Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Aplica-se apenas a:![]() Portal Foundry (clássico). Este artigo não está disponível para o novo portal da Foundry.
Saiba mais sobre o novo portal.
Portal Foundry (clássico). Este artigo não está disponível para o novo portal da Foundry.
Saiba mais sobre o novo portal.
Nota
Os links neste artigo podem abrir conteúdo na nova documentação do Microsoft Foundry em vez da documentação do Foundry (clássico) que está a ver agora.
O catálogo de modelos do portal Microsoft Foundry oferece mais de 1.600 modelos que pode implementar usando computação gerida (também chamada de implementação online gerida) para inferência em tempo real em ambientes de produção. Com implementações de computação gerida, obtém-se uma infraestrutura escalável e pronta para produção para os seus grandes modelos de linguagem.
Neste artigo, aprende como implementar modelos com a opção de implementação de computação gerida e realizar inferência sobre o modelo implementado.
Pré-requisitos
Uma subscrição do Azure com um método de pagamento válido. Subscrições gratuitas ou de teste no Azure não funcionam. Se não tiver uma subscrição Azure, crie uma conta Azure paga.
Se não tiveres um, cria um projeto baseado em hubs. Para mais informações, consulte Criar um projeto.
A Foundry Modelos de Parceiros e Comunidade requer acesso à Azure Marketplace, enquanto a Foundry Modelos Vendidos Diretamente por Azure não tem este requisito. Certifique-se de que a sua subscrição do Azure tem as permissões necessárias para subscrever ofertas de modelos no Azure Marketplace. Para mais informações, consulte Ativar compras no Azure Marketplace.
Os controlos de acesso baseados em papéis do Azure (Azure RBAC) concedem acesso às operações no portal Foundry. Para realizar os passos deste artigo, a sua conta de utilizador deve ser atribuída à função Azure AI Developer no grupo de recursos. Para mais informações, consulte Controlo de acesso baseado em funções no portal Foundry.
Quota de máquinas virtuais (VM) na sua subscrição Azure para os SKUs VM específicos necessários para executar o seu modelo. Cada implementação consome a quota do núcleo de VM por região. Para mais informações, consulte Considerações de quotas, incluindo requisitos de quotas e como solicitar aumentos.
Para implementações com Python SDK: Python 3.8 ou posterior instalado, incluindo o SDK Azure Machine Learning (
azure-ai-ml) e a biblioteca Azure Identity (azure-identity).
Encontre o seu modelo no catálogo de modelos
- Iniciar sessão no Microsoft Foundry. Certifica-te de que a opção do New Foundry está desligada. Estes são os passos que se referem à Foundry (clássica).

- Se ainda não estás no teu projeto, seleciona-o.
- Selecione catálogo de modelos no painel esquerdo.
No filtro de opções de implementação , selecione Computação Gerida.
Dica
Como podes personalizar o painel esquerdo no portal Microsoft Foundry, podes ver itens diferentes dos mostrados nestes passos. Se não vires o que procuras, seleciona ... Mais na parte inferior do painel esquerdo.
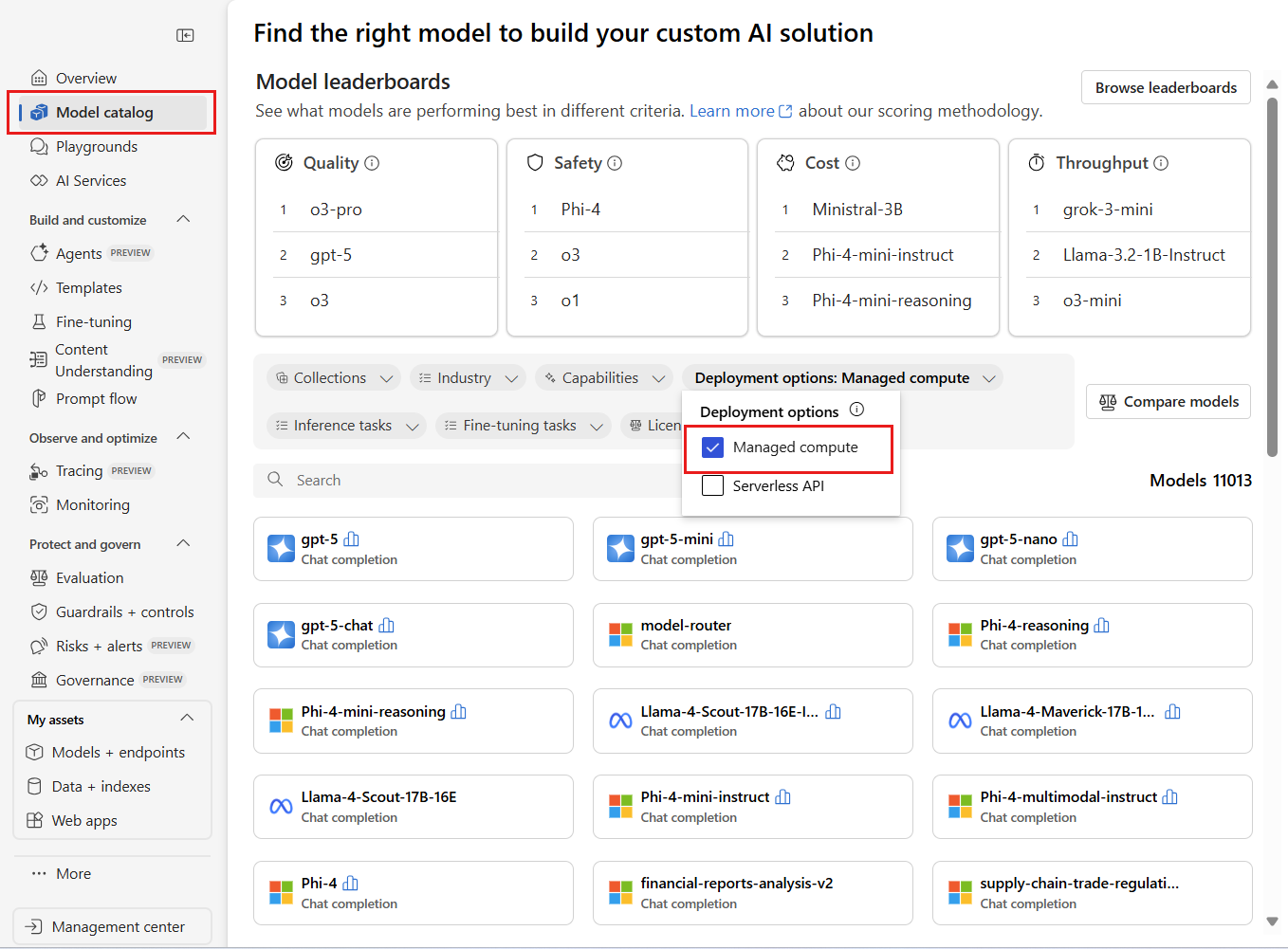
Selecione um modelo para abrir a sua placa modelo. Neste artigo, utilizas o modelo
Phi-4.

Implementar o modelo
Na página do modelo, selecione Usar este modelo. Esta ação abre a janela de implementação se o modelo selecionado puder ser implementado apenas numa computação gerida.
Alternativamente, se selecionaste um modelo que também suporta outra opção de implementação, ficas na janela "Opções de compra". Selecione a opção de compra de Computação Gerida para abrir a janela de implementação.
- Selecione a caixa de seleção na janela de implementação para usar a quota partilhada temporária. Para a implementação numa computação gerida auto-hospedada, deve ter uma quota suficiente na sua subscrição. Se não tiver quota suficiente disponível, pode usar o nosso acesso temporário à quota selecionando a opção que quero usar quota partilhada e reconheço que este endpoint será eliminado em 168 horas.
A janela de implementação é pré-preenchida com algumas seleções e valores de parâmetros. Podes mantê-los ou mudá-los conforme quiseres. Também pode selecionar um endpoint existente para a implementação ou criar um novo. Neste exemplo, especifique uma contagem de instâncias de
1e crie um novo endpoint para a implementação.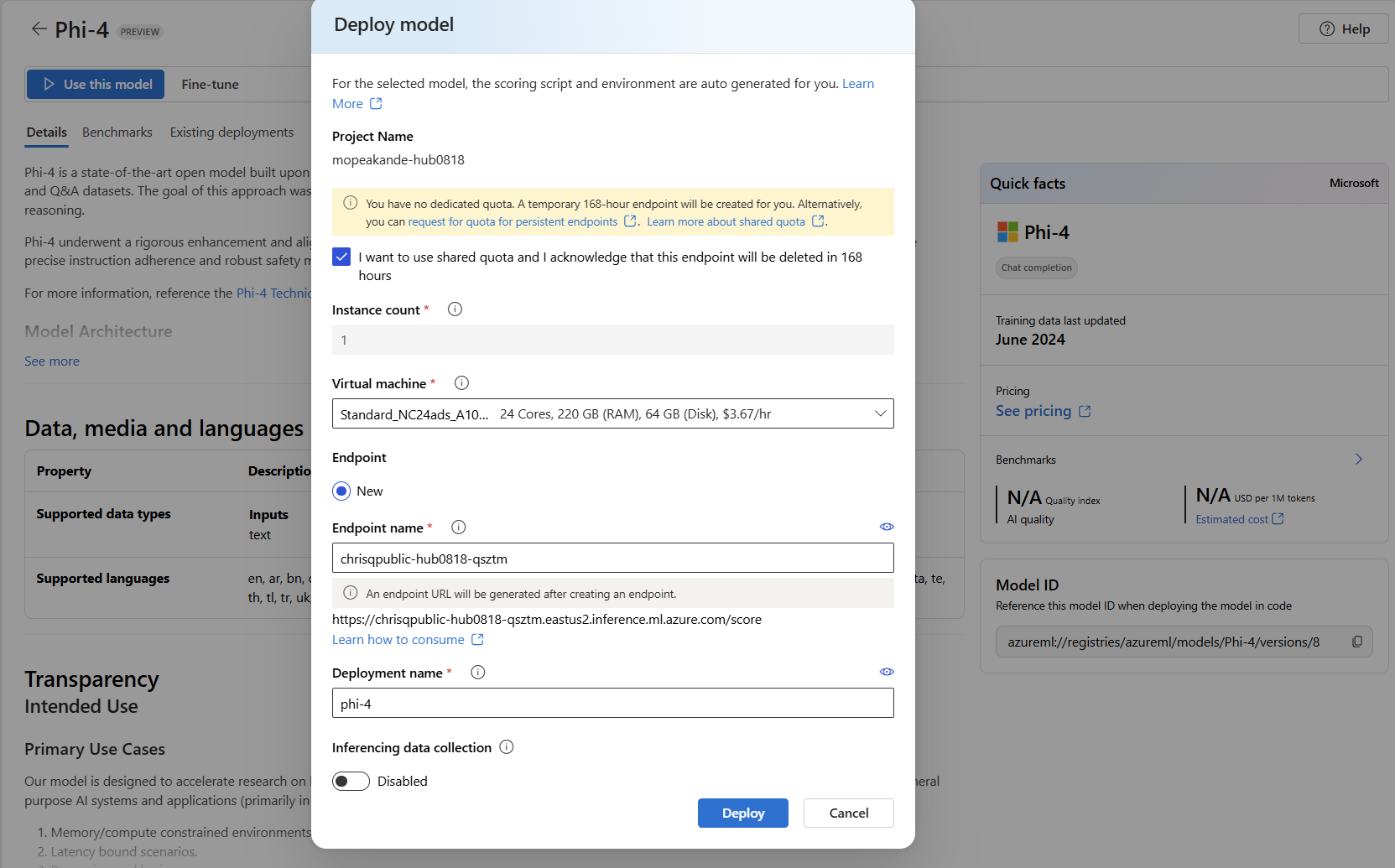
Selecione Implementar para criar a sua implementação. O processo de criação pode demorar alguns minutos a concluir. Quando está concluído, o portal abre a página de implementação do modelo.
Dica
Para ver os endpoints implementados no seu projeto, vá à secção My assets do painel esquerdo e selecione Modelos + endpoints.
Confirma que a tua missão foi bem-sucedida. Na página de detalhes da implementação, verifique se o estado de Provisionamento mostra Bem-sucedido e o estado de Implementação mostra Saudável. Se detetar algum erro, consulte a secção de Resolução de Problemas .
O endpoint criado utiliza autenticação por chave para autorização. Para obter as chaves associadas a um determinado endpoint, siga estes passos:
- Selecione a implementação e anote o URI e a Chave de destino do endpoint.
- Use estas credenciais para chamar a implementação e gerar previsões.
O URI Target segue este formato:
https://<endpoint-name>.<region>.inference.ml.azure.com/score

Implementações de consumo
Depois de criar a sua implementação, siga estes passos para a consumir:
- Selecione Modelos + endpoints na secção Meus ativos no seu projeto Foundry.
- Selecione a sua implementação no separador de implementações de modelos.
- Aceda ao separador Teste para realizar uma inferência de exemplo no endpoint.
- Volte ao separador Detalhes para copiar o "Target URI" da implementação, que pode usar para fazer inferência com código.
- Vá ao separador Consumir da implementação para encontrar exemplos de código para consumo.
- Copie o ID do modelo da página de detalhes do modelo que selecionou. Fica assim para o modelo selecionado:
azureml://registries/azureml/models/Phi-4/versions/8.
Implementar o modelo
Instale o SDK Azure Machine Learning.
pip install azure-ai-ml pip install azure-identityAutenticar com Azure Machine Learning e criar um objeto cliente. Substitua os marcadores de lugar pelo seu ID de subscrição, nome do grupo de recursos e nome do projeto Foundry.
from azure.ai.ml import MLClient from azure.identity import InteractiveBrowserCredential workspace_ml_client = MLClient( credential=InteractiveBrowserCredential(), subscription_id="your subscription ID goes here", resource_group_name="your resource group name goes here", workspace_name="your project name goes here", )Este código autentica-se com o Azure usando credenciais de navegador interativas e cria um cliente para interagir com o seu projeto Foundry. Quando executa este código, abre-se uma janela do navegador para autenticação.
Referência:MLClient, InteractiveBrowserCredential
Cria um endpoint. Para a opção de implementação de computação gerida, é necessário criar um endpoint antes de uma implementação do modelo. Pense num endpoint como um contentor que pode alojar múltiplas implementações de modelos. Os nomes dos endpoints precisam de ser únicos numa região, por isso, neste exemplo, use o carimbo temporal para criar um nome de endpoint único.
import time, sys from azure.ai.ml.entities import ( ManagedOnlineEndpoint, ManagedOnlineDeployment, ProbeSettings, ) # Make the endpoint name unique timestamp = int(time.time()) online_endpoint_name = "customize your endpoint name here" + str(timestamp) # Create an online endpoint endpoint = ManagedOnlineEndpoint( name=online_endpoint_name, auth_mode="key", ) workspace_ml_client.online_endpoints.begin_create_or_update(endpoint).wait()Este código cria um endpoint online gerido com autenticação baseada em chaves. A operação normalmente demora 2-3 minutos. Quando estiver concluído, terá uma URL de endpoint onde poderá implementar modelos.
Referência:ManagedOnlineEndpoint, online_endpoints.begin_create_or_update
Crie uma implantação. Substitua o ID do modelo no próximo código pelo ID do modelo que copiou da página de detalhes do modelo que selecionou na secção Encontrar o seu modelo na secção de catálogo de modelos .
model_name = "azureml://registries/azureml/models/Phi-4/versions/8" demo_deployment = ManagedOnlineDeployment( name="demo", endpoint_name=online_endpoint_name, model=model_name, instance_type="Standard_DS3_v2", instance_count=2, liveness_probe=ProbeSettings( failure_threshold=30, success_threshold=1, timeout=2, period=10, initial_delay=1000, ), readiness_probe=ProbeSettings( failure_threshold=10, success_threshold=1, timeout=10, period=10, initial_delay=1000, ), ) workspace_ml_client.online_deployments.begin_create_or_update(demo_deployment).wait() endpoint.traffic = {"demo": 100} workspace_ml_client.online_endpoints.begin_create_or_update(endpoint).result()Este código implementa o modelo no seu endpoint com 2 instâncias de VM Standard_DS3_v2. A implantação inclui sondas de vivacidade e prontidão para monitorização da saúde. O tráfego está definido para 100% nesta implementação. A operação demora vários minutos a ser concluída. Quando terminado, o seu modelo está pronto para aceitar pedidos de inferência.
Referência:GerenciadoOnlineDeployment, Configurações de Sonda, online_deployments.begin_create_or_update
Realizar inferência sobre a implantação
Precisas de dados JSON de exemplo para testar a inferência. Crie um ficheiro nomeado
sample_score.jsonno seu diretório de trabalho com o seguinte conteúdo:{ "inputs": { "question": [ "Where do I live?", "Where do I live?", "What's my name?", "Which name is also used to describe the Amazon rainforest in English?" ], "context": [ "My name is Wolfgang and I live in Berlin", "My name is Sarah and I live in London", "My name is Clara and I live in Berkeley.", "The Amazon rainforest (Portuguese: Floresta Amaz\u00f4nica or Amaz\u00f4nia; Spanish: Selva Amaz\u00f3nica, Amazon\u00eda or usually Amazonia; French: For\u00eat amazonienne; Dutch: Amazoneregenwoud), also known in English as Amazonia or the Amazon Jungle, is a moist broadleaf forest that covers most of the Amazon basin of South America. This basin encompasses 7,000,000 square kilometres (2,700,000 sq mi), of which 5,500,000 square kilometres (2,100,000 sq mi) are covered by the rainforest. This region includes territory belonging to nine nations. The majority of the forest is contained within Brazil, with 60% of the rainforest, followed by Peru with 13%, Colombia with 10%, and with minor amounts in Venezuela, Ecuador, Bolivia, Guyana, Suriname and French Guiana. States or departments in four nations contain \"Amazonas\" in their names. The Amazon represents over half of the planet's remaining rainforests, and comprises the largest and most biodiverse tract of tropical rainforest in the world, with an estimated 390 billion individual trees divided into 16,000 species." ] } }Inferência com
sample_score.json. Muda a localização do ficheiro de pontuação no código seguinte, com base no local onde guardaste o ficheiro JSON de amostra.import json scoring_file = "./sample_score.json" response = workspace_ml_client.online_endpoints.invoke( endpoint_name=online_endpoint_name, deployment_name="demo", request_file=scoring_file, ) response_json = json.loads(response) print(json.dumps(response_json, indent=2))Este código envia as perguntas de exemplo e o contexto para o modelo implementado e imprime as respostas. O modelo realiza perguntas e respostas extraindo texto relevante do contexto fornecido. O resultado esperado inclui o texto da resposta e as pontuações de confiança para cada pergunta.
Referência:online_endpoints.invoke
Configurar o autoescalonamento
Para configurar o autoescalonamento para implementações, siga estes passos:
- Inicie sessão no portal Azure.
- Localiza o tipo de recurso Azure
Machine learning online deploymentpara o modelo que acabaste de implementar no grupo de recursos do projeto de IA. - Seleciona Definições>de Escalonamento no painel esquerdo.
- Seleciona Custom autoscale e configura as definições de autoscale. Para mais informações sobre dimensionamento automático, consulte endpoints online de dimensionamento automático na documentação do Azure Machine Learning.
Eliminar a implementação
Para eliminar implementações no portal Foundry, selecione Eliminar implementação no painel superior da página de detalhes da implementação.
Considerações de quotas
Para implementar e realizar inferências com endpoints em tempo real, consome a quota central da Máquina Virtual (VM) que o Azure atribui à sua subscrição por região. Quando se inscreve na Foundry, recebe uma quota padrão de VMs para várias famílias de VMs disponíveis na região. Pode continuar a criar implantações até atingir o limite da sua quota. Quando isso acontecer, pode pedir um aumento da quota.
Resolução de problemas
Esta secção apresenta soluções para problemas comuns que pode encontrar ao implementar modelos com computação gerida.
A implementação falha com erro de quota excedida
Problema: Recebe um erro a indicar quota insuficiente ao criar uma implementação.
Solução:
- Verifique a utilização atual da sua quota no portal Azure nas definições de quota da sua subscrição
- Solicite um aumento de quota através do portal do Azure para o SKU VM específico de que precisa
- Considere usar um SKU de VM diferente que tenha uma quota disponível
- Consulte Gerenciar e aumentar quotas para recursos com Azure Machine Learning para orientações detalhadas
Erros de autenticação ao invocar o endpoint
Questão: Recebe erros de autenticação (401 Não autorizado) ao ligar ao endpoint implementado.
Solução:
- Confirme que está a usar o URI de endpoint correto e a chave de autenticação na página de detalhes de implementação
- Verifica se a chave não foi regenerada desde que a copiaste
- Certifique-se de que as permissões do Azure RBAC não mudaram
- Para chamadas SDK, confirme que o seu objeto credencial está devidamente inicializado
O provisionamento de implementação falha ou expira
Questão: A implementação mantém-se em estado de provisionamento por um período prolongado ou falha com um erro de timeout.
Solução:
- Consulte os registos de implementação no portal Foundry para mensagens de erro específicas
- Verifique se as definições de rede gerida do seu hub permitem o acesso aos recursos necessários
- Certifique-se de que o ID do modelo está correto e que o modelo ainda está disponível no catálogo
- Tenta implementar com um SKU de VM diferente ou reduzir o número de instâncias
O modelo devolve respostas inesperadas ou incorretas
Questão: O modelo implementado responde, mas devolve resultados inesperados.
Solução:
- Verifique se o formato dos seus dados de entrada corresponde ao esquema esperado do modelo
- Consulte a documentação da placa de modelo para especificações de entrada/saída
- Teste com os dados de exemplo fornecidos na documentação do modelo
- Consulte o pedido e a resposta no separador de Testes do portal Foundry
Para assistência adicional na solução de problemas, consulte Solução de problemas na implementação de endpoints online.