Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Até ao final deste guia, terá uma base de dados Postgres em funcionamento com dados de exemplo, pronta para ser ligada à sua aplicação ou integrada no lakehouse da Databricks.
Passos: (1) Criar um projeto → (2) Ligar → (3) Criar uma tabela
Passo 1: Crie o seu primeiro projeto
Abre a aplicação Lakebase a partir do comutador de apps.

Selecione Autoscaling para aceder à interface de Autoscaling do Lakebase.
Clique em Novo projeto. Dá um nome ao teu projeto e seleciona a versão do Postgres. O seu projeto é criado com um único production branch, uma base de dados padrão databricks_postgres e recursos de computação configurados para o branch.

Pode demorar alguns momentos até o seu computador ser ativado. A computação do ramo production tem o dimensionamento até zero ativado por predefinição, com um tempo limite de inatividade de 24 horas, mas pode configurar esta definição, se necessário.
A região do seu projeto é automaticamente definida para a região do seu espaço de trabalho. Ver disponibilidade por região.
Saiba mais: Criar um projeto | Escalar | automaticamente até zero
Passo 2: Ligue-se à sua base de dados
A partir do seu projeto, selecione o ramo de produção e clique em Conectar. As strings de ligação funcionam com qualquer cliente Postgres padrão (psql, pgAdmin, DBeaver ou frameworks de aplicações).

Para se ligar à sua identidade Databricks, copie o psql excerto do diálogo de ligação e cole o token OAuth quando solicitado:
psql 'postgresql://your-email@databricks.com@ep-abc-123.databricks.com/databricks_postgres?sslmode=require'
Saiba mais: Conexão quickstart | psql | pgAdmin | Clientes Postgres
Passo 3: Crie a sua primeira tabela
O Lakebase SQL Editor vem pré-carregado com SQL de exemplo. A partir do seu projeto, selecione o ramo de produção , abra o SQL Editor e execute as instruções fornecidas para criar uma playing_with_lakebase tabela e inserir dados de exemplo.
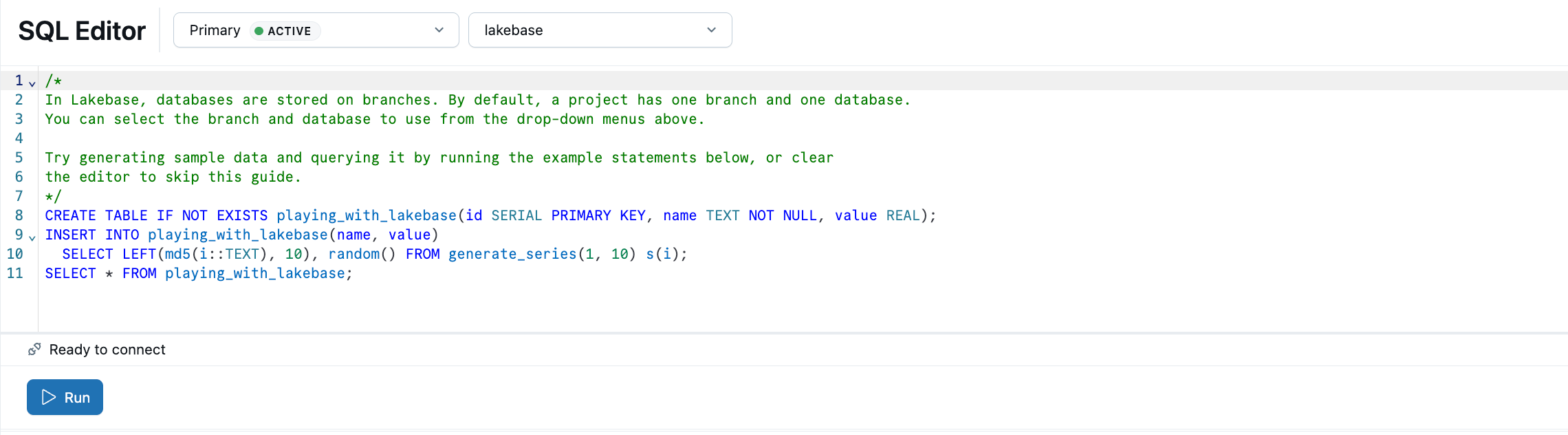
Saiba mais: Editor SQL | Editor de Tabelas | Clientes Postgres
Próximos passos
| Passo seguinte | Description |
|---|---|
| Disponibilizar dados do lakehouse | Sincroniza as tabelas do Unity Catalog no Postgres para leituras de aplicações com baixa latência. |
Mais informações
| Resource | Description |
|---|---|
| Criar uma aplicação | Implemente uma aplicação Databricks com ligação automática ao Lakebase. |
| Registar-se no Catálogo Unity | Governação unificada, linhagem e consultas entre fontes. |
| Conceitos fundamentais | Dimensionamento automático, escala a zero, criação de ramos, e como funcionam. |
| Projetos | Arquitetura, modelo ramificado e visão geral do produto. |