. |
Ajustar a temperatura pode influenciar a saída do modelo, mas não garante um resultado específico. As respostas da IA são probabilísticas de forma inerente e podem variar com a mesma definição de temperatura.
Nível de moderação de conteúdos
Defina o nível de moderação de conteúdo para o prompt usando o slider. Com um nível de moderação mais baixo, o seu prompt pode fornecer mais respostas. No entanto, o aumento das respostas pode afetar a permissão de conteúdo nocivo (ódio e equidade, conteúdo sexual, violência, automutilação) provenientes do pedido.
Nota
A definição de nível de moderação de conteúdo está disponível apenas para modelos geridos. Por esta razão, o slider não está disponível quando seleciona modelos Anthropic ou Azure AI Foundry.
Os níveis de moderação variam de Baixo a Alto. O nível padrão de moderação para prompts é Moderado.
A menor moderação aumenta o risco de conteúdo prejudicial nas respostas geradas pelo seu prompt. Uma moderação mais elevada reduz esse risco, mas pode diminuir o número de respostas.
| Nível de moderação de conteúdos | Descrição | Sugestão de utilização |
|---|---|---|
| Low | Pode permitir conteúdo de ódio e equidade, sexual, violência ou automutilação que apresente instruções, ações, danos ou abusos explícitos e graves. Inclui endosso, glorificação ou promoção de atos graves e prejudiciais, formas extremas ou ilegais de dano, radicalização ou troca ou abuso de poder não consensual. | Usado para pedidos que processam dados que podem ser considerados conteúdo nocivo (por exemplo, descrições de violência ou procedimentos médicos). |
| Moderado | Pode permitir conteúdo de ódio e justiça, sexual, violência ou automutilação que utilize linguagem ofensiva, insultuosa, zombeteira, intimidante ou depreciativa dirigida a grupos de identidade específicos. Inclui representações de procura e execução de instruções prejudiciais, fantasias, glorificação e promoção de danos de intensidade média. | Filtro padrão. Adequado para a maioria dos usos. |
| High | Pode permitir conteúdo de ódio e justiça, sexual, violência ou automutilação que expresse opiniões preconceituosas, julgadoras ou opinativas. Inclui uso ofensivo da linguagem, estereótipos, casos de uso que exploram um mundo fictício (por exemplo, jogos, literatura) e representações de baixa intensidade. | Usa, se precisares de mais filtragem, mais restritiva do que o nível Moderado. |
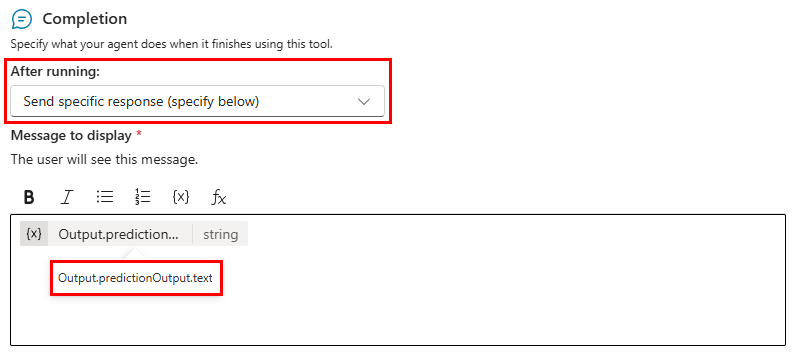
Para substituir a definição de moderação de conteúdo do agente ao usar o prompt num agente, defina a opção Após a execução no ecrã Conclusão da ferramenta de prompt para Enviar resposta específica (especificar abaixo). A Mensagem a mostrar deve conter a variável personalizada Output.predictionOutput.text .