Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Saiba como criar um novo pipeline usando o Lakeflow Spark Declarative Pipelines (SDP) para orquestração de dados e carregador automático. Este tutorial estende o pipeline de exemplo limpando os dados e criando uma consulta para localizar os 100 principais usuários.
Neste tutorial, você aprenderá a usar o Editor do Lakeflow Pipelines para:
- Crie um pipeline com a estrutura de pastas padrão e comece com um conjunto de arquivos de exemplo.
- Defina restrições de qualidade de dados usando expectativas.
- Use os recursos do editor para adicionar uma nova transformação ao pipeline para realizar a análise dos seus dados.
Requirements
Antes de iniciar este tutorial, você deve:
- Esteja logado em um workspace do Azure Databricks.
- Habilite o Catálogo do Unity para seu workspace.
- Tenha permissão para criar um recurso de computação ou acesso a um recurso de computação.
- Tenha permissões para criar um novo esquema em um catálogo. As permissões necessárias são
ALL PRIVILEGESouUSE CATALOG.CREATE SCHEMA
Etapa 1: Criar um pipeline
Nesta etapa, você criará um pipeline usando a estrutura de pastas padrão e os exemplos de código. Os exemplos de código fazem referência à tabela users na fonte de dados exemplo wanderbricks.
No workspace Azure Databricks, clique em
 New, em seguida,
New, em seguida,  ETL pipeline. Isso abre o editor de pipeline com um nome de pipeline padrão como
ETL pipeline. Isso abre o editor de pipeline com um nome de pipeline padrão como New Pipeline <date> <time>.(Opcional) Selecione o nome e insira um nome descritivo para o pipeline.
(Opcional) À direita do nome, clique no catálogo e no esquema para definir padrões diferentes.
(Opcional) No arquivo de origem
my_transformationcriado para você, selecione Python ou SQL na lista suspensa de idiomas para definir o idioma do arquivo.Clique
 Use o código de exemplo.
Use o código de exemplo.O código de exemplo no idioma selecionado aparece no arquivo de origem
my_transformationnatransformationspasta. Os conjuntos de dados de saída ainda não foram criados e o grafo pipeline no lado direito da tela está vazio.Para executar o código de pipeline (o código na pasta), clique em
transformationsExecutar pipeline na parte superior direita da tela.Após a conclusão da execução, a parte inferior do workspace mostra as duas novas tabelas que foram criadas
sample_users_<date_time>esample_aggregation_<date_time>. O gráfico do pipeline no lado direito do espaço de trabalho agora mostra as duas tabelas, incluindo quesample_usersé a origem desample_aggregation. Anote o nome completosample_users_<date_time>da tabela , você faz referência a ela na próxima etapa.
Etapa 2: Aplicar verificações de qualidade de dados
Nesta etapa, você adicionará uma verificação de qualidade de dados à tabela sample_users. Você usa as expectativas de pipeline para restringir os dados. Nesse caso, você exclui todos os registros de usuário que não têm um endereço de email válido e gera a tabela limpa como users_cleaned.
No navegador de ativos do pipeline à esquerda, clique no
e selecione Transformação.Na caixa de diálogo Criar arquivo de transformação , faça as seguintes seleções:
- Escolha Python ou SQL para o Language. Isso não precisa corresponder à seleção anterior.
- Dê um nome ao arquivo. Nesse caso, escolha
users_cleaned. - Para o caminho de destino, deixe o padrão.
- Para o tipo de conjunto de dados, deixe-o como Nenhum selecionado ou escolha o modo de exibição Materializado. Se você selecionar a exibição Materializada, ela gerará um código de exemplo para você.
Clique em Criar para criar o arquivo de código de transformação.
No novo arquivo de código, edite o código para corresponder ao seguinte (use SQL ou Python, com base na seleção na tela anterior). Substitua
sample_users_<date_time>pelo nome completo da tabelasample_usersda seção anterior.SQL
-- Drop all rows that do not have an email address CREATE MATERIALIZED VIEW users_cleaned ( CONSTRAINT non_null_email EXPECT (email IS NOT NULL) ON VIOLATION DROP ROW ) AS SELECT * FROM sample_users_<date_time>;Python
from pyspark import pipelines as dp # Drop all rows that do not have an email address @dp.materialized_view @dp.expect_or_drop("no null emails", "email IS NOT NULL") def users_cleaned(): return ( spark.read.table("sample_users_<date_time>") )Clique em Executar pipeline para atualizar o pipeline. Agora o sistema deve ter três tabelas.
Etapa 3: Analisar os principais usuários
Em seguida, obtenha os 100 principais usuários pelo número de reservas que eles criaram. Junte a wanderbricks.bookings tabela à exibição users_cleaned materializada.
No navegador de ativos do pipeline à esquerda, clique no
e selecione Transformação.Na caixa de diálogo Criar arquivo de transformação , faça as seguintes seleções:
- Escolha Python ou SQL para o Language. Isso não precisa corresponder às seleções anteriores.
- Dê um nome ao arquivo. Nesse caso, escolha
users_and_bookings. - Para o caminho de destino, deixe o padrão.
- Para o tipo de conjunto de dados, deixe-o como Nenhum selecionado.
Clique em Criar para criar o arquivo de código de transformação.
No novo arquivo de código, edite o código para corresponder ao seguinte (use SQL ou Python, com base na seleção na tela anterior).
SQL
-- Get the top 100 users by number of bookings CREATE OR REFRESH MATERIALIZED VIEW users_and_bookings AS SELECT u.name AS name, COUNT(b.booking_id) AS booking_count FROM users_cleaned u JOIN samples.wanderbricks.bookings b ON u.user_id = b.user_id GROUP BY u.name ORDER BY booking_count DESC LIMIT 100;Python
from pyspark import pipelines as dp from pyspark.sql.functions import col, count, desc # Get the top 100 users by number of bookings @dp.materialized_view def users_and_bookings(): return ( spark.read.table("users_cleaned") .join(spark.read.table("samples.wanderbricks.bookings"), "user_id") .groupBy(col("name")) .agg(count("booking_id").alias("booking_count")) .orderBy(desc("booking_count")) .limit(100) )Clique em Executar pipeline para atualizar os conjuntos de dados. Quando a execução for concluída, você poderá ver no Pipeline Graph que há quatro tabelas, incluindo a nova
users_and_bookingstabela.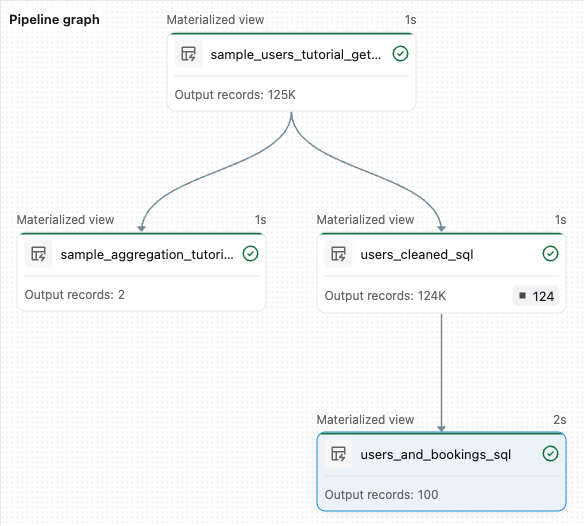
Próximas etapas
Agora que você aprendeu a usar alguns dos recursos do editor de pipelines do Lakeflow e criou um pipeline, aqui estão alguns outros recursos para saber mais sobre:
Ferramentas para trabalhar e depurar transformações na criação de pipelines:
- Execução seletiva
- Visualizações de dados
- Grafo interativo do pipeline (grafo dos conjuntos de dados no seu pipeline)
Integração interna de Pacotes de Automação Declarativa para colaboração eficiente, controle de versão e integração de CI/CD diretamente do editor: