Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Data Factory no Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA interna e novos recursos. Se você não estiver familiarizado com a integração de dados, comece com Fabric Data Factory. As cargas de trabalho existentes do ADF podem ser atualizadas para Fabric para acessar novos recursos em ciência de dados, análise em tempo real e relatórios.
Você usa atividades de transformação de dados em um pipeline do Data Factory ou do Synapse para transformar e processar dados brutos em previsões e insights. A atividade Script é uma das atividades de transformação compatíveis com os pipelines. Este artigo baseia-se no artigo Transformar dados, que apresenta uma visão geral da transformação de dados e das atividades de transformação compatíveis.
Usando a atividade Script, você pode executar operações comuns com a DML (linguagem de manipulação de dados) e a DDL (linguagem de definição de dados). Instruções DML como INSERT, UPDATE, DELETE e SELECT permitem que os usuários insiram, modifiquem, excluam e recuperem dados no banco de dados. Instruções DDL como CREATE, ALTER e DROP permitem que um gerente de banco de dados crie, modifique e remova objetos de banco de dados, como tabelas, índices e usuários.
Você pode usar a atividade Script para invocar um script SQL em um dos seguintes armazenamentos de dados em sua empresa ou em uma VM (máquina virtual) Azure):
- Banco de Dados do Azure para PostgreSQL (versão 2.0)
- Banco de Dados SQL do Azure
- Azure Synapse Analytics
- banco de dados SQL Server. Se você estiver usando SQL Server, instale o runtime de integração auto-hospedada no mesmo computador que hospeda o banco de dados ou em um computador separado que tenha acesso ao banco de dados. O Integration Runtime (auto-hospedado) é um componente que conecta fontes de dados locais ou em uma VM do Azure aos serviços de nuvem de maneira segura e gerenciada. Confira o artigo Runtime de integração auto-hospedada para obter detalhes.
- Oracle
- Snowflake
O script pode conter uma única instrução SQL ou várias instruções SQL executadas sequencialmente. A tarefa Script pode ser usada para os seguintes propósitos:
- Corte uma tabela em preparação para inserir dados.
- Criar, alterar e descartar objetos de banco de dados como tabelas e exibições.
- Recriar tabelas de fatos e de dimensões antes de carregar dados nelas.
- Executar procedimentos armazenados. Se a instrução SQL invocar um procedimento armazenado que retorne resultados de uma tabela temporária, use a opção de WITH RESULT SETS para definir metadados para o conjunto de resultados.
- Salve o conjunto de linhas retornado de uma consulta como um resultado da atividade para uso posterior.
Detalhes da sintaxe
Este é o formato JSON para definir uma atividade de Script:
{
"name": "<activity name>",
"type": "Script",
"linkedServiceName": {
"referenceName": "<name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"scripts" : [
{
"text": "<Script Block>",
"type": "<Query> or <NonQuery>",
"parameters":[
{
"name": "<name>",
"value": "<value>",
"type": "<type>",
"direction": "<Input> or <Output> or <InputOutput>",
"size": 256
},
...
]
},
...
],
...
]
},
"scriptBlockExecutionTimeout": "<time>",
"logSettings": {
"logDestination": "<ActivityOutput> or <ExternalStore>",
"logLocationSettings":{
"linkedServiceName":{
"referenceName": "<name>",
"type": "<LinkedServiceReference>"
},
"path": "<folder path>"
}
}
}
}
A seguinte tabela descreve essas propriedades JSON:
| Nome da propriedade | Descrição | Obrigatório |
|---|---|---|
| nome | O nome da atividade. | Sim |
| tipo | O tipo de atividade, definido como "Script". | Sim |
| typeProperties | Especifique as propriedades para configurar a atividade Script. | Sim |
| nomeDoServiçoVinculado | O banco de dados de destino em que o script será executado. Ele deve ser uma referência a um serviço vinculado. | Sim |
| scripts | Uma matriz de objetos para representar o script. | Não |
| scripts.text | O texto sem formatação de um bloco de consultas. | Não |
| scripts.type | O tipo do bloco de consultas. Pode ser Query ou NonQuery. Padrão: Query. | Não |
| scripts.parameter | A matriz de parâmetros do script. | Não |
| scripts.parameter.name | O nome do parâmetro. | Não |
| scripts.parameter.value | O valor do parâmetro. | Não |
| scripts.parameter.type | O tipo de dados do parâmetro. O tipo é do tipo lógico e segue o mapeamento de tipo de cada conector. | Não |
| scripts.parameter.direction | A direção do parâmetro. Pode ser Input, Output ou InputOutput. O valor será ignorado se a direção for Output. O tipo ReturnValue não é suportado. Defina o valor retornado de SP como um parâmetro de saída para recuperá-lo. | Não |
| scripts.parameter.size | O tamanho máximo do parâmetro. Aplica-se somente ao parâmetro de direção Output/InputOutput do tipo string/byte[]. | Não |
| scriptBlockExecutionTimeout | O tempo de espera para que a operação de execução do bloco de script seja concluída antes de atingir o tempo limite. | Não |
| configurações de log | As configurações usadas para armazenar os logs de saída. Se isso não for especificado, o log de script será desabilitado. | Não |
| logSettings.logDestination | O destino da saída de log. Pode ser ActivityOutput ou ExternalStore. Padrão: ActivityOutput. | Não |
| logSettings.logLocationSettings | As configurações do local de destino caso o logDestination seja ExternalStore. | Não |
| logSettings.logLocationSettings.linkedServiceName | O serviço vinculado do local de destino. Só há suporte para o armazenamento de blobs. | Não |
| logSettings.logLocationSettings.path | O caminho da pasta onde os logs serão armazenados. | Não |
Saída de Atividade
Saída de exemplo:
{
"resultSetCount": 2,
"resultSets": [
{
"rowCount": 10,
"rows":[
{
"<columnName1>": "<value1>",
"<columnName2>": "<value2>",
...
}
]
},
...
],
"recordsAffected": 123,
"outputParameters":{
"<parameterName1>": "<value1>",
"<parameterName2>": "<value2>"
},
"outputLogs": "<logs>",
"outputLogsLocation": "<folder path>",
"outputTruncated": true,
...
}
| Nome da propriedade | Descrição | Condição |
|---|---|---|
| resultSetCount | O número de conjuntos de resultados retornados pelo script. | Sempre |
| conjuntos de resultados | A matriz que contém todos os conjuntos de resultados. | Sempre |
| resultSets.rowCount | Número total de linhas no conjunto de resultados. | Sempre |
| resultSets.rows | A matriz de linhas no conjunto de resultados. | Sempre |
| recordsAffected | A contagem de linhas afetadas pelo script. | Se scriptType for NonQuery |
| parâmetrosDeSaída | Os parâmetros de saída do script. | Se o tipo de parâmetro for Output ou InputOutput. |
| outputLogs | Os logs gravados pelo script, por exemplo, a instrução print. | Se o conector suportar instruções de log e enableScriptLogs is true and logLocationSettings não for fornecido. |
| outputLogsPath | O caminho completo do arquivo de log. | Se enableScriptLogs for verdadeiro e logLocationSettings for fornecido. |
| outputTruncated | Indica se a saída excede os limites e se fica truncada. | Caso a saída ultrapasse os limites. |
Observação
- A saída é coletada toda vez que um bloco de script é executado. A saída final é o resultado mesclado de todas as saídas de bloco de script. O parâmetro de saída com o mesmo nome em um bloco de script diferente será substituído.
- Como a saída tem limitação de tamanho/linhas, ela será truncada na seguinte ordem: logs -> parâmetros -> linhas. Isso se aplica a um único bloco de script, o que significa que as linhas de saída do próximo bloco de script não removerão os logs anteriores.
- Qualquer erro causado pelo log não causará uma falha na atividade.
- Para consumir conjuntos de resultados de saída de atividades em atividades subsequentes, consulte a documentação de resultados de atividades de pesquisa.
- Use outputLogs quando estiver usando instruções 'PRINT' para fins de registro em log. Se a consulta retornar resultSets, ela estará disponível na saída da atividade e será limitada a 5 mil linhas/limite de tamanho de 4 MB.
Configurar a atividade de script através da interface do usuário
Script embutido
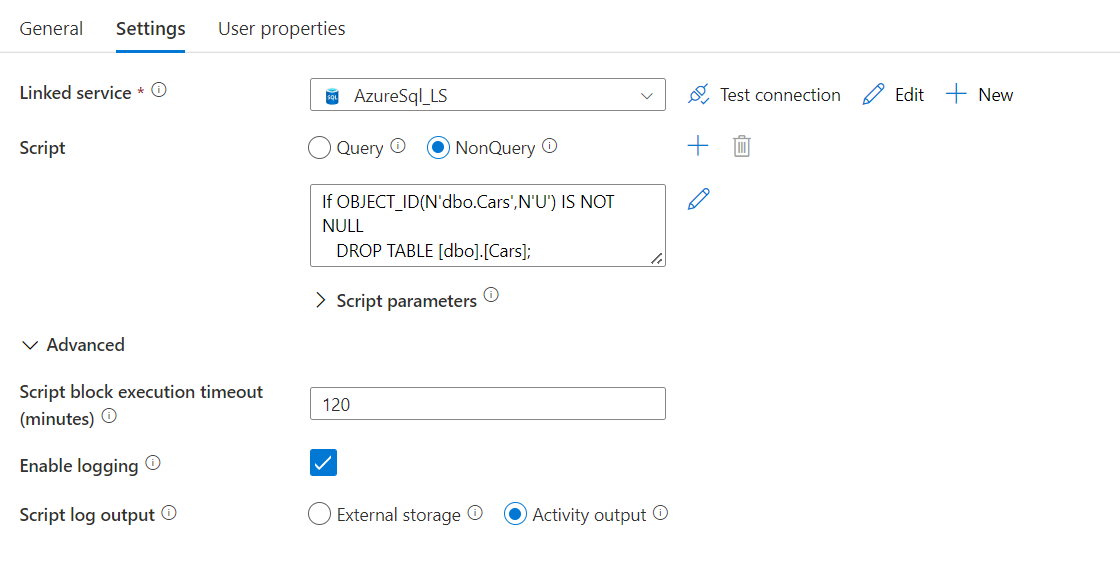
Os scripts embutidos se integram bem ao CI/CD do pipeline, pois o script é armazenado como parte dos metadados do pipeline.
Registro em log
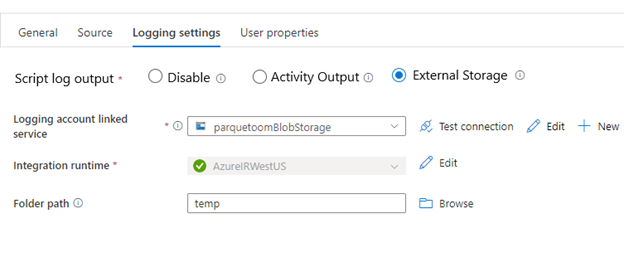
Opções de log:
- Desabilitar – nenhuma saída de execução é registrada.
- Saída da atividade - A saída da execução do script é anexada à saída da atividade. As atividades subsequentes podem então consumi-los. O tamanho de saída é limitado a 4 MB.
- Armazenamento externo — Persiste a saída no armazenamento. Use essa opção se o tamanho da saída for maior que 2 MB ou se você quiser persistir explicitamente a saída na sua conta de armazenamento.
Observação
Faturamento — A atividade de script será faturada como atividades de pipeline.
Conteúdo relacionado
Consulte os seguintes artigos que explicam como transformar dados de outras maneiras:
- U-SQL activity (Atividade do U-SQL)
- Hive activity (Atividade do Hive)
- Atividade do Pig
- MapReduce activity (Atividade do MapReduce)
- Hadoop Streaming activity (Atividade de streaming do Hadoop)
- Spark activity (Atividade do Spark)
- .NET atividade personalizada
- Stored procedure activity (Atividade de procedimento armazenado)