Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
O Databricks Apps permite-lhe construir e implementar aplicações interativas diretamente no seu espaço de trabalho do Azure Databricks. Adicionar o Lakebase como recurso dá à sua aplicação um backend Postgres totalmente gerido. O Azure Databricks cria um principal de serviço para a sua aplicação, concede-lhe um papel Postgres correspondente e injeta detalhes de ligação como variáveis de ambiente. A sua aplicação liga-se a uma base de dados Postgres totalmente gerida sem gerir credenciais ou cadeias de ligação.

Este tutorial guia-o como implementar uma aplicação modelo ligada a uma base de dados Lakebase. No final, terá uma aplicação em execução com dados que pode inspecionar e consultar diretamente do Lakebase, e opcionalmente registar no Unity Catalog juntamente com os dados do seu lakehouse.
Pré-requisitos
Antes de começar, certifique-se de que tem o seguinte:
- Acesso a um espaço de trabalho Azure Databricks com Lakebase e computação serverless ativados. Contacte o administrador do seu espaço de trabalho, se necessário.
- Permissão para criar recursos computacionais e aplicações.
Passo 1: Provisionar uma instância Lakebase
Um projeto Lakebase é uma instância Postgres gerida à qual a sua aplicação se liga como um recurso. Os projetos estão organizados em ramos, cada um representando um ambiente de base de dados isolado.
Para criar um projeto Lakebase, consulte Obter uma base de dados Postgres. A Lakebase cria o seu projeto com uma production filial e uma databricks_postgres base de dados.
Passo 2: Criar uma aplicação Databricks
O Azure Databricks disponibiliza três modelos de aplicações autoescaláveis que demonstram a integração com o Lakebase usando uma aplicação de gestão de tarefas: Dash, Flask e Streamlit. Para criar uma aplicação a partir de um modelo:
- No seu espaço de trabalho Azure Databricks, clique no ícone
 no alternador de aplicativos e selecione Databricks Aplicativos.
no alternador de aplicativos e selecione Databricks Aplicativos. - Clica + Criar app.
- Selecione o seu modelo preferido no separador Base de Dados .
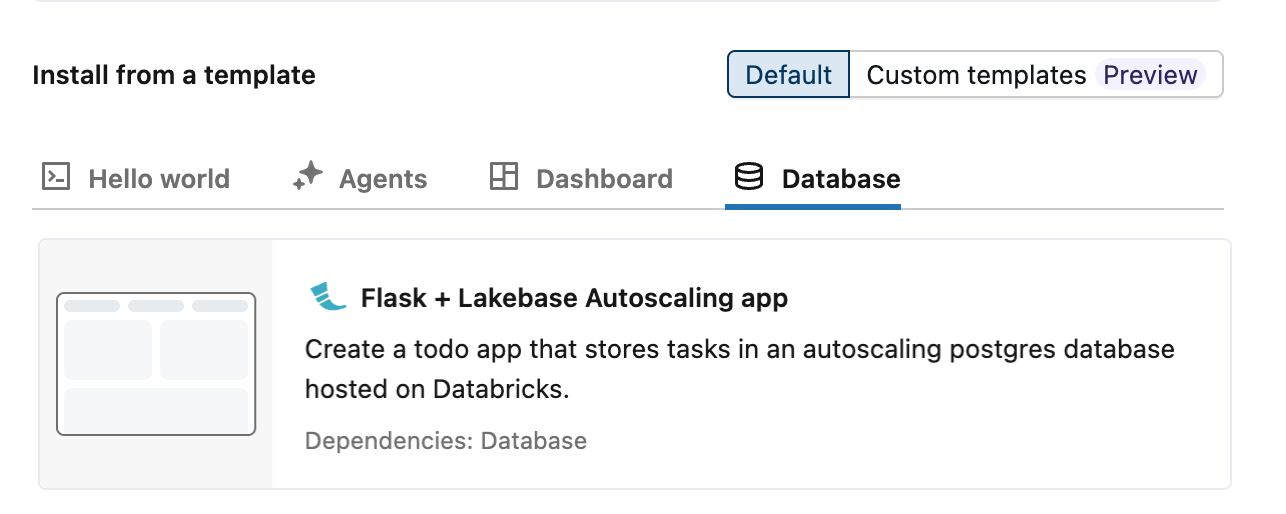
Passo 3: Configurar um recurso de base de dados
Adicionar o Lakebase como recurso cria um principal de serviço com as permissões corretas da base de dados e injeta os detalhes da sua ligação como variáveis de ambiente na aplicação. Isto permite que o modelo se ligue automaticamente à tua base de dados, sem quaisquer strings de ligação no teu código.
No passo Configurar , configure as seguintes definições.
- Para recursos da App, selecione o seu projeto, filial e base de dados Lakebase. Os nomes das filiais aparecem como IDs. Para associar IDs a nomes, consulte a página das filiais do seu projeto.
- Para tamanho de computação, selecione Médio. Este controla a computação do servidor de aplicações, que é separada da computação da base de dados Lakebase e escala de forma independente.

Para mais informações, consulte Adicionar um recurso Lakebase a uma aplicação Databricks.
Passo 4: Rever autorizações
Cada aplicação Databricks funciona como a sua própria entidade de serviço, uma identidade dedicada separada de qualquer utilizador individual. Quando ligas o Lakebase como recurso, Azure Databricks cria um papel Postgres correspondente para esse principal de serviço e concede-lhe acesso total à base de dados. Não é necessária configuração manual de funções.

Passo 5: Nomeie a sua aplicação e instale
O Lakebase usa o nome da aplicação para gerar o nome do esquema no formato {app-name}_schema_{service-principal-id} (hífens removidos do ID). Não podes mudar o nome da app após a criação, mas podes renomear o esquema mais tarde. O modelo é definido por defeito para lakebase-autoscaling-app.
Clique em Criar aplicação para criar a aplicação.
Passo 6: Implementar a aplicação
Depois de criares a aplicação, o cálculo começa automaticamente e a tua aplicação é implementada em cerca de 2-3 minutos sem qualquer ação adicional. Quando o estado da aplicação mostrar Em Execução, clique no URL ao lado para abrir a sua aplicação.

Passo 7: Verificar a integração
Adiciona algumas tarefas pendentes na tua aplicação. No seu projeto Lakebase, abra Tabelas e selecione a tabela todos no esquema da sua aplicação. O principal de serviço da aplicação escreveu essas linhas usando os detalhes de ligação inseridos no Passo 3.

Para consultar os dados diretamente, use o Editor SQL no seu projeto Lakebase. Como o Lakebase escala para zero quando está inativo, a primeira consulta após uma longa pausa pode demorar alguns segundos a responder. Para outras opções de ligação, consulte Ligar à sua base de dados.
Passo 8: Consultar através do Catálogo Unity (opcional)
Por padrão, os dados do Lakebase da sua aplicação são acessíveis diretamente através das ligações Postgres. Registar isso no Unity Catalog torna-o consultável juntamente com os dados do seu lakehouse usando o SQL padrão do Databricks. Pode então juntar as tabelas transacionais da sua aplicação às tabelas Delta na mesma consulta.
Para se registar, abra o Explorador de Catálogos e crie um novo catálogo. Seleciona o Lakebase Postgres como tipo de catálogo, escolhe Autoscaling e seleciona o mesmo projeto e ramificação da tua aplicação. Consulte Registar a sua base de dados no Catálogo Unity para detalhes completos.
Note que os nomes dos esquemas no Unity Catalog preservam hífens do nome da sua app. Tanto os nomes do catálogo como os dos esquemas exigem delimitação por aspas invertidas.
SELECT * FROM `your-catalog-name`.`lakebase-autoscaling-app_schema_aeb6ff9198ff4752af7dfc6d4cf570d0`.todos;