Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Importante
O Autoscaling do Lakebase é a versão mais recente do Lakebase, com computação autoescalável, escala até zero, ramificação e restauração instantânea. Para regiões suportadas, consulte Disponibilidade de Regiões. Se é utilizador do Lakebase Provisioned, consulte Lakebase Provisioned.
Um compute é um serviço virtualizado que executa o Postgres para os seus projetos Lakebase. Cada filial tem uma unidade de computação primária (leitura-escrita). É necessário um computador para se ligar a uma sucursal e aceder aos seus dados. Para uma visão geral de como os cálculos e os endpoints se relacionam, veja Computes and endpoints.
Compreensão dos cálculos
Visão geral da computação
Os recursos de computação fornecem o poder de processamento e a memória necessários para executar consultas, gerir ligações e gerir operações de base de dados. Cada projeto tem um cálculo primário de leitura-escrita para o seu ramo predefinido.
Para se ligar a uma base de dados num ramo, deve usar um cálculo associado a esse ramo. Cálculos maiores consomem mais horas de cálculo no mesmo período de tempo ativo do que cálculos mais pequenos.
Identificadores de computação
Cada cálculo tem três identificadores, acessíveis a partir do menu Obter ID no separador Computes:
| Identificador | Fonte | Exemplo | Usado em |
|---|---|---|---|
| Nome | O ID do endpoint, definido como primary para a computação padrão. Fornecido pelo utilizador ao criar endpoints através da API. |
primary |
Caminho de recurso API (.../endpoints/primary) |
| UID | Gerado pelo sistema | ep-sweet-butterfly-y2nm75e1 |
Nome de host de ligação |
| Nome do recurso | Caminho completo da API | projects/my-project/branches/production/endpoints/primary |
Chamadas de API |
O nome de host na tua cadeia de ligação usa o UID, não o nome da computação.
Dimensionamento computacional
Tamanhos de computação disponíveis
O Lakebase Postgres suporta os seguintes tamanhos de cálculo:
- Autoscale calcula: 0,5 UC a 32 UC (0,5, depois incrementos inteiros: 1 UC, 2 UC, 3 UC... 16 UC, depois 24 UC, 28 UC, 32 UC)
- Unidades de Cálculo de tamanho fixo maiores: 36 CU a 112 CU (36, 40, 44, 48, 52, 56, 60, 64, 72, 80, 88, 96, 104, 112)
O que há numa unidade de computação?
Cada Unidade de Computação () aloca aproximadamente 2 GB de RAM à instância da base de dados, juntamente com todos os recursos associados da CPU e SSD local. A ampliação aumenta esses recursos linearmente. O Postgres distribui a memória alocada em vários componentes:
- Caches de banco de dados
- Memória do trabalhador
- Outros processos com requisitos de memória fixa
O desempenho varia com base no tamanho dos dados e na complexidade da consulta. Antes de escalar, teste e otimize as consultas. O armazenamento é dimensionado automaticamente.
Observação
Lakebase Provisionado vs Autoescalonamento: No Lakebase Provisionado, cada Unidade de Computação alocava aproximadamente 16 GB de RAM. No Lakebase Autoscaling, cada CU aloca 2 GB de RAM. Esta alteração oferece opções de escalabilidade mais granulares e controlo de custos.
Especificações de computação
| Unidades de computação | RAM | Máximo de Ligações |
|---|---|---|
| 0,5 CU | Aproximadamente 1 GB | 104 |
| 1 UC | cerca de 2 GB | 209 |
| 2 Unidades de Computação | ~4 GB | 419 |
| 3 Unidades de Carga | ~6 GB | 629 |
| 4 UC | ~8 GB | 839 |
| 5 UC | ~10 GB | 1049 |
| 6 Unidades de Crédito | ~12 GB | 1258 |
| 7 CU | ~14 GB | 1468 |
| 8 UCs | ~16 GB | 1678 |
| 9 UC | ~18 GB | 1888 |
| 10 CU | ~20 GB | 2098 |
| 12 unidades computacionais (if "CU" stands for Computational Units). | ~24 GB | 2517 |
| 14 UC | ~28 GB | 2937 |
| 16 UCs (Unidades de Cálculo) | ~32 GB | 3357 |
| 24 CU | ~48 GB | 4000 |
| 28 CU | ~56 GB | 4000 |
| 32 Unidades de Cálculo | ~64 GB | 4000 |
| 36 CU | ~72 GB | 4000 |
| 40 UCs | ~80 GB | 4000 |
| 44 CU | ~88 GB | 4000 |
| 48 Unidade de Computação | ~96 GB | 4000 |
| 52 CU | ~104 GB | 4000 |
| 56 UC | ~112 GB | 4000 |
| 60 UCs | ~120 GB | 4000 |
| 64 Unidades de Computação | ~128 GB | 4000 |
| 72 CU | ~144 GB | 4000 |
| 80 UC | ~160 GB | 4000 |
| 88 CU | ~176 GB | 4000 |
| 96 Unidades de Cálculo | ~192 GB | 4000 |
| 104 Unidades de Cálculo (CU) | ~208 GB | 4000 |
| 112 CU | ~224 GB | 4000 |
Limites de ligação para computação de autoescalonamento: Quando o autoescalonamento está ativado, o número máximo de ligações é determinado pelo tamanho máximo de unidade de computação (CU) na sua faixa de autoescalonamento. Por exemplo, se configurarem o autoscaling entre 2 CU até 8 CU, o teu limite de ligação é 1.678 (o limite para 8 CU).
Limites de ligação de réplicas de leitura: Limites de conexões de computação das réplicas de leitura são sincronizados com as suas definições de computação de leitura e escrita principais. Consulte a seção Gerir réplicas de leitura para mais detalhes.
Observação
Algumas conexões são reservadas para uso do sistema e uso administrativo. Por esta razão, SHOW max_connections pode mostrar um valor superior ao valor de Ligações Máximas mostrado na tabela acima ou na gaveta Editar cálculo na aplicação Lakebase. Os valores na tabela e na gaveta refletem o número real de conexões disponíveis para uso direto, enquanto SHOW max_connections inclui conexões reservadas.
Orientação de dimensionamento
Ao selecionar um tamanho de computação, considere estes fatores:
| Fator | Recommendation |
|---|---|
| Complexidade de consulta | Consultas analíticas complexas beneficiam de tamanhos de computação maiores |
| Ligações concorrentes | Mais ligações requerem CPU e memória adicionais |
| Volume de dados | Conjuntos de dados maiores podem precisar de mais memória para um desempenho ótimo |
| Tempo de resposta | Aplicações críticas podem exigir cálculos maiores para um desempenho consistente |
Estratégia de dimensionamento ótima
Selecione um tamanho de computação com base nos seus requisitos de dados:
- Conjunto de dados completo na memória: Escolha um tamanho de computação que consiga armazenar todo o seu conjunto de dados em memória para melhor desempenho
- Conjunto de trabalho na memória: Para grandes conjuntos de dados, assegure que os seus dados frequentemente acedidos cabem na memória
- Limites de ligação: Selecione um tamanho que suporte as suas ligações máximas concorrentes previstas
Autoescalonamento
O Lakebase suporta tanto configurações de computação de tamanho fixo como de autoescalonamento. O autoscaling ajusta dinamicamente os recursos computacionais com base na procura da carga de trabalho, otimizando tanto o desempenho como o custo.
| Tipo de Configuração | Description |
|---|---|
| Tamanho fixo (0,5-32 CU) | Selecione um tamanho de computação fixo que não escale com a procura de carga de trabalho. Disponível para unidades de computação de 0,5 UC a 32 UC |
| Autoscaling (0,5-32 CU) | Use um deslizador para especificar os tamanhos mínimos e máximos de computação. A Lakebase escala para cima e para baixo dentro destes limites com base na carga atual. Disponível para computações até 32 Unidades de Cálculo |
| Recursos de computação de tamanho fixo maiores (36-112 CU) | Selecione uma opção de computação de tamanho fixo maior, de 36 CU a 112 CU. Estes sistemas de computação maiores estão disponíveis apenas em tamanhos fixos e não suportam autoscaling. |
Limite de autoescalonamento: O autoescalonamento é suportado para unidades de computação até 32 CUs. Para cargas de trabalho que requerem mais de 32 CU, estão disponíveis unidades de computação de tamanho fixo maiores, de 36 CU a 112 CU.
Configuração do autoescalonamento
Para ativar ou ajustar o autoscaling para um cálculo, edite o cálculo e use o slider para definir os tamanhos mínimos e máximos de computação.

Para uma visão geral de como funciona o autoscaling, veja Autoscaling.
Considerações sobre o autoescalonamento
Para um desempenho ótimo de dimensionamento automático:
- Defina o seu tamanho mínimo de computação suficientemente grande para armazenar em cache o seu conjunto de trabalho na memória
- Considere que o baixo desempenho pode ocorrer até que o cálculo escale e armazene os seus dados em cache
- Os teus limites de ligação baseiam-se no tamanho máximo de computação na tua faixa de autoescalonamento
Restrições de alcance de autoescalonamento: A diferença entre os seus tamanhos máximo e mínimo de computação não pode exceder 16 CU (isto é, max - min ≤ 16 CU). Por exemplo, podes configurar o autoscaling de 8 CU para 24 CU, ou de 16 CU para 32 CU, mas não de 0,5 CU para 32 CU (que seria um intervalo de 31,5 CU). Esta restrição garante um comportamento de escalabilidade gerível, mantendo ao mesmo tempo flexibilidade. O slider na aplicação Lakebase aplica automaticamente esta restrição quando configura o seu intervalo de autoescalonamento. Para cargas de trabalho que requerem mais de 32 CUs, utilize unidades de computação de tamanho fixo maiores.
Reduzir para zero
A funcionalidade de escala para zero do Lakebase faz automaticamente a transição de um cálculo para um estado de inatividade após um período de inatividade, reduzindo custos para bases de dados que não estão continuamente ativas.
| Configuração | Description |
|---|---|
| Escalar para zero ativado | Compute suspende-se automaticamente após a inatividade para reduzir custos |
| Escalamento para zero desativado | Mantenha um cálculo "sempre ativo" que elimine a latência de arranque |
Configurar escala para zero
Para ativar ou ajustar a escala para zero num cálculo, edite o cálculo e alterne a definição de escala para zero. Quando ativado, pode configurar o tempo limite de inatividade.

Observação
Quando se cria um projeto, o ramo production é criado com uma instância de computação que tem o scale-to-zero desativado por defeito, o que significa que a instância de computação permanece sempre ativa. Pode ativar o "scale-to-zero" para este tipo de computação, se necessário.
Para uma visão geral de como funciona a escala para zero, veja Escala para zero.
Criar e gerir computações
Visualização computa
Visualização na interface de utilizador
Para visualizar os cálculos de um ramo, navegue até à página de Ramos do seu projeto na aplicação Lakebase e selecione um ramo para visualizar o separador Computes .

O separador Computes apresenta informações sobre todos os cálculos associados ao ramo. A informação apresentada no separador Computes está descrita na tabela seguinte.
| Detail | Description |
|---|---|
| Tipo de computação | O tipo de computação é Primário (leitura e escrita) ou Réplica de Leitura (apenas leitura). Uma ramificação pode ter apenas uma instância de computação Primária (leitura e escrita) e múltiplas Réplicas de Leitura (só de leitura). |
| Situação | Estado atual: Ativo ou Suspenso (quando a computação foi suspensa devido ao escalonamento para zero). Mostra a data e hora em que o cálculo foi suspenso. |
| UID | O identificador único gerado pelo sistema para o cálculo, que começa com um ep- prefixo. Este valor aparece no nome do host da ligação.
Ver Identificadores de computação. |
| Tamanho | O tamanho de computação em unidades de computação (UC). Mostra um único valor de CU (por exemplo, 8 CU) para computações de tamanho fixo. Mostra um intervalo (por exemplo, 8-16) para cálculos com autoscaling ativado. |
| Última atividade | A data e hora em que o cálculo esteve ativo pela última vez. |
Para cada cálculo, pode:
- Clique em Ligar para abrir um diálogo de ligação com detalhes de ligação para o ramo associado ao cálculo. O diálogo inclui um interruptor de pooling de ligações para funções nativas de palavra-passe do Postgres. Veja Ligar à sua base de dados e Usar gestão de conexões.
- Clique em Editar para modificar o tamanho do cálculo (intervalo fixo ou de autoescala) e configurar definições de escala para zero. Ver Editar um cálculo.
- Clique no ícone do menu para aceder a opções adicionais:
- Monitorizar atividade: Veja a atividade de cálculo e métricas de desempenho. Veja Monitorizar a sua base de dados.
- Reiniciar o cálculo: Reiniciar o cálculo para resolver problemas de ligação ou aplicar alterações de configuração. Veja Reiniciar um cálculo.
Para adicionar um cálculo de réplica de leitura ao ramo, clique em Adicionar Réplica de Leitura. As réplicas de leitura são instâncias apenas de leitura que permitem escalonamento horizontal, permitindo-lhe descarregar a carga de trabalho de leitura da sua computação principal. Ver Réplicas de leitura e Gerir réplicas de leitura.
Faz uma computação programática
Para obter detalhes sobre um cálculo específico usando a API Postgres:
Python SDK
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# Get endpoint details
endpoint = w.postgres.get_endpoint(
name="projects/my-project/branches/production/endpoints/my-compute"
)
print(f"Endpoint: {endpoint.name}")
print(f"Type: {endpoint.status.endpoint_type}")
print(f"State: {endpoint.status.current_state}")
print(f"Host: {endpoint.status.hosts.host}")
print(f"Min CU: {endpoint.status.autoscaling_limit_min_cu}")
print(f"Max CU: {endpoint.status.autoscaling_limit_max_cu}")
No SDK, acede ao host via endpoint.status.hosts.host (não endpoint.status.host).
SDK de Java
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.Endpoint;
WorkspaceClient w = new WorkspaceClient();
// Get endpoint details
Endpoint endpoint = w.postgres().getEndpoint(
"projects/my-project/branches/production/endpoints/my-compute"
);
System.out.println("Endpoint: " + endpoint.getName());
System.out.println("Type: " + endpoint.getStatus().getEndpointType());
System.out.println("State: " + endpoint.getStatus().getCurrentState());
System.out.println("Host: " + endpoint.getStatus().getHosts().getHost());
System.out.println("Min CU: " + endpoint.getStatus().getAutoscalingLimitMinCu());
System.out.println("Max CU: " + endpoint.getStatus().getAutoscalingLimitMaxCu());
CLI
# Get endpoint details
databricks postgres get-endpoint projects/my-project/branches/production/endpoints/my-compute --output json | jq
encaracolar
curl "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-compute" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Lista calcula programaticamente
Para listar todos os cálculos e réplicas de leitura para um branch usando a API Postgres:
Python SDK
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# List all endpoints for a branch
endpoints = list(w.postgres.list_endpoints(
parent="projects/my-project/branches/production"
))
for endpoint in endpoints:
print(f"Endpoint: {endpoint.name}")
print(f" Type: {endpoint.status.endpoint_type}")
print(f" State: {endpoint.status.current_state}")
print(f" Host: {endpoint.status.hosts.host}")
print(f" CU Range: {endpoint.status.autoscaling_limit_min_cu}-{endpoint.status.autoscaling_limit_max_cu}")
print()
No SDK, acede ao host via endpoint.status.hosts.host (não endpoint.status.host).
SDK de Java
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
WorkspaceClient w = new WorkspaceClient();
// List all endpoints for a branch
for (Endpoint endpoint : w.postgres().listEndpoints("projects/my-project/branches/production")) {
System.out.println("Endpoint: " + endpoint.getName());
System.out.println(" Type: " + endpoint.getStatus().getEndpointType());
System.out.println(" State: " + endpoint.getStatus().getCurrentState());
System.out.println(" Host: " + endpoint.getStatus().getHosts().getHost());
System.out.println(" CU Range: " + endpoint.getStatus().getAutoscalingLimitMinCu() +
"-" + endpoint.getStatus().getAutoscalingLimitMaxCu());
System.out.println();
}
CLI
# List endpoints for a branch
databricks postgres list-endpoints projects/my-project/branches/production --output json | jq
encaracolar
curl "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/endpoints" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Observação
Configurações típicas de ramos:
- 1 ponto final: apenas cálculo primário de leitura-escrita
- 2+ extremos: Computação primária mais uma ou mais réplicas de leitura
Editar um cálculo
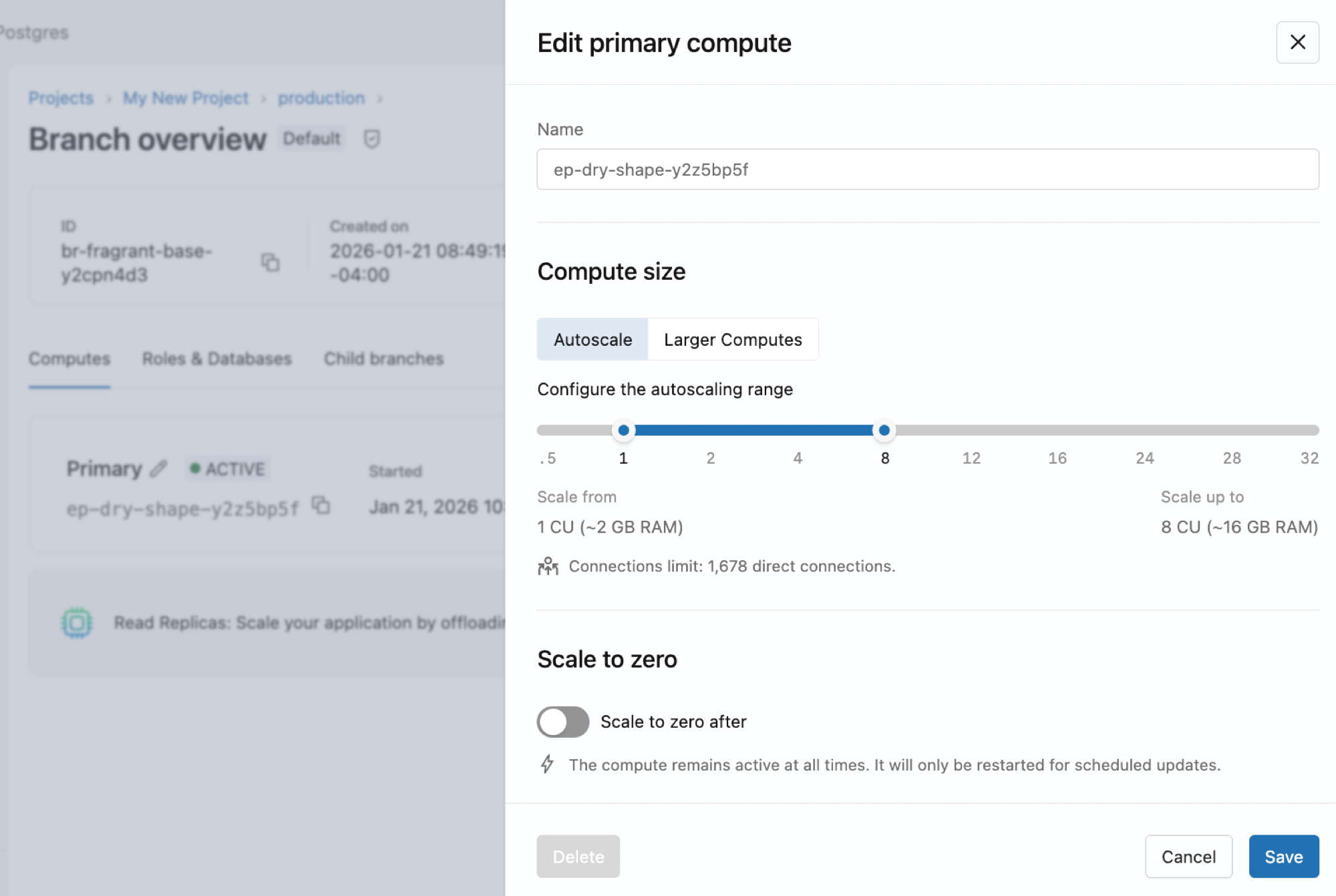
Podes editar um cálculo para alterar o seu tamanho, configuração de autoescalabilidade ou escalar para zero. Os nomes de computação são apenas de leitura e não podem ser renomeados.
Para editar um cálculo:
IU
- Vá para a aba Computes da sua filial na aplicação Lakebase.
- Clica em Editar para o cálculo, ajusta as definições e clica em Guardar.
Python SDK
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Endpoint, EndpointSpec, EndpointType, FieldMask
w = WorkspaceClient()
# Update a single field (max CU)
endpoint_spec = EndpointSpec(endpoint_type=EndpointType.ENDPOINT_TYPE_READ_WRITE, autoscaling_limit_max_cu=6.0)
endpoint = Endpoint(
name="projects/my-project/branches/production/endpoints/my-compute",
spec=endpoint_spec
)
result = w.postgres.update_endpoint(
name="projects/my-project/branches/production/endpoints/my-compute",
endpoint=endpoint,
update_mask=FieldMask(field_mask=["spec.autoscaling_limit_max_cu"])
).wait()
print(f"Updated max CU: {result.status.autoscaling_limit_max_cu}")
Para atualizar vários campos, inclua-os tanto na especificação como na máscara de atualização:
# Update multiple fields (min and max CU)
endpoint_spec = EndpointSpec(
endpoint_type=EndpointType.ENDPOINT_TYPE_READ_WRITE,
autoscaling_limit_min_cu=1.0,
autoscaling_limit_max_cu=8.0
)
endpoint = Endpoint(
name="projects/my-project/branches/production/endpoints/my-compute",
spec=endpoint_spec
)
result = w.postgres.update_endpoint(
name="projects/my-project/branches/production/endpoints/my-compute",
endpoint=endpoint,
update_mask=FieldMask(field_mask=[
"spec.autoscaling_limit_min_cu",
"spec.autoscaling_limit_max_cu"
])
).wait()
print(f"Updated min CU: {result.status.autoscaling_limit_min_cu}")
print(f"Updated max CU: {result.status.autoscaling_limit_max_cu}")
SDK de Java
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
import com.google.protobuf.FieldMask;
WorkspaceClient w = new WorkspaceClient();
// Update a single field (max CU)
EndpointSpec endpointSpec = new EndpointSpec()
.setAutoscalingLimitMaxCu(6.0);
FieldMask updateMask = FieldMask.newBuilder()
.addPaths("spec.autoscaling_limit_max_cu")
.build();
w.postgres().updateEndpoint(
new UpdateEndpointRequest()
.setName("projects/my-project/branches/production/endpoints/my-compute")
.setEndpoint(new Endpoint().setSpec(endpointSpec))
.setUpdateMask(updateMask)
);
System.out.println("Update initiated");
Para atualizar vários campos, inclua-os tanto na especificação como na máscara de atualização:
// Update multiple fields (min and max CU)
EndpointSpec endpointSpec = new EndpointSpec()
.setAutoscalingLimitMinCu(1.0)
.setAutoscalingLimitMaxCu(8.0);
FieldMask updateMask = FieldMask.newBuilder()
.addPaths("spec.autoscaling_limit_min_cu")
.addPaths("spec.autoscaling_limit_max_cu")
.build();
w.postgres().updateEndpoint(
new UpdateEndpointRequest()
.setName("projects/my-project/branches/production/endpoints/my-compute")
.setEndpoint(new Endpoint().setSpec(endpointSpec))
.setUpdateMask(updateMask)
);
System.out.println("Update initiated");
CLI
# Update a single field (max CU)
databricks postgres update-endpoint projects/my-project/branches/production/endpoints/my-compute spec.autoscaling_limit_max_cu \
--json '{
"spec": {
"autoscaling_limit_max_cu": 6.0
}
}'
# Update multiple fields (min and max CU)
databricks postgres update-endpoint projects/my-project/branches/production/endpoints/my-compute "spec.autoscaling_limit_min_cu,spec.autoscaling_limit_max_cu" \
--json '{
"spec": {
"autoscaling_limit_min_cu": 1.0,
"autoscaling_limit_max_cu": 8.0
}
}'
encaracolar
# Update a single field (max CU)
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-compute?update_mask=spec.autoscaling_limit_max_cu" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/endpoints/my-compute",
"spec": {
"autoscaling_limit_max_cu": 6.0
}
}' | jq
# Update multiple fields (min and max CU)
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-compute?update_mask=spec.autoscaling_limit_min_cu,spec.autoscaling_limit_max_cu" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/endpoints/my-compute",
"spec": {
"autoscaling_limit_min_cu": 1.0,
"autoscaling_limit_max_cu": 8.0
}
}' | jq
Observação
Alterações às definições de computação têm efeito imediato e podem causar breves interrupções na ligação durante o reinício.
Reiniciar uma computação
Reiniciar um cálculo para aplicar atualizações, resolver problemas de desempenho ou detetar alterações de configuração.
Para reiniciar um cálculo:
- Vá para a aba Computes da sua filial na aplicação Lakebase.
- Clique no
 Menu para o cálculo, selecione Reiniciar e confirme a operação.
Menu para o cálculo, selecione Reiniciar e confirme a operação.
Importante
Reiniciar um cálculo interrompe quaisquer ligações ativas. Configure as suas aplicações para se reconectarem automaticamente e evitar interrupções prolongadas.