Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Esses recursos e aprimoramentos da plataforma Azure Databricks foram lançados em fevereiro de 2019.
Observação
As versões são disponibilizadas em fases. Talvez sua conta do Azure Databricks só seja atualizada uma semana após a data de lançamento inicial.
Databricks Light disponível para o público geral
26 de fevereiro – 5 de março de 2019: versão 2.92
O Databricks Light (também conhecido como Data Engineering Light) já está disponível. A Databricks Light é a versão empacotada pelo Databricks do ambiente de execução do Apache Spark de código aberto. Ele fornece uma opção de runtime para trabalhos que não precisam dos benefícios avançados de desempenho, confiabilidade ou dimensionamento automático fornecidos pelo Databricks Runtime. Você pode selecionar apenas o Databricks Light ao criar um cluster para executar um trabalho JAR, Python ou Spark-Submit; não é possível selecionar esse tempo de execução para clusters nos quais você executa cargas de trabalho interativas ou de notebook. Confira Databricks Light.
Pré-Visualização Pública do MLflow Gerenciado no Azure Databricks
26 de fevereiro – 5 de março de 2019: versão 2.92
O MLflow é uma plataforma de fonte aberta para gerenciar o ciclo de vida de machine learning de ponta a ponta. Ele aborda três funções principais:
- Acompanhar experimentos para registrar e comparar parâmetros e resultados.
- Gerenciar e implantar modelos de uma variedade de bibliotecas de Machine Learning para diversas plataformas de inferência e serviço de modelos.
- Empacotar o código de ML em um formato reutilizável e reproduzível para compartilhá-lo com outros cientistas de dados ou transferi-lo para produção.
O Azure Databricks agora oferece uma versão do MLflow totalmente gerenciada e hospedada, integrada aos recursos de segurança corporativa, alta disponibilidade e outros recursos do workspace do Azure Databricks, como gerenciamento de experimentos, gerenciamento de execuções e captura de revisão de notebooks. O MLflow no Azure Databricks oferece uma experiência integrada para acompanhamento e proteção de execuções de treinamento de modelo de machine learning e execução de projetos de Machine Learning. Ao usar o MLflow gerenciado no Azure Databricks, você obterá as vantagens das duas plataformas, incluindo:
- Workspaces: Acompanhe e organize de maneira colaborativa experimentos e resultados dentro do Azure Databricks Workspaces com um MLflow Tracking Server hospedado e uma interface de usuário de experimentos integrada. Quando você usa o MLflow em notebooks, o Azure Databricks captura automaticamente as revisões do notebook para que você possa reproduzir o mesmo código e executá-lo posteriormente.
- Segurança: aproveite um modelo de segurança comum para todo o ciclo de vida de ML por meio de ACLs.
- Jobs: execute projetos do MLflow como jobs do Azure Databricks remotamente e diretamente em notebooks do Azure Databricks.
Aqui está uma demonstração de um fluxo de trabalho de acompanhamento em um Workspace do Azure Databricks:

Para obter detalhes, consulte Monitore o desenvolvimento de modelos usando o MLflow.
O conector do Azure Data Lake Storage está disponível de forma geral
15 de fevereiro de 2019
O ADLS (Azure Data Lake Storage), a solução data lake de última geração para análise de Big Data, agora é GA, assim como o conector do ADLS para o Azure Databricks. Também temos o prazer de anunciar que o ADLS dá suporte ao Databricks Delta quando você estiver executando clusters no Databricks Runtime 5.2 e superior.
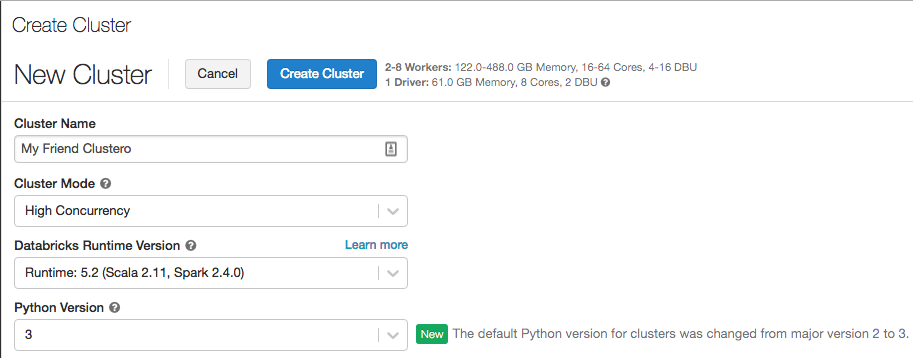
O Python 3 agora é o padrão quando você cria clusters
12 a 19 de fevereiro de 2019: versão 2.91
A versão padrão do Python para clusters criados por meio da interface do usuário mudou do Python 2 para o Python 3. O padrão para clusters criados por meio da API REST ainda é o Python 2.
Os clusters existentes não vão alterar as respectivas versões do Python. Mas se você tem o hábito de usar o padrão python 2 ao criar novos clusters, precisará começar a prestar atenção à seleção de versão do Python.
Delta Lake disponível para o público geral
1º de fevereiro de 2019
Agora todos podem obter os benefícios da poderosa camada de armazenamento transacional do Databricks Delta e leituras super rápidas: a partir de 1º de fevereiro, o Delta Lake é GA e está disponível em todas as versões com suporte do Databricks Runtime. Para obter informações sobre a Delta, consulte o que é o Delta Lake no Azure Databricks?.