Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Este artigo descreve como usar o Editor do Lakeflow Pipelines para desenvolver e depurar pipelines de ETL (extração, transformação e carregamento) no Lakeflow Spark Declarative Pipelines (SDP).
O que é o Editor do Lakeflow Pipelines?
O Editor do Lakeflow Pipelines é um IDE criado para desenvolver pipelines. Ele combina todas as tarefas de desenvolvimento de pipeline em uma única superfície, oferecendo suporte a fluxos de trabalho de primeiro código, organização de código baseada em pastas, execução seletiva, visualizações de dados e grafos de pipeline. Integrado à plataforma do Azure Databricks, ele também habilita o controle de versão, revisões de código e execuções agendadas.
Visão geral da interface do usuário do Editor do Lakeflow Pipelines
A imagem a seguir mostra o Editor do Lakeflow Pipelines:

A imagem mostra os seguintes recursos:
- Navegador de ativos de pipeline: criar, excluir, renomear e organizar ativos de pipeline. Também inclui atalhos para a configuração do pipeline.
- Editor de código de vários arquivos com guias: trabalhe em vários arquivos de código associados a um pipeline.
- Barra de ferramentas específica do pipeline: inclui opções de configuração do pipeline e possui ações de execução no nível do pipeline.
- Gráfico interativo do pipeline: Obtenha uma visão geral de suas tabelas, abra a barra inferior de visualização de dados e execute outras ações relacionadas às tabelas.
- Insights de execução no nível da tabela: obtenha insights de execução para todas as tabelas ou uma única tabela em um pipeline. Os insights referem-se à execução de pipeline mais recente.
- Painel de problemas: esse recurso resume erros, avisos e insights em todos os arquivos no pipeline e você pode navegar até onde o erro ocorreu dentro de um arquivo específico. Ele complementa indicadores de erro associados ao código.
- Execução seletiva: o editor de código tem recursos para desenvolvimento passo a passo, como a capacidade de atualizar apenas as tabelas no arquivo atual usando a ação Executar arquivo ou atualizar uma única tabela.
-
 Genie Code: Crie, atualize e depure seus pipelines usando o Genie Code, uma experiência com agente de IA que automatiza fluxos de trabalho de várias etapas, desde a descoberta de dados e a geração de código até a execução de pipelines e a resolução de problemas de qualidade dos dados.
Genie Code: Crie, atualize e depure seus pipelines usando o Genie Code, uma experiência com agente de IA que automatiza fluxos de trabalho de várias etapas, desde a descoberta de dados e a geração de código até a execução de pipelines e a resolução de problemas de qualidade dos dados.
Outros recursos importantes:
- Visualização de dados: inspecione os dados das tabelas de streaming e as exibições materializadas.
- Estrutura de pastas de pipeline padrão: novos pipelines incluem uma estrutura de pasta predefinida e um código de exemplo que você pode usar como ponto de partida para o pipeline.
Criar um novo pipeline de ETL
Para criar um pipeline ETL usando o Editor do Lakeflow Pipelines, siga estas etapas:
Na parte superior da barra lateral, clique em
 Novo e, em seguida, selecione
Novo e, em seguida, selecione  ETL pipeline.
ETL pipeline.Um pipeline é criado automaticamente com as seguintes configurações padrão:
Você pode ajustar essas configurações na barra de ferramentas do pipeline.
Na parte superior, dê um nome exclusivo ao pipeline.
Ao lado do nome, o catálogo padrão e o esquema escolhidos para você são exibidos.
O catálogo padrão e o esquema padrão são onde os conjuntos de dados são lidos ou gravados quando você não qualifica conjuntos de dados com um catálogo ou esquema em seu código. Consulte objetos de banco de dados no Azure Databricks para obter mais informações.
Clique no catálogo e no esquema para alterar os valores padrão do seu pipeline.
Seu pipeline tem, por padrão, um arquivo
my_transformationem branco. Alterne este arquivo entre Python e SQL escolhendo uma opção no menu suspenso de linguagem. Escreva código neste arquivo diretamente ou escolha uma das seguintes opções para começar rapidamente:-
Crie usando o Genie Code: descreva seu pipeline usando linguagem natural e deixe o Genie Code criá-lo para você.
- Use o código de exemplo: crie uma estrutura de pasta padrão e um código de exemplo no idioma do arquivo atual.
Para opções mais avançadas, expanda o menu
 (à direita do botão
(à direita do botão  Usar código de exemplo) para:
Usar código de exemplo) para:- Adicione o código-fonte existente: associe seu pipeline a arquivos de código já disponíveis em seu workspace, incluindo pastas Git.
- Configurar com controle de código-fonte: use um projeto de pacotes de automação declarativa para controle de código-fonte e suporte a CI/CD.
- Use o metastore do Hive: crie um pipeline com configurações herdadas.
-
Como alternativa, você pode criar um pipeline de ETL no navegador do workspace:
- Clique no Workspace no painel esquerdo.
- Selecione qualquer pasta, incluindo pastas Git.
- Clique em Criar no canto superior direito e clique em pipeline ETL.
Você também pode criar um pipeline de ETL na página de tarefas e pipelines:
- No seu espaço de trabalho, clique no
 Tarefas e Pipelines na barra lateral.
Tarefas e Pipelines na barra lateral. - Em Novo, clique Pipeline ETL.
Dica
A CLI do Databricks fornece comandos para criar, modificar e gerenciar seus pipelines do Lakeflow Spark Declarative Pipelines de um terminal. Consulte pipelines o grupo de comandos.
Abrir um pipeline de ETL existente
Há várias maneiras de abrir um pipeline ETL existente no Editor do Lakeflow Pipelines:
Abra qualquer arquivo de origem associado ao pipeline:
- Clique em Workspace no painel lateral.
- Navegue até uma pasta com arquivos de código-fonte para o pipeline.
- Clique no arquivo de código-fonte para abrir o pipeline no editor.
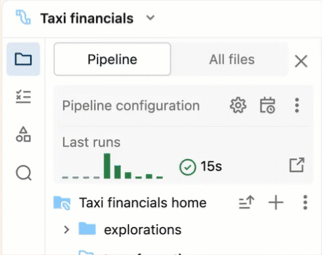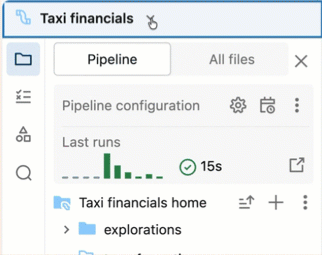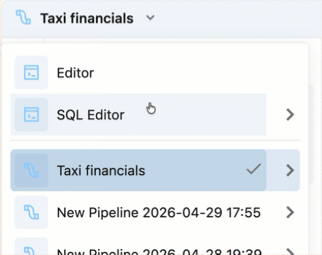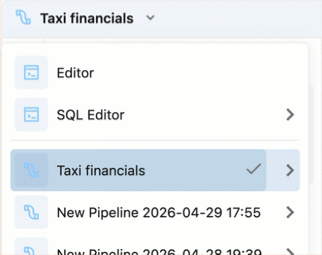
Abra um pipeline editado recentemente:
- No editor, você pode navegar até outros pipelines que editou recentemente clicando no nome do pipeline na parte superior do navegador de ativos e escolhendo outro pipeline na lista de recentes exibida.
- Fora do editor, na página Recentes da barra lateral esquerda, abra um pipeline ou um arquivo configurado como o código-fonte de um pipeline.
Ao exibir um pipeline no contexto do produto, você pode optar por editar o pipeline.
- Na página de monitoramento de pipeline, clique em
 Editar pipeline.
Editar pipeline. - Na página Jobs & Pipelines, na barra lateral esquerda, clique no para editar o pipeline.
- Ao editar um trabalho e adicionar uma tarefa de pipeline, você pode clicar no ícone de abrir em nova guia ao escolher um pipeline na seção
 Pipeline.
Pipeline.
- Na página de monitoramento de pipeline, clique em
Se você estiver navegando todos os arquivos no navegador de ativos e abrir um arquivo de código-fonte de outro pipeline, uma faixa será mostrada na parte superior do editor, solicitando que você abra esse pipeline associado.
Navegador de ativos do pipeline
Quando você está editando um pipeline, a barra lateral esquerda do espaço de trabalho usa um modo especial chamado navegador de recursos do pipeline. Por padrão, o navegador de ativos do pipeline foca na raiz do pipeline e nas pastas e arquivos contidos nela. Você também pode optar por exibir Todos os arquivos para ver arquivos fora da raiz do pipeline. As guias que estavam abertas no editor de pipeline durante a edição de um pipeline específico são lembradas e, quando você alterna para outro pipeline, as guias que estavam abertas na última vez que você editou aquele pipeline são restauradas.
Observação
O editor também tem contextos para editar arquivos SQL ( chamados de Editor de SQL do Databricks) e um contexto geral para editar arquivos de workspace que não são arquivos SQL ou arquivos de pipeline. Cada um desses contextos lembra e restaura as abas que você tinha aberto na última vez que utilizou aquele contexto. Você pode alternar o contexto da parte superior da barra lateral esquerda. Clique no cabeçalho para escolher entre Workspace, Editor de SQL ou pipelines editados recentemente.
Quando você abre um arquivo da página do navegador Workspace, ele é aberto no editor correspondente para esse arquivo. Se o arquivo estiver associado a um pipeline, esse será o Editor do Lakeflow Pipelines.
Para abrir um arquivo que não faz parte do pipeline, mas preservando o contexto do pipeline, abra o arquivo pela guia Todos os arquivos do navegador de ativos.
O navegador de ativos do pipeline tem duas guias:
- Pipeline: é aqui que você pode encontrar todos os arquivos associados ao pipeline. Você pode criar, excluir, renomear e organizá-los em pastas. Essa guia também inclui atalhos para configuração de pipeline e uma exibição gráfica de execuções recentes.
- Todos os arquivos: todos os outros ativos do workspace estão disponíveis aqui. Isso pode ser útil para localizar arquivos a serem adicionados ao pipeline ou exibir outros arquivos relacionados ao pipeline, como um arquivo YAML que define um Pacotes de Automação Declarativa.

Você pode ter os seguintes tipos de arquivos em seu pipeline:
- Arquivos de código-fonte: esses arquivos fazem parte da definição de código-fonte do pipeline, que pode ser vista em Configurações. O Databricks recomenda sempre armazenar arquivos de código-fonte dentro da pasta raiz do pipeline; caso contrário, eles são mostrados em uma seção de arquivo externo na parte inferior do navegador e têm um conjunto de recursos menos avançado.
- Arquivos de código não-fonte: esses arquivos são armazenados dentro da pasta raiz do pipeline, mas não fazem parte da definição do código-fonte do pipeline.
Importante
Você deve usar o navegador de ativos do pipeline na guia Pipeline para gerenciar arquivos e pastas do pipeline. Isso atualiza as configurações do pipeline corretamente. Mover ou renomear arquivos e pastas do navegador do espaço de trabalho ou da guia Todos os arquivos interrompe a configuração do pipeline e, em seguida, você deve corrigi-la manualmente em Configurações.
Pasta raiz
O navegador de recursos do pipeline está vinculado a uma pasta raiz do pipeline. Quando você cria um novo pipeline, a pasta raiz do pipeline é criada na pasta inicial do usuário.
Você pode alterar a pasta raiz no navegador de ativos do pipeline. Isso é útil se você criou um pipeline em uma pasta e, posteriormente, deseja mover tudo para uma pasta diferente. Por exemplo, você criou o pipeline em uma pasta normal e deseja mover o código-fonte para uma pasta Git para controle de versão.
- Clique no menu de estouro da pasta raiz.
- Clique em Configurar nova pasta raiz.
- Na pasta de raiz do pipeline, clique no
 e escolha outra pasta como a pasta de raiz do pipeline.
e escolha outra pasta como a pasta de raiz do pipeline. - Clique em Salvar.
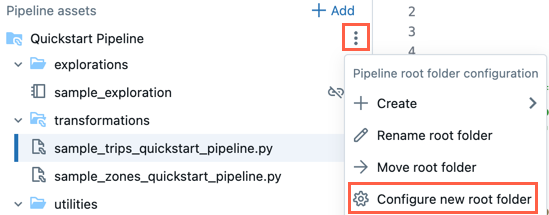
No ![]() Para a pasta raiz, você também pode clicar em Renomear pasta raiz para renomear o nome da pasta. Aqui, você também pode clicar em Mover pasta raiz para mover a pasta raiz, por exemplo, para uma pasta Git.
Para a pasta raiz, você também pode clicar em Renomear pasta raiz para renomear o nome da pasta. Aqui, você também pode clicar em Mover pasta raiz para mover a pasta raiz, por exemplo, para uma pasta Git.
Você também pode alterar a pasta raiz do pipeline nas configurações:
- Clique em Configurações.
- Em Ativos de código , clique em Configurar caminhos.
- Clique no para alterar a pasta na Pasta raiz do pipeline.
- Clique em Salvar.
Observação
Se você alterar a pasta raiz do pipeline, a lista de arquivos exibida pelo navegador de ativos de pipeline será afetada, pois os arquivos na pasta raiz anterior serão mostrados como arquivos externos.
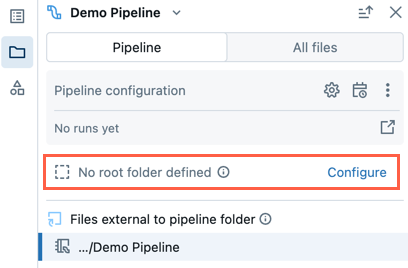
Pipeline existente sem pasta raiz
Um pipeline existente criado usando a experiência de edição do notebook herdado não terá uma pasta raiz configurada. Ao abrir um pipeline que não tenha uma pasta raiz configurada, se você quiser configurar a pasta raiz do pipeline, siga estas etapas:
- No navegador de ativos do pipeline, clique em Configurar.
- Clique no para selecionar a pasta raiz na Pasta raiz do pipeline.
- Clique em Salvar.
Estrutura de pasta padrão
Quando você cria um novo pipeline, uma estrutura de pasta padrão é criada. Essa é a estrutura recomendada para organizar os arquivos de código fonte e não-fonte do seu pipeline, conforme descrito abaixo.
Um pequeno número de arquivos de código de exemplo são criados nesta estrutura de pastas.
| Nome da pasta | Local recomendado para esses tipos de arquivos |
|---|---|
<pipeline_root_folder> |
Pasta raiz que contém todas as pastas e arquivos do pipeline. |
transformations |
Arquivos de código-fonte, como arquivos de código Python ou SQL com definições de tabela. |
explorations |
Arquivos que não são código-fonte, como notebooks, consultas e arquivos de código usados para análise exploratória de dados. |
utilities |
Arquivos de código não-fonte com módulos Python que podem ser importados de outros arquivos de código. Se você escolher o SQL como seu idioma para o código de exemplo, essa pasta não será criada. |
Você pode renomear os nomes das pastas ou alterar a estrutura para ajustar seu fluxo de trabalho. Para adicionar uma nova pasta de código-fonte, siga estas etapas:
- Clique em Adicionar no navegador de ativos do pipeline.
- Clique em Criar pasta de código-fonte do pipeline.
- Insira um nome de pasta e clique em Criar.
Arquivos de código-fonte
Os arquivos de código-fonte fazem parte da definição do código-fonte do pipeline. Quando você executa o pipeline, esses arquivos são avaliados. Arquivos e pastas que fazem parte da definição do código-fonte têm um ícone especial com um minúsculo ícone de pipeline sobreposto.
Para adicionar um novo arquivo de código-fonte:
- Clique no ao lado da pasta raiz.
- Clique em Transformação.
- Insira um nome para o arquivo e selecione Python ou SQL como o Idioma.
- Clique em Criar.
Use os assistentes em linha para começar a escrever código usando o ![]() Genie Code ou para gerar trechos curtos de código para o tipo de conjunto de dados desejado (por exemplo, visualização materializada ou tabela de streaming).
Genie Code ou para gerar trechos curtos de código para o tipo de conjunto de dados desejado (por exemplo, visualização materializada ou tabela de streaming).
Uma transformations pasta para código-fonte é criada por padrão quando você cria um novo pipeline. Essa pasta é o local recomendado para o código-fonte do pipeline, como arquivos de código Python ou SQL com definições de tabela de pipeline.
Arquivos de código não-fonte
Os arquivos de código não-fonte são armazenados dentro da pasta raiz do pipeline, mas não fazem parte da definição do código-fonte do pipeline. Esses arquivos não são avaliados quando você executa o pipeline. Arquivos de código não-fonte não podem ser arquivos externos.
Você pode usá-lo para arquivos relacionados ao seu trabalho no pipeline que você gostaria de armazenar junto com o código-fonte. Por exemplo:
- Notebooks que você usa para explorações ad hoc executadas em computação não Lakeflow Spark Declarative Pipelines fora do ciclo de vida de um pipeline.
- Módulos python que não devem ser avaliados com o código-fonte, a menos que você importe explicitamente esses módulos dentro de seus arquivos de código-fonte.
Para adicionar um novo arquivo de código não-fonte:
- Clique no ao lado da pasta raiz.
- Clique em Exploração ou Utilidade.
- Insira um nome para o arquivo.
- Clique em Criar.
Quando você cria um novo pipeline, as seguintes pastas para arquivos de código não-fonte são criadas por padrão:
| Nome da pasta | Description |
|---|---|
explorations |
Essa pasta é o local recomendado para notebooks, consultas, dashboards e outros arquivos, para então executá-los em computações de Pipelines Declarativos do Spark, exceto no caso do Lakeflow, da mesma forma que você normalmente faria fora do ciclo de execução de um pipeline. |
utilities |
Essa pasta é o local recomendado para módulos Python que podem ser importados de outros arquivos por meio de importações diretas expressas como from <filename> import, desde que a pasta pai esteja hierarquicamente sob a pasta raiz. |
Você também pode importar módulos python localizados fora da pasta raiz, mas nesse caso, você deve acrescentar o caminho da pasta ao sys.path seu código Python:
import sys, os
sys.path.append(os.path.abspath('<alternate_path_for_utilities>/utilities'))
from utils import \*
Arquivos externos
A seção Arquivos externos do navegador de pipeline mostra arquivos de código-fonte fora da pasta raiz.
Para mover um arquivo externo para a pasta raiz, como a transformations pasta, siga estas etapas:
- Clique no do arquivo no navegador de ativos e clique em Mover.
- Escolha a pasta para a qual você deseja mover o arquivo e clique em Mover.
Arquivos associados a vários pipelines
Um selo será mostrado no cabeçalho do arquivo se um arquivo estiver associado a mais de um pipeline. Possui uma contagem de pipelines associados e permite alternar entre eles.
Seção Todos os arquivos
Além da seção Pipeline , há uma seção Todos os arquivos , na qual você pode abrir qualquer arquivo em seu workspace. Aqui, você pode ver:
- Abra arquivos fora da pasta raiz em uma guia sem sair do Editor do Lakeflow Pipelines.
- Navegue até os arquivos de código-fonte de outro pipeline e abra-os. Isso abre o arquivo no editor e exibe um banner com a opção de alternar o foco no editor para este segundo pipeline.
- Mover arquivos para a pasta raiz de pipeline.
- Inclua arquivos fora da pasta raiz na definição do código-fonte do pipeline.
Editar arquivos de origem do pipeline
Quando você abre um arquivo-fonte de um pipeline no navegador do workspace ou no navegador de ativos do pipeline, ele é aberto em uma guia de editor no Editor do Lakeflow Pipelines. Abrir mais arquivos abre guias separadas, permitindo que você edite vários arquivos ao mesmo tempo.
Observação
Abrir um arquivo que não esteja associado a um pipeline do navegador do workspace abrirá o editor em um contexto diferente (o editor geral do Workspace ou, para arquivos SQL, o Editor de SQL).
Quando você abre um arquivo não pipeline na guia Todos os arquivos do navegador de ativos de pipeline, ele é aberto em uma nova guia no contexto do pipeline.
O código-fonte do pipeline inclui vários arquivos. Por padrão, os arquivos de origem estão na pasta transformations no navegador de recursos do pipeline. Os arquivos de código-fonte podem ser arquivos Python (*.py) ou SQL (*.sql). Sua origem pode incluir uma combinação de arquivos Python e SQL em um único pipeline e o código em um arquivo pode fazer referência a uma tabela ou exibição definida em outro arquivo.
Você também pode incluir arquivos markdown (*.md) na pasta de transformações . Os arquivos markdown podem ser usados para documentação ou anotações, mas são ignorados ao executar uma atualização de pipeline.
Os seguintes recursos são específicos para o Editor do Lakeflow Pipelines:
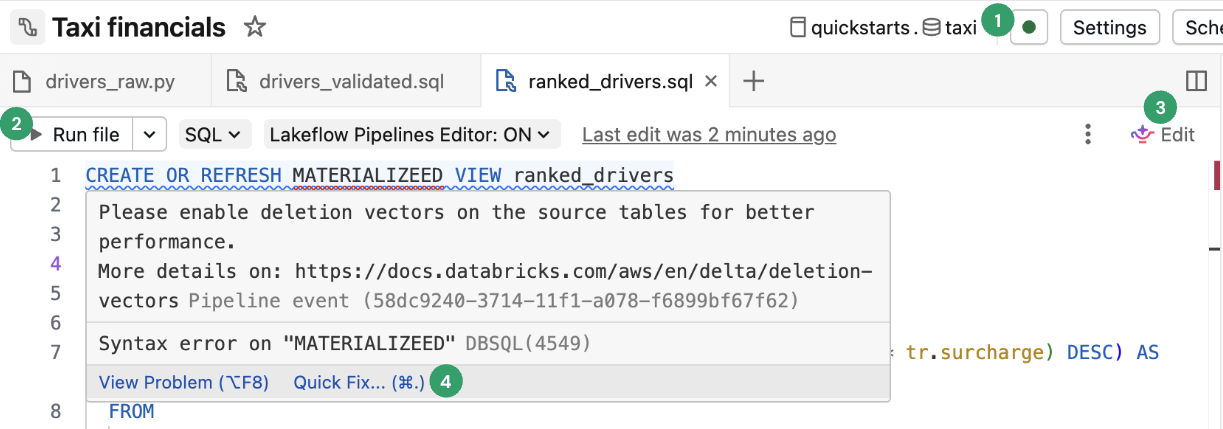
Conectar: conecte-se à computação sem servidor ou clássica para executar o pipeline. Todos os arquivos associados ao pipeline usam a mesma conexão de computação, portanto, uma vez conectado, você não precisa se conectar para outros arquivos no mesmo pipeline. Para obter mais informações sobre opções de computação, consulte opções de configuração de computação.
Para arquivos fora de pipeline, como um notebook exploratório, a opção de conexão está disponível, mas se aplica somente ao arquivo individual.
Executar arquivo: execute o código para atualizar as tabelas definidas neste arquivo de origem. A próxima seção descreve diferentes maneiras de executar seu código de pipeline.
Editar: use o
Genie Code para editar ou adicionar código no arquivo.Correção rápida: Use o
Genie Code para corrigir erros ou agir com base nos insights no seu código.
O painel inferior também se ajusta automaticamente, com base na guia atual. A visualização das informações do pipeline no painel inferior está sempre disponível. Arquivos não associados ao pipeline, como arquivos do editor SQL, também mostram sua saída no painel inferior em uma guia separada. A imagem a seguir mostra um seletor de guia vertical para alternar o painel inferior entre a exibição de informações do pipeline ou informações para o notebook selecionado.

Executar código de pipeline
Você tem quatro opções para executar seu código de pipeline:
Executar todos os arquivos de código-fonte no pipeline
Clique em Executar pipeline ou executar pipeline com atualização de tabela completa para executar todas as definições de tabela em todos os arquivos definidos como código-fonte do pipeline. Para obter detalhes sobre tipos de atualização, consulte a semântica de atualização do pipeline.

Você também pode clicar em Execução seca para validar o pipeline sem atualizar nenhum dado.
Executar o código em um único arquivo
Clique em Executar arquivo ou executar arquivo com atualização de tabela completa para executar todas as definições de tabela no arquivo atual. Os outros arquivos na linha de fluxo não são avaliados.

Essa opção é útil para debugging ao editar e fazer iterações rápidas em um arquivo. Há efeitos colaterais ao executar apenas o código em um único arquivo.
- Quando outros arquivos não são avaliados, erros nesses arquivos não são encontrados.
- Tabelas materializadas em outros arquivos usam a materialização mais recente da tabela, mesmo que haja dados de origem mais recentes.
- Você poderá encontrar erros se uma tabela referenciada ainda não tiver sido materializada.
- O grafo do pipeline pode estar incorreto ou desconexo para tabelas em outros arquivos que não foram materializados. O Azure Databricks faz um esforço melhor para manter o grafo correto, mas não avalia outros arquivos para fazer isso.
Quando você terminar de depurar e editar um arquivo, a Databricks recomenda executar todos os arquivos de código-fonte na pipeline para verificar se ela funciona de ponta a ponta antes de colocá-la em produção.
Executar o código de uma única tabela
Ao lado da definição de uma tabela no arquivo de código-fonte, clique no ícone Executar Tabela
 e escolha Atualizar tabela ou Atualizar tabela completamente na lista suspensa. A execução do código de uma única tabela tem efeitos colaterais semelhantes ao da execução do código em um único arquivo.
e escolha Atualizar tabela ou Atualizar tabela completamente na lista suspensa. A execução do código de uma única tabela tem efeitos colaterais semelhantes ao da execução do código em um único arquivo.
Observação
A execução do código de uma única tabela está disponível para tabelas de streaming e exibições materializadas. Não há suporte para coletores e exibições.
Executar o código para um conjunto de tabelas
Você pode selecionar tabelas no gráfico de pipeline para criar uma lista de tabelas a serem executadas. Passe o mouse sobre a tabela no gráfico de pipeline, clique no
e escolha Selecionar tabela para atualização. Depois de escolher as tabelas a serem atualizadas, escolha a opção Executar ou Executar com atualização completa na parte inferior do gráfico de pipeline.
Executar código selecionado
Realce o código SQL e clique em Executar código selecionado para inspecionar rapidamente as saídas sem materializar os dados. As saídas são exibidas na guia Resultados da Consulta no painel inferior.
Gráfico do pipeline
Depois de executar ou validar todos os arquivos de código-fonte no pipeline, você verá o grafo do pipeline, também chamado de grafo acíclico direcionado (DAG). O grafo mostra o grafo de dependência da tabela. Cada nó tem estados diferentes ao longo do ciclo de vida do pipeline, como validado, em execução ou em erro.

- Gráfico de pipeline: abra o gráfico clicando na guia Gráfico de pipeline no painel inferior.
- Nós: Exibe as dependências das tabelas que fazem parte do seu pipeline, bem como quaisquer métricas relacionadas a elas. Nodos que fazem parte dos arquivos atualmente abertos são realçados no grafo do pipeline. Passar o mouse sobre um nó exibe uma barra de ferramentas com opções, incluindo atualizar a consulta. Clicar com o botão direito do mouse em um nó oferece as mesmas opções em um menu de contexto. Clicar em um nó mostra a visualização de dados e a definição da tabela. Quando você edita um arquivo, as tabelas definidas nesse arquivo são realçadas no grafo.
- Abra na guia: para maximizar o grafo, selecione o ícone no canto superior direito do painel inferior para abri-lo em uma guia separada.
- Mais opções: opções adicionais estão na parte inferior direita, incluindo opções de zoom e mais opções para exibir o grafo em um layout vertical ou horizontal.
Visualizações de dados
A seção de visualização de dados mostra dados de exemplo para uma tabela selecionada.
Você verá uma visualização dos dados da tabela ao clicar em um nó no grafo de pipeline. Para navegar diretamente até a prévia de dados de uma tabela diferente no painel inferior, selecione Voltar ao gráfico ou clique em um nó diferente, se o gráfico do pipeline estiver aberto em uma aba separada.
Como alternativa, vá para a seção Tabelas e clique em Exibir ícone de visualização de dados![]() . Se você escolheu uma tabela, clique em Todas as tabelas para retornar a todas as tabelas.
. Se você escolheu uma tabela, clique em Todas as tabelas para retornar a todas as tabelas.
Ao visualizar os dados da tabela, você pode filtrar ou classificar os dados diretamente. Se você quiser fazer uma análise mais complexa, poderá usar ou criar um bloco de anotações na pasta Explorações (supondo que você manteve a estrutura de pastas padrão). Por padrão, o código-fonte nesta pasta não é executado durante uma atualização de pipeline, portanto, você pode criar consultas sem afetar a saída do pipeline.
Visões sobre execução
Você pode ver as percepções sobre a execução das tabelas na atualização mais recente do pipeline nos painéis na parte inferior do editor.
| Painel | Description |
|---|---|
| Tables | Lista todas as tabelas com seus status e métricas. Se você selecionar uma tabela, verá as métricas e o desempenho dessa tabela e uma guia para a visualização de dados. |
| Performance | Consultar histórico e perfis em todos os fluxos neste pipeline. Você pode acessar métricas de execução e planos de consulta detalhados durante e após a execução. Consulte o histórico de consultas de pipelines para mais informações. |
| Painel de Problemas | Clique no painel para ver uma visualização simplificada de erros, avisos e informações do pipeline. Clique em uma entrada para ver mais detalhes e navegue até o local no código em que o erro ocorreu. Se o erro estiver em um arquivo diferente do exibido no momento, ele redirecionará você para o arquivo em que o erro está. Clique em Exibir detalhes para ver a entrada de log de eventos correspondente para obter detalhes completos. Clique em Exibir logs para ver o log de eventos completo. Clique em Diagnosticar erro para depurar o problema com o Indicadores de erro afixados por código são mostrados para erros associados a uma parte específica do código. Para obter mais detalhes, clique no ícone de erro ou passe o mouse sobre a linha vermelha. Um pop-up com mais informações é exibido. Em seguida, você pode clicar em Correção rápida para revelar um conjunto de ações para solucionar o erro. |
| Log de eventos | Todos os eventos que foram disparados durante a última execução do pipeline. Clique em Exibir logs ou em qualquer entrada na bandeja de problemas. |
Configuração do pipeline
Você pode configurar seu pipeline no editor de pipeline. Você pode fazer alterações nas configurações, no agendamento ou nas permissões do pipeline.
Cada um deles pode ser acessado por um botão no cabeçalho do editor ou através de ícones no navegador de ativos (a barra lateral esquerda).
Configurações (ou escolha o
 no navegador de ativos):
no navegador de ativos):Você pode editar as configurações do pipeline no painel de configurações, incluindo informações gerais, configuração de pasta raiz e código-fonte, configuração de computação, notificações, configurações avançadas e muito mais.
Agendar (ou escolher
 no navegador de ativos):
no navegador de ativos):Você pode criar um ou mais agendamentos para seu pipeline na caixa de diálogo de agendamento. Por exemplo, se você quiser executá-lo diariamente, poderá defini-lo aqui. Ele cria uma tarefa para executar o pipeline no cronograma que você escolher. Você pode adicionar um novo agendamento ou remover um agendamento existente da caixa de diálogo de agendamento.
Compartilhar (ou, no menu
no navegador de ativos, escolha  ):
):Você pode gerenciar permissões no pipeline para usuários e grupos na janela de diálogo de permissões do pipeline.
Log de Eventos
Você pode publicar o log de eventos de um pipeline no Catálogo do Unity. Por padrão, o log de eventos do pipeline é mostrado na interface do usuário e acessível para consulta pelo proprietário.
- Abra Configurações.
- Clique no
 seta ao lado das configurações avançadas.
seta ao lado das configurações avançadas. - Clique em Editar configurações avançadas.
- Em Logs de eventos, clique em Publicar no catálogo.
- Forneça um nome, catálogo e esquema para o log de eventos.
- Clique em Salvar.
Os eventos de pipeline são publicados na tabela especificada por você.
Para saber mais sobre como usar o log de eventos do pipeline, consulte Consultar o log de eventos.
Ambiente de pipeline
Você pode criar um ambiente para o código-fonte adicionando dependências em Configurações.
- Abra Configurações.
- Em Ambiente do pipeline, clique em Editar ambiente.
- Clique em Adicionar dependência para adicionar uma dependência, como se estivesse adicionando-a a um
requirements.txtarquivo. Para obter mais informações sobre dependências, consulte Adicionar dependências ao notebook.
O Databricks recomenda que você fixe a versão com ==. Consulte Pacote PyPI.
O ambiente se aplica a todos os arquivos de código-fonte em seu pipeline.
Notificações
Você pode adicionar notificações usando as configurações do Pipeline.
- Abra Configurações.
- Na seção Notificações , clique em Adicionar notificação.
- Adicione um ou mais endereços de email e os eventos que você deseja que sejam enviados.
- Clique em Adicionar notificação.
Observação
Crie respostas personalizadas a eventos, incluindo notificações ou manipulação personalizada, usando ganchos de evento do Python.
Pipelines de monitoramento
O Azure Databricks também fornece recursos para monitorar pipelines em execução. O editor mostra os resultados e as informações sobre a execução mais recente. Ele é otimizado para ajudá-lo a iterar com eficiência enquanto você desenvolve seu pipeline interativamente.
A página de monitoramento de pipeline permite exibir execuções históricas, o que é útil quando um pipeline está em execução em um agendamento com um Job.
Observação
Há uma experiência de monitoramento padrão e uma experiência de monitoramento de prévia atualizada. A seção a seguir descreve como habilitar ou desabilitar a experiência de monitoramento em visualização. Para obter informações sobre ambas as experiências, consulte Monitorar pipelines na interface do usuário.
A experiência de monitoramento está disponível no botão

Para obter mais informações sobre a página de monitoramento, consulte Monitorar pipelines na interface do usuário. A interface do usuário de monitoramento inclui a capacidade de retornar ao Editor do Lakeflow Pipelines selecionando Editar pipeline no cabeçalho da interface do usuário.
Agente de Engenharia de Dados
Importante
Esse recurso está em Visualização Pública.
O Editor do Lakeflow Pipelines integra-se ao Genie Code Data Engineering Agent, que pode gerar, modificar e depurar pipelines declarativos inteiros do Lakeflow Spark diretamente da linguagem natural. Para obter mais informações, consulte Usar o Genie Code para desenvolvimento de pipeline.
Limitações e problemas conhecidos
Veja as seguintes limitações e problemas conhecidos do editor de pipeline ETL no Lakeflow Spark Declarative Pipelines:
O painel lateral do navegador do workspace não destacará o pipeline se você começar abrindo um arquivo na pasta
explorationsou em um notebook, já que esses arquivos ou notebooks não fazem parte da definição do código-fonte do pipeline.Para entrar no modo de foco do pipeline no navegador da área de trabalho, abra um arquivo associado ao pipeline.
Não há suporte para as visualizações de dados das exibições regulares.
Os módulos do Python não são encontrados de dentro de uma UDF, mesmo que estejam em sua pasta raiz ou estejam na sua
sys.path. Você pode acessar esses módulos anexando o caminho aosys.pathde dentro da UDF, por exemplo:sys.path.append(os.path.abspath(“/Workspace/Users/path/to/modules”))%pip installnão é suportado pelos arquivos (o tipo de ativo padrão com o novo editor). Você pode adicionar dependências nas configurações. Consulte o ambiente do Pipeline.Como alternativa, você pode continuar a usar
%pip installde um notebook associado a um pipeline, em sua definição de código-fonte.
perguntas frequentes
Por que usar arquivos e não notebooks para código-fonte?
A execução baseada em célula de notebooks não é compatível com pipelines. Os recursos padrão dos notebooks são desabilitados ou alterados ao trabalhar com pipelines, o que gera confusão para usuários familiarizados com o comportamento do notebook.
No Editor de Pipelines do Lakeflow, o editor de arquivos é usado como uma base para um editor de alta qualidade para pipelines. Os recursos são direcionados explicitamente a pipelines, como Tabela de execução
, em vez de sobrecarregar recursos familiares com comportamentos diferentes.Ainda posso usar os notebooks como código-fonte?
Sim, você pode. No entanto, alguns recursos, como Executar tabela
ou Executar arquivo, não estão presentes.Se você tiver um pipeline existente usando notebooks, ele ainda funcionará no novo editor. Porém, o Databricks recomenda alternar para arquivos para novos pipelines.
Como posso adicionar código existente a um Pipeline recém-criado?
Você pode adicionar arquivos de código-fonte existentes a um novo pipeline. Para adicionar uma pasta com arquivos existentes, siga estas etapas:
- Clique em Configurações.
- No código-fonte , clique em Configurar caminhos.
- Clique em Adicionar caminho e escolha a pasta para os arquivos existentes.
- Clique em Salvar.
Você também pode adicionar arquivos individuais:
- Clique em Todos os arquivos no navegador de ativos do pipeline.
- Navegue até o arquivo, clique no e clique em Incluir no pipeline.
Considere mover esses arquivos para a pasta raiz do pipeline. Se forem deixados fora da pasta raiz do pipeline, eles serão mostrados na seção Arquivos externos .
Posso gerenciar o código-fonte do Pipeline no Git?
Você pode gerenciar a origem do pipeline no Git escolhendo uma pasta Git ao criar inicialmente o pipeline.
Observação
Gerenciar sua origem em uma pasta Git adiciona controle de versão para o código-fonte. No entanto, para controlar a configuração, o Databricks recomenda usar Pacotes de Automação Declarativa para definir a configuração de pipeline em arquivos de configuração de pacote que podem ser armazenados no Git (ou em outro sistema de controle de versão). Para obter mais informações, consulte o que são pacotes de automação declarativa?.
Se você não criou o pipeline em uma pasta Git inicialmente, poderá mover seu código fonte para uma pasta Git. O Databricks recomenda usar a ação do editor para mover toda a pasta raiz para uma pasta Git. Isso atualiza todas as configurações adequadamente. Consulte a pasta raiz.
Para mover a pasta raiz para uma pasta Git no navegador de ativos do pipeline:
- Clique no para obter a pasta raiz.
- Clique em Mover pasta raiz.
- Escolha um novo local para sua pasta raiz e clique em Mover.
Consulte a seção Pasta raiz para obter mais informações.
Após a movimentação, você verá o ícone familiar do Git ao lado do nome da pasta raiz.
Importante
Para mover a pasta raiz do pipeline, use o navegador de ativos do pipeline e as etapas acima. Movê-lo de outra maneira interrompe as configurações do pipeline e você deve configurar manualmente o caminho correto da pasta em Configurações.
- Clique no
Posso ter vários Pipelines na mesma pasta raiz?
Você pode, mas o Databricks recomenda ter apenas um único Pipeline por pasta raiz.
Quando devo fazer uma corrida seca?
Clique em Execução Seca para verificar seu código sem atualizar as tabelas.
Quando devo usar exibições temporárias e quando devo usar exibições materializadas em meu código?
Use exibições temporárias quando não quiser materializar os dados. Por exemplo, esta é uma etapa em uma sequência de etapas para preparar os dados antes que eles estejam prontos para se materializar usando uma tabela de streaming ou uma exibição materializada registrada no Catálogo.