Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Os Aplicativos do Databricks permitem que você crie e implante aplicativos interativos diretamente em seu workspace Azure Databricks. Adicionar o Lakebase como um recurso fornece ao seu aplicativo um back-end do Postgres totalmente gerenciado. Azure Databricks cria um principal de serviço para seu aplicativo, concede a ele um papel correspondente no PostgreSQL e injeta detalhes de conexão como variáveis de ambiente. Seu aplicativo se conecta a um banco de dados Postgres totalmente gerenciado sem gerenciar credenciais ou cadeias de conexão.

Este tutorial orienta você pela implantação de um aplicativo de modelo conectado a um banco de dados do Lakebase. No final, você terá um aplicativo em execução com dados que poderá inspecionar e consultar diretamente do Lakebase e, opcionalmente, registrar-se no Catálogo do Unity junto com seus dados do lakehouse.
Pré-requisitos
Antes de começar, certifique-se de que você tenha o seguinte:
- Acesso a um workspace Azure Databricks com Lakebase e computação sem servidor habilitados. Contate o administrador do workspace, se necessário.
- Permissão para criar recursos e aplicativos de computação.
Etapa 1: Provisionar uma instância do Lakebase
Um projeto do Lakebase é uma instância gerenciada do Postgres à qual seu aplicativo se conecta como um recurso. Os projetos são organizados em branches, cada um representando um ambiente de banco de dados isolado.
Para criar um projeto do Lakebase, consulte Obter um banco de dados Postgres. O Lakebase cria seu projeto com um production branch e um banco de databricks_postgres dados.
Etapa 2: Criar um aplicativo do Databricks
Azure Databricks fornece três modelos de aplicativos de dimensionamento automático que demonstram a integração com o Lakebase usando um aplicativo de tarefas: Dash, Flask e Streamlit. Para criar um aplicativo a partir de um modelo:
- No seu workspace do Azure Databricks, clique no seletor de aplicativos
 e selecione Databricks Apps.
e selecione Databricks Apps. - Clique em + Criar aplicativo.
- Selecione seu modelo preferencial na guia Banco de Dados .
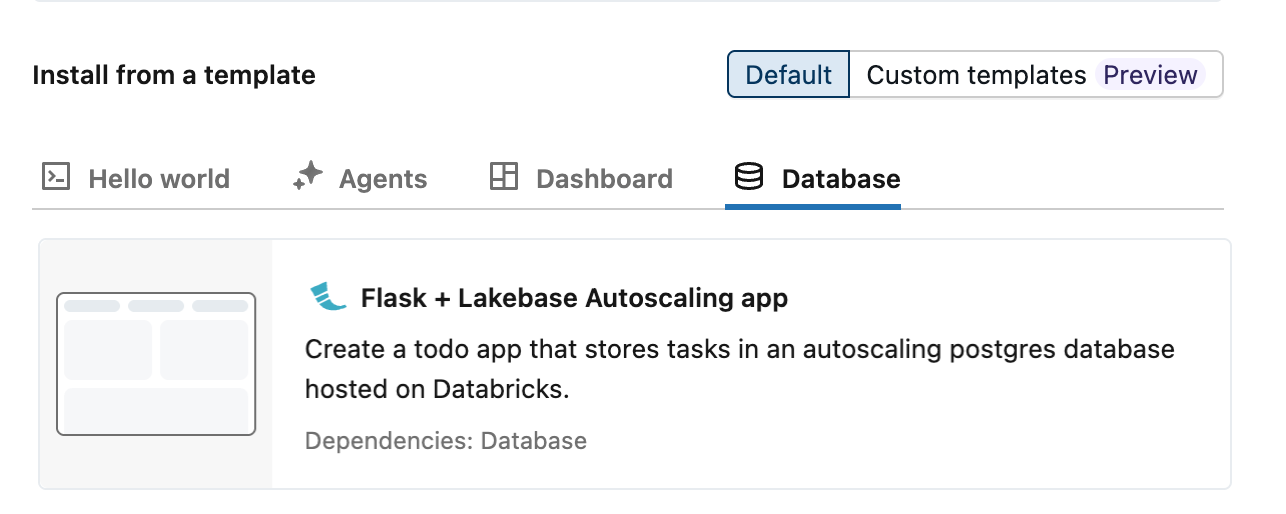
Etapa 3: Configurar um recurso de banco de dados
Adicionar o Lakebase como um recurso cria uma entidade de serviço com as permissões de banco de dados corretas e injeta os detalhes da conexão como variáveis de ambiente no aplicativo. Isso permite que o modelo se conecte ao banco de dados automaticamente, sem nenhuma cadeia de conexão em seu código.
Na etapa Configurar , defina as seguintes configurações.
- Para recursos de aplicativo, selecione seu projeto, branch e banco de dados do Lakebase. Os nomes de ramificação aparecem como IDs. Para corresponder IDs a nomes, consulte a página de branches do projeto.
- Para tamanho de computação, selecione Médio. Isso controla a computação do servidor de aplicativos, que é separada da computação do banco de dados lakebase e é dimensionada de forma independente.

Para obter mais informações, consulte Adicionar um recurso do Lakebase a um aplicativo do Databricks.
Etapa 4: Examinar autorizações
Cada aplicativo do Databricks é executado como sua própria entidade de serviço, uma identidade dedicada separada de qualquer usuário específico. Quando você conecta o Lakebase como um recurso, o Azure Databricks cria uma função Postgres equivalente para esse principal de serviço e concede acesso completo ao banco de dados. Nenhuma configuração de função manual é necessária.

Etapa 5: Nomear seu aplicativo e instalar
O Lakebase usa o nome do aplicativo para gerar um nome de esquema no formato {app-name}_schema_{service-principal-id} (hifens removidos da ID). Você não pode alterar o nome do aplicativo após a criação, mas pode renomear o esquema mais tarde. O modelo usa lakebase-autoscaling-appcomo padrão .
Clique em Criar aplicativo para criar o aplicativo.
Etapa 6: Implantar o aplicativo
Depois de criar o aplicativo, a computação é iniciada automaticamente e seu aplicativo é implantado em cerca de 2 a 3 minutos sem nenhuma ação adicional. Quando o status do aplicativo mostrar Em execução, clique na URL ao lado dele para abrir seu aplicativo.

Etapa 7: Verificar a integração
Adicione alguns todos em seu aplicativo. Em seu projeto do Lakebase, abra Tabelas e selecione a tabela todos no esquema do aplicativo. A entidade de serviço do aplicativo escreveu essas linhas usando os detalhes da conexão injetados na Etapa 3.

Para consultar os dados diretamente, use o Editor de SQL em seu projeto do Lakebase. Como o Lakebase escalona para zero quando ocioso, a primeira consulta após uma longa pausa pode demorar alguns segundos para responder. Para outras opções de conexão, consulte Conectar-se ao banco de dados.
Etapa 8: Consultar por meio do Catálogo do Unity (opcional)
Por padrão, os dados do Lakebase do aplicativo são acessíveis diretamente por meio de conexões do Postgres. Registrar no Catálogo Unity torna-o consultável junto com seus dados no lakehouse, usando o SQL padrão do Databricks. Em seguida, você pode unir as tabelas de transações do aplicativo com as tabelas Delta na mesma consulta.
Para se registrar, abra o Gerenciador de Catálogos e crie um novo catálogo. Selecione Lakebase Postgres como o tipo de catálogo, escolha Autoescalonamento e selecione o mesmo projeto e ramo que seu aplicativo. Consulte Registrar seu banco de dados no Catálogo do Unity para obter detalhes completos.
Observe que os nomes de esquema no Catálogo do Unity preservam os hífens do nome do aplicativo. Os nomes de catálogo e de esquema exigem aspas de crase (backtick).
SELECT * FROM `your-catalog-name`.`lakebase-autoscaling-app_schema_aeb6ff9198ff4752af7dfc6d4cf570d0`.todos;