Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Aplica-se apenas a:![]() Portal Foundry (clássico). Este artigo não está disponível para o novo portal da Foundry.
Saiba mais sobre o novo portal.
Portal Foundry (clássico). Este artigo não está disponível para o novo portal da Foundry.
Saiba mais sobre o novo portal.
Nota
Os links neste artigo podem abrir conteúdo na nova documentação do Microsoft Foundry em vez da documentação do Foundry (clássico) que está a ver agora.
Microsoft Foundry Models inclui um catálogo abrangente de modelos organizados em duas categorias — modelos vendidos diretamente por Azure e modelos de parceiros e comunidade. Os modelos dos parceiros e da comunidade, que pode implementar em computação gerida, são modelos abertos ou protegidos. Neste artigo, vai aprender a usar modelos protegidos de parceiros e da comunidade, oferecidos através do Azure Marketplace, para implementação em ambiente de computação gerida com faturação consoante o uso.
Pré-requisitos
Uma subscrição do Azure com um método de pagamento válido. Subscrições gratuitas ou de teste no Azure não funcionam. Se não tiver uma subscrição Azure, crie uma conta Azure paga para começar.
Se não tiveres um, cria um projeto hub para a Foundry. Podes implementar para computação gerida usando um projeto hub. Um projeto Foundry não funciona para este propósito.
Compras no Azure Marketplace ativadas para a sua subscrição Azure.
Os controlos de acesso baseados em papéis do Azure (Azure RBAC) concedem acesso às operações no portal Foundry. Para realizar os passos deste artigo, a sua conta de utilizador deve receber um papel personalizado com as seguintes permissões. As contas de utilizador atribuídas à função Proprietário ou Contribuidor para a subscrição do Azure também podem criar implementações. Para mais informações sobre permissões, consulte Controlo de acesso baseado em funções no portal Foundry.
Na subscrição Azure— para subscrever o espaço de trabalho/projeto à oferta Azure Marketplace:
- Microsoft. MarketplaceEncomendas/acordos/ofertas/planos/leitura
- Microsoft. MarketplaceEncomendas/acordos/ofertas/planos/assinar/agir
- Microsoft. MarketplaceOrdering/ofertasTipos/editores/ofertas/planos/acordos/leitura
- Microsoft. Mercado/ofertasTipos/editores/ofertas/planos/acordos/leitura
- Microsoft. SaaS/registo/ação
Sobre o grupo de recursos — para criar e usar o recurso SaaS:
- Microsoft. SaaS/recursos/leitura
- Microsoft. SaaS/resources/write
No espaço de trabalho — para implementar endpoints:
- Microsoft. MachineLearningServices/espaços de trabalho/marketplaceModelSubscriptions/*
- Microsoft. MachineLearningServices/workspaces/onlineEndpoints/*
Âmbito de subscrição e unidade de medida para a oferta do Azure Marketplace
A Foundry proporciona uma experiência de subscrição e transação fluida para modelos protegidos à medida que cria e consome as suas implementações dedicadas de modelos em grande escala. A implementação de modelos protegidos na computação gerida envolve a faturação conforme o uso para o cliente em dois aspetos:
- O Azure Machine Learning computa faturação por hora para as máquinas virtuais utilizadas na implementação.
- Faturação adicional para o modelo conforme estabelecido pelo editor do modelo na oferta do Azure Marketplace.
A faturação pay-as-you-go do cálculo do Azure e a sobretaxa do modelo é rateada por minuto, com base no tempo de atividade das implementações online geridas. A sobretaxa para um modelo é um preço por hora de GPU, definido pelo parceiro (ou editora do modelo) no Azure Marketplace, para todas as GPUs suportadas que pode usar para implementar o modelo na computação gerida da Foundry.
A subscrição de um utilizador às ofertas do Azure Marketplace está limitada ao âmbito de recurso do projeto dentro do Foundry. Se já existir uma subscrição à oferta do Azure Marketplace para um modelo específico dentro do projeto, o utilizador é informado no assistente de implementação de que a subscrição já existe para o projeto.
Nota
Para os microserviços de inferência (NIM) da NVIDIA, múltiplos modelos estão associados a uma única oferta de marketplace, pelo que só precisa de subscrever a oferta NIM uma vez dentro de um projeto para poder implementar todas as NIMs oferecidas pela NVIDIA no catálogo de modelos da Foundry. Se quiseres implementar NIMs num projeto diferente sem subscrição SaaS existente, tens de voltar a subscrever a oferta.
Para encontrar todas as subscrições SaaS que existem numa subscrição do Azure:
Inicie sessão no portal Azure e aceda à sua subscrição Azure.
Selecione Subscrições e depois selecione a sua subscrição Azure para abrir a sua página de visão geral.
Selecione Definições>Recursos para ver a lista de recursos.
Use o filtro de Tipo para selecionar o tipo de recurso SaaS.
A sobretaxa baseada no consumo vai para a subscrição SaaS associada e fatura ao utilizador através do Azure Marketplace. Pode ver a fatura no separador Overview da respetiva subscrição SaaS.
Subscreva e implemente em computação gerida
Dica
Como podes personalizar o painel esquerdo no portal Microsoft Foundry, podes ver itens diferentes dos mostrados nestes passos. Se não vires o que procuras, seleciona ... Mais na parte inferior do painel esquerdo.
-
Iniciar sessão no Microsoft Foundry. Certifica-te de que a opção do New Foundry está desligada. Estes passos referem-se à Foundry (clássica).

Se ainda não estás no teu projeto, seleciona-o.
Selecione catálogo de modelos no painel esquerdo.
Filtra a lista de modelos selecionando a Coleção e o modelo da tua escolha. Este artigo utiliza o Cohere Command A da lista de modelos suportados para ilustração.
Na página do modelo, selecione Usar este modelo para abrir o assistente de implementação.
Se lhe forem apresentadas opções de compra, selecione Computação Gerida.
Se não tiver uma quota dedicada, selecione a caixa de seleção ao lado da declaração: Quero usar quota partilhada e reconheço que este endpoint será eliminado em 168 horas.
Escolha um dos SKUs de máquinas virtuais (VM) suportados para o modelo. Precisas de ter uma quota de computação do Azure Machine Learning para esse SKU na tua subscrição do Azure.
Selecione Personalizar para especificar a sua configuração de implementação para parâmetros como a contagem de instâncias. Também pode selecionar um endpoint existente para a implementação ou criar um novo. Neste exemplo, especifique um número de instâncias de 1 e crie um novo endpoint para a implementação.
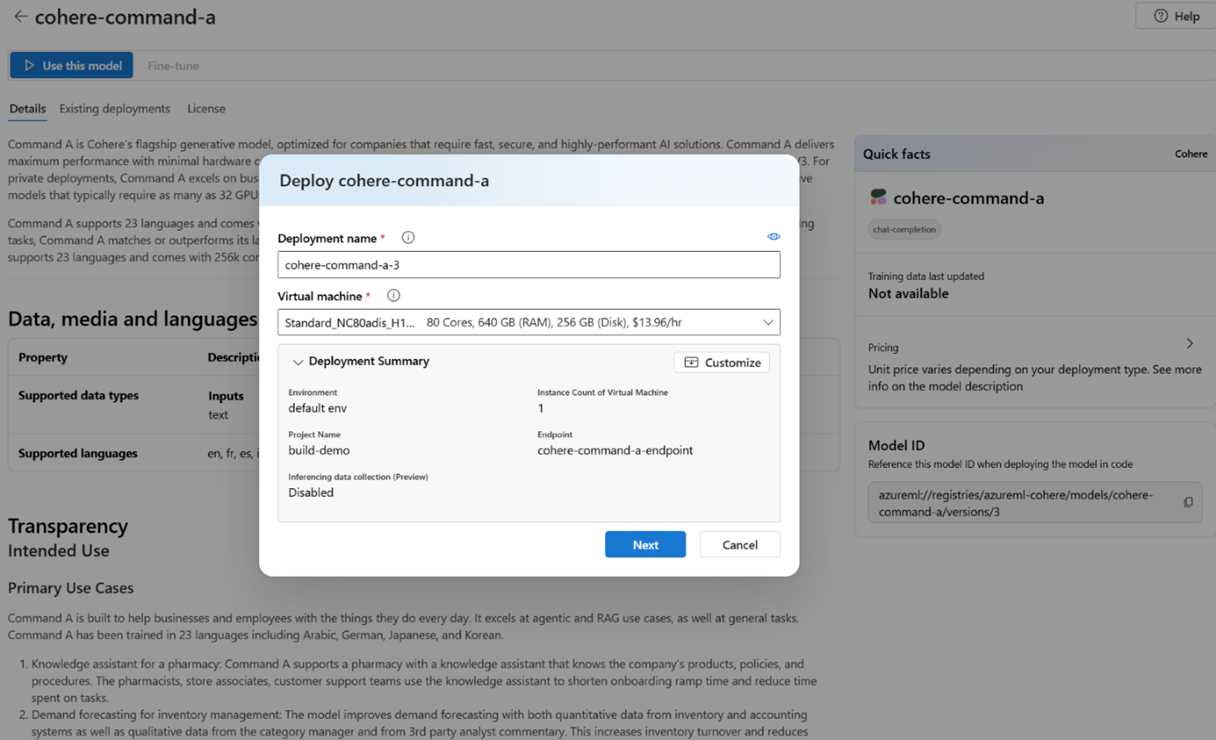
Selecione Seguinte para avançar para a página de detalhamento de preços .
Consulte a distribuição de preços para a implementação, termos de utilização e contrato de licença associados à oferta do modelo no Azure Marketplace. A divisão de preços indica-lhe qual seria o preço agregado para o modelo implementado, onde a sobretaxa para o modelo é uma função do número de GPUs na instância da VM que selecionou nos passos anteriores. Para além da sobretaxa aplicável ao modelo, também se aplicam encargos de computação do Azure, consoante a sua configuração de implementação. Se tiver reservas existentes ou um plano de poupança no Azure, a fatura dos custos de computação irá honrar e refletir o preço descontado da VM.

Selecione a caixa para confirmar que compreende e concorda com os termos de utilização. Depois, selecione Implementar. A Foundry cria a sua subscrição à oferta do marketplace e depois cria a implementação do modelo numa computação gerida. Demora cerca de 15 a 20 minutos para concluir a implementação.


Implementações de consumo
Depois de criar com sucesso a sua implantação, siga estes passos para a consumir:
- Selecione Modelos + Endpoints em Meus ativos no seu projeto Foundry.
- Selecione a sua implementação no separador de implementações de modelos.
- Aceda ao separador Teste para realizar uma inferência de exemplo no endpoint.
- Volte ao separador Detalhes para copiar o "Target URI" da implementação, que pode usar para fazer inferência com código.
- Vá ao separador Consumir da implementação para encontrar exemplos de código para consumo.
Isolamento de rede das implementações
Pode implementar coleções no catálogo de modelos dentro das suas redes isoladas usando uma rede virtual gerida pelo espaço de trabalho. Para mais informações sobre como configurar as redes geridas do seu espaço de trabalho, consulte Configurar uma rede virtual gerida para permitir a saída da internet.
Limitação
Um projeto Foundry com acesso público à rede de entrada desativado só pode suportar uma única implementação ativa de um dos modelos protegidos do catálogo. As tentativas de criar implementações mais ativas resultam em falhas na criação de implementações.
Modelos suportados
As secções seguintes listam os modelos suportados para implementação de computação gerida com faturação pay-as-you-go, agrupados por coleção.
IA Boson
| Modelo | Tarefa |
|---|---|
| bosonai-higgs-audio-v3-stt | Reconhecimento automático de fala |
| Higgs-Audio-v2.5 | Geração de áudio |
Cohere
| Modelo | Tarefa |
|---|---|
| Comando A | Conclusão do chat |
| Embed v4 | Embeddings |
| Rerank v3.5 | Classificação do texto |
| Cohere-rerank-v4.0-pro | Reordenação da classificação de texto |
| Cohere-rerank-v4.0-fast | Reordenamento da classificação de texto |
Domyn
| Modelo | Tarefa |
|---|---|
| Domyn-Large | Conclusão do chat |
Laboratórios Inception
| Modelo | Tarefa |
|---|---|
| Mercúrio | Conclusão do chat, geração de texto, resumo |
NVIDIA
Os microserviços de inferência (NIM) da NVIDIA são contentores que a NVIDIA constrói para modelos de IA otimizados pré-treinados e personalizados que funcionam em GPUs NVIDIA. Pode realizar a implementação dos NIMs NVIDIA que estão disponíveis no catálogo de modelos da Foundry com uma subscrição Standard para a oferta NVIDIA NIM SaaS no Azure Marketplace.
Algumas coisas especiais a notar sobre as NIMs são:
As NIMs incluem um período experimental de 90 dias. O teste aplica-se a todas as NIMs associadas a uma subscrição SaaS específica e começa a partir da criação da subscrição SaaS.
As subscrições SaaS abrangem um projeto da Foundry. Como múltiplos modelos estão associados a uma única oferta do Azure Marketplace, só precisa de subscrever uma vez a oferta NIM dentro de um projeto, e depois pode implementar todas as NIMs oferecidas pela NVIDIA no catálogo de modelos Foundry. Se quiseres implementar NIMs num projeto diferente sem subscrição SaaS existente, tens de voltar a subscrever a oferta.
Consumir implantações NIM da NVIDIA
Depois de criar a sua implementação, siga os passos em Consume deployments para a consumir.
As NIMs NVIDIA na Foundry expõem uma API compatível com OpenAI. Consulte a referência da API para saber mais sobre a carga útil suportada. O model parâmetro para NIMs no Foundry está definido para um valor padrão dentro do contentor e não é necessário no payload de pedido para o teu endpoint online. O separador Consume da implementação NIM no Foundry inclui exemplos de código para inferência com o URL alvo da sua implementação.
Também pode consumir implementações NIM utilizando o SDK Foundry Models, com limitações que incluem:
- Não há suporte para criar e autenticar clientes usando
load_client. - Deve chamar o método do cliente
get_model_infopara obter informação do modelo.
Desenvolver e executar agentes com endpoints NIM
As seguintes NIMs NVIDIA do tipo de tarefa de conclusão de chat no catálogo de modelos podem ser usadas para criar e executar agentes usando o Agent Service com várias ferramentas suportadas, com os seguintes dois requisitos adicionais:
- Crie uma Ligação Serverless ao projeto usando o endpoint NIM e a chave. A URL de destino para o endpoint NIM na ligação deve ser
https://<endpoint-name>.region.inference.ml.azure.com/v1/. - Defina o parâmetro do modelo no corpo do pedido para ser da forma,
https://<endpoint>.region.inference.ml.azure.com/v1/@<parameter value per table below>enquanto cria e executa agentes.
| NVIDIA NIM |
model Valor do parâmetro |
|---|---|
| Llama-3.3-70B-Instruct-NIM-microservice | meta/llama-3.3-70b-instruct |
| Llama-3.1-8B-Instruct-NIM-microservice | meta/llama-3.1-8b-instruct |
| Mistral-7B-Instruct-v0.3-NIM-microservice | mistralai/mistral-7b-instruct-v0.3 |
Varredura de segurança
A NVIDIA assegura a segurança e fiabilidade das imagens de contentores NIM NVIDIA através de uma análise de vulnerabilidades de excelência, gestão rigorosa de patches e processos transparentes. A Microsoft trabalha com a NVIDIA para obter os patches mais recentes das NIMs, de modo a disponibilizar software de produção seguro, estável e fiável dentro da Foundry.
Pode consultar a última hora de atualização da NIM na coluna à direita da página de visão geral do modelo. Pode reimplementar para consumir a versão mais recente do NIM da NVIDIA no Foundry.
Paige AI
| Modelo | Tarefa |
|---|---|
| Virchow2G | Extração de Características de Imagem |
| Virchow2G-Mini | Extração de Características de Imagem |
Voyage AI
| Modelo | Tarefa |
|---|---|
| Voyage-3.5-Modelo de Incorporação | Embeddings |