Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Data Factory no Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA interna e novos recursos. Se você não estiver familiarizado com a integração de dados, comece com Fabric Data Factory. As cargas de trabalho existentes do ADF podem ser atualizadas para Fabric para acessar novos recursos em ciência de dados, análise em tempo real e relatórios.
A atividade de streaming no HDInsight em um pipeline do Azure Data Factory ou Synapse Analytics executa programas de streaming do Hadoop em um cluster do HDInsight de sua propriedade ou sob demanda. Este artigo se baseia no artigo sobre atividades de transformação de dados que apresenta uma visão geral da transformação de dados e as atividades de transformação permitidas.
Para saber mais, leia os artigos de introdução ao Azure Data Factory e Synapse Analytics e faça o Tutorial: transformar dados antes de ler este artigo.
Adicionar uma atividade Streaming do HDInsight a um pipeline com a interface do usuário
Para usar uma atividade Streaming do HDInsight para um pipeline, conclua as seguintes etapas:
Pesquise na seção de Atividades do pipeline por Streaming e arraste uma atividade de Streaming para a tela do pipeline.
Selecione a nova atividade Streaming na tela se ela ainda não estiver selecionada.
Selecione a guia Cluster HDI para selecionar ou criar um serviço vinculado a um cluster HDInsight que será usado para executar a atividade Streaming.
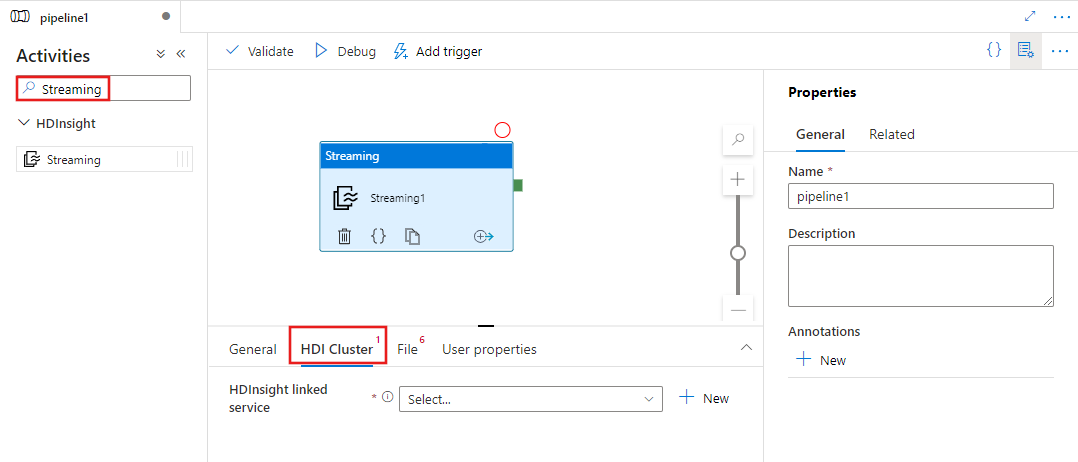
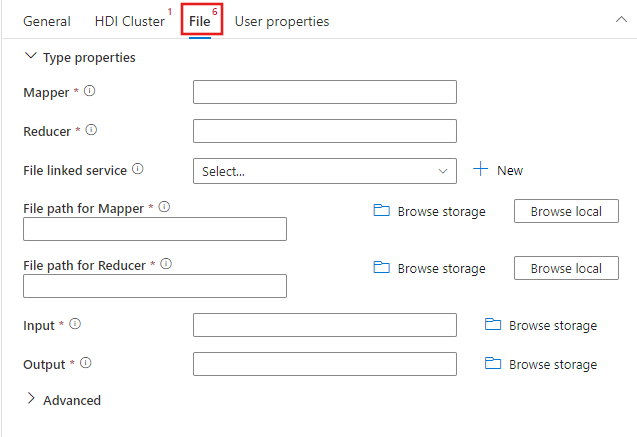
Selecione a guia Arquivo para especificar os nomes do mapeador e do redutor para o trabalho de streaming e selecione ou crie um serviço vinculado a uma conta do Armazenamento do Azure que armazenará os arquivos de mapeador, redutor, entrada e saída do trabalho. Você também pode configurar detalhes avançados, incluindo configuração de depuração, argumentos e parâmetros a serem passados para a tarefa.
Exemplo de JSON
{
"name": "Streaming Activity",
"description": "Description",
"type": "HDInsightStreaming",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"mapper": "MyMapper.exe",
"reducer": "MyReducer.exe",
"combiner": "MyCombiner.exe",
"fileLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"filePaths": [
"<containername>/example/apps/MyMapper.exe",
"<containername>/example/apps/MyReducer.exe",
"<containername>/example/apps/MyCombiner.exe"
],
"input": "wasb://<containername>@<accountname>.blob.core.windows.net/example/input/MapperInput.txt",
"output": "wasb://<containername>@<accountname>.blob.core.windows.net/example/output/ReducerOutput.txt",
"commandEnvironment": [
"CmdEnvVarName=CmdEnvVarValue"
],
"getDebugInfo": "Failure",
"arguments": [
"SampleHadoopJobArgument1"
],
"defines": {
"param1": "param1Value"
}
}
}
Detalhes da sintaxe
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| nome | Nome da atividade | Sim |
| descrição | Texto que descreve qual a utilidade da atividade | Não |
| tipo | Para a atividade de streaming do Hadoop, o tipo de atividade é HDInsightStreaming | Sim |
| nomeDoServiçoVinculado | Referência ao cluster HDInsight registrado como um serviço vinculado. Para saber mais sobre esse serviço vinculado, consulte o artigo Compute linked services (Serviços de computação vinculados). | Sim |
| mapeador | Especifica o nome do executável do mapeador | Sim |
| redutor | Especifica o nome do executável do Redutor | Sim |
| combinador | Especifica o nome do executável de Combinação | Não |
| fileLinkedService | Referência a um serviço vinculado Armazenamento do Azure usado para armazenar os programas Mapeador, Combinador e Redutor a serem executados. Apenas há suporte para Armazenamento de Blobs do Azure e ADLS Gen2 serviços associados aqui. Se você não especificar esse Serviço Vinculado, o serviço vinculado Armazenamento do Azure definido no Serviço Vinculado do HDInsight será usado. | Não |
| caminho do arquivo | Forneça uma matriz de caminho para os programas Mapper, Combiner e Reducer armazenados no Armazenamento do Azure referenciado por fileLinkedService. O caminho diferencia maiúsculas de minúsculas. | Sim |
| entrada | Especifica o caminho do WASB para o arquivo de entrada do Mapeador. | Sim |
| saída | Especifica o caminho do WASB para o arquivo de saída do Redutor. | Sim |
| getDebugInfo | Especifica quando os arquivos de log são copiados para o Armazenamento do Azure usado pelo cluster HDInsight (ou) especificado pelo scriptLinkedService. Valores permitidos: Nenhum, Sempre ou Falha. Valor padrão: Nenhum. | Não |
| argumentos | Especifica uma matriz de argumentos para um trabalho do Hadoop. Os argumentos são passados como argumentos de linha de comando para cada tarefa. | Não |
| defines | Especifique parâmetros como pares chave-valor para referências no script do Hive. | Não |
Conteúdo relacionado
Consulte os seguintes artigos que explicam como transformar dados de outras maneiras:
- U-SQL activity (Atividade do U-SQL)
- Hive activity (Atividade do Hive)
- Atividade do Pig
- MapReduce activity (Atividade do MapReduce)
- Spark activity (Atividade do Spark)
- .NET atividade personalizada
- Stored procedure activity (Atividade de procedimento armazenado)