Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Data Factory no Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA interna e novos recursos. Se você não estiver familiarizado com a integração de dados, comece com Fabric Data Factory. As cargas de trabalho existentes do ADF podem ser atualizadas para Fabric para acessar novos recursos em ciência de dados, análise em tempo real e relatórios.
Execute os pipelines do Azure Machine Learning com etapa nos pipelines do Azure Data Factory e do Synapse Analytics. O Machine Learning atividade Execute Pipeline permite cenários de previsão em lote, como identificar possíveis padrões de empréstimo, determinar sentimento e analisar padrões de comportamento do cliente.
O vídeo abaixo apresenta uma introdução de seis minutos e uma demonstração desse recurso.
Criar uma atividade Execute Pipeline de Machine Learning com a interface do usuário
Para usar um atividade Execute Pipeline de Machine Learning em um pipeline, siga estas etapas:
Procure Machine Learning no painel Atividades do pipeline e arraste uma atividade Execute Pipeline de Machine Learning para a tela do pipeline.
Selecione a nova atividade Execute Pipeline de Machine Learning na tela, se ainda não estiver selecionada, e a guia Configurações para editar os detalhes.
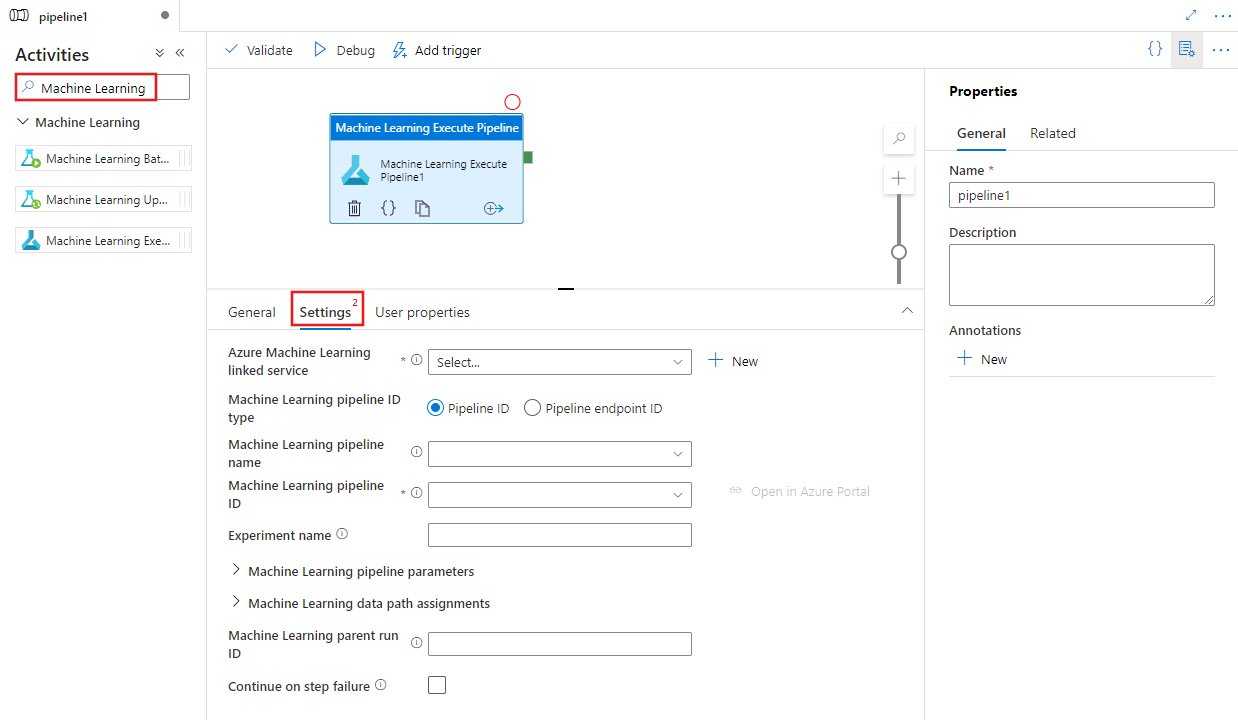
Selecione um existente ou crie um novo serviço vinculado Azure Machine Learning e forneça detalhes do pipeline e do experimento e quaisquer parâmetros de pipeline ou atribuições de caminho de dados necessárias para o pipeline.
Sintaxe
{
"name": "Machine Learning Execute Pipeline",
"type": "AzureMLExecutePipeline",
"linkedServiceName": {
"referenceName": "AzureMLService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"mlPipelineId": "machine learning pipeline ID",
"experimentName": "experimentName",
"mlPipelineParameters": {
"mlParameterName": "mlParameterValue"
}
}
}
Propriedades de tipo
| Propriedade | Descrição | Valores permitidos | Obrigatório |
|---|---|---|---|
| nome | Nome da atividade no pipeline | String | Sim |
| tipo | O tipo de atividade é 'AzureMLExecutePipeline' | String | Sim |
| nomeDoServiçoVinculado | Serviço vinculado ao Azure Machine Learning | Referência de serviço vinculado | Sim |
| mlPipelineId | ID do pipeline Azure Machine Learning publicado | Cadeia de caracteres (ou expressão com um resultType de cadeia de caracteres) | Sim |
| NomeDoExperimento | Nome do experimento de histórico de Machine Learning de teste | Cadeia de caracteres (ou expressão com um resultType de cadeia de caracteres) | Não |
| mlPipelineParameters | Pares de chave/valor a serem passados ao ponto de extremidade do Serviço do Azure Machine Learning publicado. As chaves devem corresponder aos nomes dos parâmetros do pipeline definidos no pipeline de Machine Learning publicado. | Objeto com pares de chave-valor (ou expressão com objeto do tipo resultType) | Não |
| mlParentRunId | A ID de Azure Machine Learning pipeline pai | Cadeia de caracteres (ou expressão com um resultType de cadeia de caracteres) | Não |
| dataPathAssignments | Dicionário usado para alterar caminhos de dados em Azure Machine Learning. Habilita a comutação de caminhos de dados | Objeto com pares de valor da chave | Não |
| continueOnStepFailure | Se deseja continuar a execução de outras etapas do pipeline de Machine Learning se uma etapa falhar | booleano | Não |
Observação
Para preencher os itens suspensos Machine Learning nome e ID do pipeline, o usuário precisa ter permissão para listar pipelines de ML. A interface do usuário chama as APIs do AzureMLService diretamente usando as credenciais do usuário conectado. O tempo de carregamento dos itens do menu suspenso seria muito maior ao usar Pontos de extremidade privados.
Conteúdo relacionado
Consulte os seguintes artigos que explicam como transformar dados de outras maneiras:
- Executar atividade de fluxo de dados
- Hive activity (Atividade do Hive)
- Atividade do Pig
- MapReduce activity (Atividade do MapReduce)
- Hadoop Streaming activity (Atividade de streaming do Hadoop)
- Spark activity (Atividade do Spark)
- .NET atividade personalizada
- Stored procedure activity (Atividade de procedimento armazenado)