Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Importante
Itens marcados (versão prévia) neste artigo estão atualmente em versão prévia pública. Essa versão prévia é fornecida sem um contrato de nível de serviço e não recomendamos isso para cargas de trabalho de produção. Alguns recursos podem não ter suporte ou ter recursos restritos. Para obter mais informações, consulte Supplemental Terms of Use for Microsoft Azure Previews.
Este artigo explica como usar as métricas e logs do Azure Monitor para acompanhar a disponibilidade, o desempenho e o uso de modelos implantados em Foundry Models. Azure Monitor coleta e agrega automaticamente métricas e logs de suas implantações do Foundry Models, para que você possa exibir dados de desempenho em tempo real e configurar alertas para problemas.
Pré-requisitos
Para usar funcionalidades de monitoramento para implantação de modelos em Foundry Models, você precisa do seguinte:
Um recurso Microsoft Foundry.
Dica
Se você estiver usando endpoints de API sem servidor e quiser aproveitar os recursos de monitoramento explicados neste artigo, migre seus endpoints de API sem servidor para Modelos do Foundry.
Pelo menos um modelo implantado.
Para exibir métricas: pelo menos o usuário precisa da função Leitor de Monitoramento no recurso.
Para definir as configurações de diagnóstico: o usuário precisa da função Colaborador de Monitoramento (ou equivalente) no recurso.
Métricas
Azure Monitor coleta métricas de Foundry Models automaticamente. Nenhuma configuração é necessária. Essas métricas são:
- Armazenado no banco de dados de métricas da série temporal Azure Monitor.
- Leve e capaz de dar suporte a alertas quase em tempo real.
- Usado para acompanhar o desempenho de um recurso ao longo do tempo.
Exibir métricas
Azure Monitor métricas podem ser consultadas usando várias ferramentas, incluindo:
Portal de fundição
Você pode exibir métricas no portal do Foundry. Para exibi-los, siga estas etapas:
Vá para o portal do Foundry.
Em Meus ativos no menu da barra lateral, selecione Modelos + pontos de extremidade e, em seguida, selecione o nome da implantação sobre a qual você deseja ver as métricas.
Selecione a guia Métricas .
Você pode acessar uma visão geral das métricas comuns que podem ser de interesse. Para métricas relacionadas ao custo, selecione o link Gerenciamento de Custos do Azure, que fornece acesso a métricas de custo pós-consumo detalhadas na seção Cost analysis localizada no portal Azure.
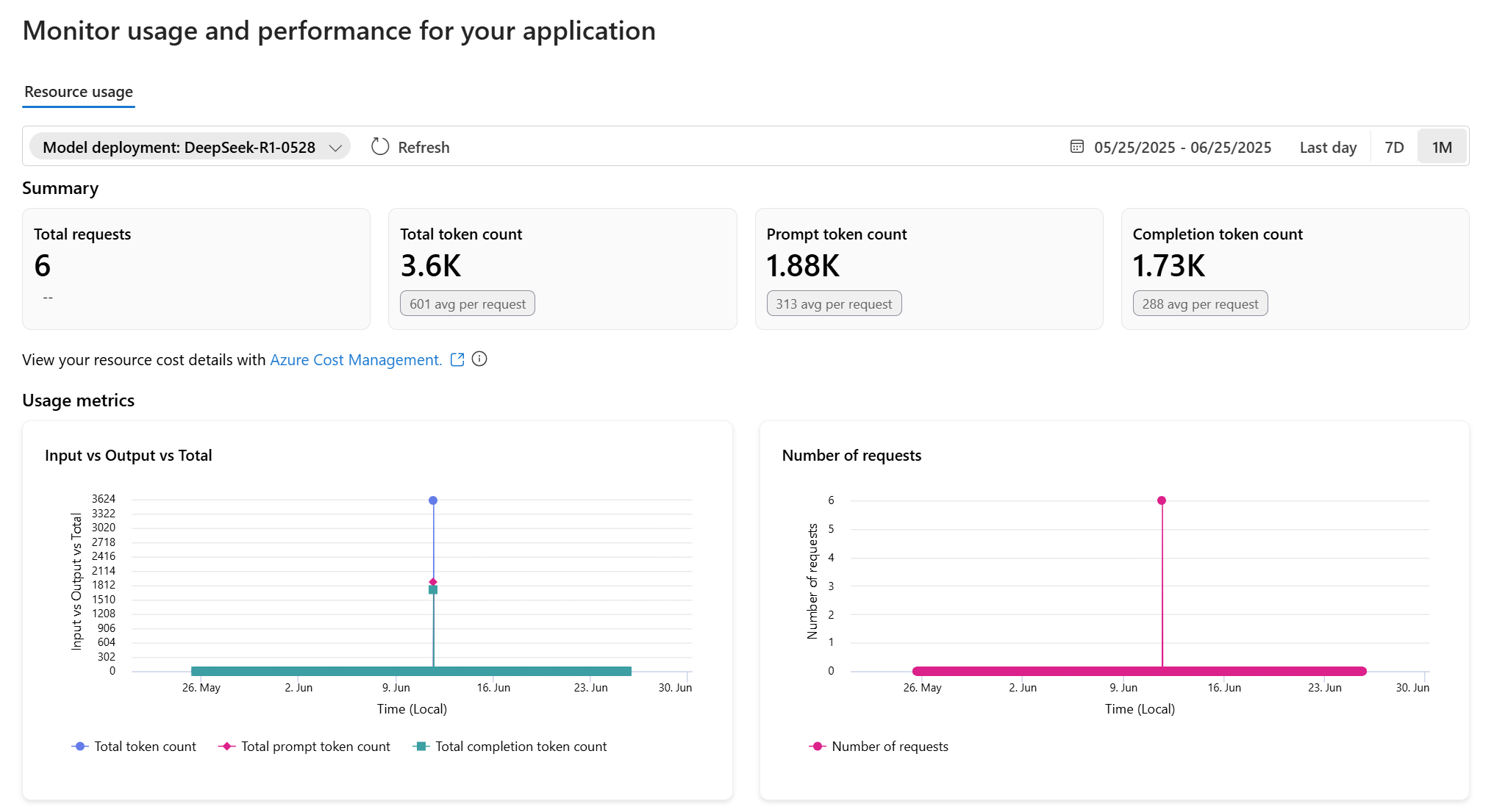
Os dados de custos no portal do Azure exibem as cobranças reais pós-consumo para o consumo do modelo, incluindo outros recursos de IA na Fábrica. Para obter uma lista completa de recursos de IA, consulte Compilar com APIs e modelos personalizáveis. Há um atraso de aproximadamente cinco horas entre o evento de faturamento e a visualização na análise de custos do portal do Azure.
Importante
O link Gerenciamento de Custos do Azure fornece um link direto no portal Azure, permitindo que os usuários acessem métricas de custo detalhadas para modelos de IA implantados. Esse link profundo integra-se à exibição do serviço Análise de Custo do Azure, oferecendo insights transparentes e acionáveis sobre os custos no nível do modelo.
O link profundo direciona os usuários para o modo de exibição de análise de custo no portal do Azure, proporcionando uma experiência de um clique para visualizar as implantações por recurso, incluindo o custo/consumo de entrada e saída de tokens. Para exibir dados de custo, você precisa de pelo menos read acesso para uma conta Azure. Para obter informações sobre como atribuir acesso aos dados de Gerenciamento de Custos, consulte Atribuir acesso aos dados.
Você pode exibir e analisar métricas com Azure Monitor metrics Explorer para fatiar e filtrar ainda mais as métricas de implantação do modelo.



Explorador de métricas
O Metrics Explorer é uma ferramenta no portal Azure que permite exibir e analisar métricas para recursos Azure. Para obter mais informações, consulte analisar métricas com o Azure Monitor Metrics Explorer.
Para usar Azure Monitor, siga estas etapas:
Acesse o portal Azure.
Digite e selecione Monitor na caixa de pesquisa.
Selecione Métricas no menu da barra lateral.
No Selecionar escopo, selecione os recursos que você deseja monitorar. Você pode selecionar um recurso ou selecionar um grupo de recursos ou uma assinatura. Se for o caso, selecione Tipos de recurso como Foundry Tools.
O gerenciador de métricas é exibido. Selecione as métricas que você deseja explorar. O exemplo a seguir mostra o número de solicitações feitas para as implantações de modelo no recurso.

Importante
As métricas na categoria Azure OpenAI contêm métricas para modelos Azure OpenAI no recurso. A categoria Models contém todos os modelos disponíveis no recurso, incluindo Azure OpenAI, DeepSeek e Phi. É recomendável alternar para esse novo conjunto de métricas.
Você pode adicionar quantas métricas forem necessárias ao mesmo gráfico ou a um novo gráfico.
Se precisar, você pode filtrar as métricas por qualquer uma das dimensões disponíveis.

É útil dividir métricas específicas por algumas das dimensões. O exemplo a seguir mostra como dividir o número de solicitações feitas ao recurso por modelo usando a opção Adicionar divisão:

Você pode salvar seus dashboards a qualquer momento para evitar a necessidade de configurá-los a cada vez.



Outras ferramentas
As ferramentas que permitem visualização mais complexa incluem:
- Workbooks: relatórios personalizáveis que você pode criar no portal Azure. As planilhas podem incluir texto, métricas e consultas de log.
- Grafana: uma ferramenta de plataforma aberta que se destaca em painéis operacionais. Você pode usar o Grafana para criar dashboards que incluem dados de várias fontes diferentes de Azure Monitor.
- Power BI: um serviço de análise de negócios que fornece visualizações interativas em várias fontes de dados. Você pode configurar Power BI para importar automaticamente dados de log de Azure Monitor para aproveitar essas visualizações.
Referência de métricas
As seguintes categorias de métricas estão disponíveis:
Modelos – Solicitações
| Métrica | Nome interno | Unidade | Agregação | Dimensões |
|---|---|---|---|---|
|
Taxa de Disponibilidade do Modelo Percentual de disponibilidade com o seguinte cálculo: (Total de Chamadas – Erros do Servidor)/Total de Chamadas. Os erros do servidor incluem quaisquer respostas HTTP >=500. |
ModelAvailabilityRate |
Por cento | Mínimo, Máximo, Média |
ApiName, OperationName, Region, StreamType, , ModelDeploymentName, ModelName, ModelVersion |
|
Solicitações de modelo Número de chamadas feitas à API de inferência do modelo durante um período de tempo. |
ModelRequests |
Contar | Total (Soma) |
ApiName, OperationName, Region, StreamType, , ModelDeploymentName, ModelName, , ModelVersionStatusCode |
Modelos – Latência
| Métrica | Nome interno | Unidade | Agregação | Dimensões |
|---|---|---|---|---|
|
Tempo de Resposta Medida de latência (capacidade de resposta) recomendada para solicitações de streaming. Aplica-se a implantações PTU e gerenciadas por PTU. Calculado conforme o tempo necessário para que a primeira resposta apareça depois que um usuário envia um prompt, conforme medido pelo gateway de API. Esse número aumenta à medida que o tamanho da solicitação aumenta e/ou o tamanho da ocorrência no cache é reduzido. Essa métrica é uma aproximação porque a latência medida depende de vários fatores, incluindo chamadas simultâneas e padrão de carga de trabalho geral. Ele não considera nenhuma latência do lado do cliente entre o cliente e o endpoint da API. Consulte seus próprios registros para obter o rastreamento ideal da latência. |
TimeToResponse |
Milissegundos | Máximo, Mínimo, Média |
ApiName, OperationName, Region, StreamType, , ModelDeploymentName, ModelName, , ModelVersionStatusCode |
|
Tempo normalizado entre tokens Para solicitações de streaming, a taxa de geração de tokens do modelo é medida em milissegundos. Aplica-se a implantações PTU e gerenciadas por PTU. |
NormalizedTimeBetweenTokens |
Milissegundos | Máximo, Mínimo, Média |
ApiName, OperationName, Region, StreamType, , ModelDeploymentName, ModelName, ModelVersion |
Modelos – Uso
| Métrica | Nome interno | Unidade | Agregação | Dimensões |
|---|---|---|---|---|
|
Tokens de entrada Número de tokens de prompt processados (entrada) em um modelo. Aplica-se a implantações PTU, gerenciadas por PTU e padrão. |
InputTokens |
Contar | Total (Soma) |
ApiName, Region, ModelDeploymentName, , ModelNameModelVersion |
|
Tokens de saída Número de tokens gerados (saída) de um modelo. Aplica-se a implantações PTU, gerenciadas por PTU e padrão. |
OutputTokens |
Contar | Total (Soma) |
ApiName, Region, ModelDeploymentName, , ModelNameModelVersion |
|
Total Tokens Número de tokens de inferência processados em um modelo. Calculados como tokens de prompt (entrada) mais tokens gerados (saída). Aplica-se a implantações PTU, gerenciadas por PTU e padrão. |
TotalTokens |
Contar | Total (Soma) |
ApiName, Region, ModelDeploymentName, , ModelNameModelVersion |
|
Taxa de Correspondência do Cache de Tokens Porcentagem de tokens de prompt que atingem o cache. Aplica-se a implantações PTU e gerenciadas por PTU. |
TokensCacheMatchRate |
Porcentagem | Média |
Region, ModelDeploymentName, , ModelNameModelVersion |
|
Utilização provisionada Percentual de utilização para uma implantação gerenciada provisionada, calculada como (PTUs consumidas/PTUs implantadas) x 100. Quando a utilização é maior ou igual a 100%, as chamadas são limitadas e o código de erro 429 é retornado. |
ProvisionedUtilization |
Porcentagem | Média |
Region, ModelDeploymentName, , ModelNameModelVersion |
|
Tokens Provisionados Consumidos Total de tokens menos tokens armazenados em cache durante um período de tempo. Aplica-se a implantações PTU e gerenciadas por PTU. |
ProvisionedConsumedTokens |
Contar | Total (Soma) |
Region, ModelDeploymentName, , ModelNameModelVersion |
|
Tokens de entrada de áudio Número de tokens de prompt de áudio processados (entrada) em um modelo. Aplica-se a implantações de modelo gerenciadas por PTU. |
AudioInputTokens |
Contar | Total (Soma) |
Region, ModelDeploymentName, , ModelNameModelVersion |
|
Tokens de saída de áudio Número de tokens de prompt de áudio gerados (saída) em um modelo. Aplica-se a implantações de modelo gerenciadas por PTU. |
AudioOutputTokens |
Contar | Total (Soma) |
Region, ModelDeploymentName, , ModelNameModelVersion |
Registros
Os logs de recursos fornecem informações sobre as operações que foram feitas por um recurso de Azure. Os logs são gerados automaticamente, mas você deve roteá-los para Azure Monitor logs para salvar ou consultar configurando uma configuração de diagnóstico. Os logs são organizados em categorias. Ao criar uma configuração de diagnóstico, especifique quais categorias de logs coletar.
As seguintes categorias de log estão disponíveis para modelos Foundry:
| Categoria | Descrição |
|---|---|
| Requestresponse | Logs para cada solicitação de inferência e resposta, incluindo códigos de status e latência. |
| Rastreio | Registros de rastreamento detalhados para depuração de chamadas de inferência de modelo. |
| Auditoria | Operações administrativas, como implantações, alterações de configuração e eventos de controle de acesso. |
Para obter mais informações sobre todas as categorias de log disponíveis, consulte categorias de log de recursos do Azure Monitor.
Definir configurações de diagnóstico
Todas as métricas são exportáveis com configurações de diagnóstico em Azure Monitor. Para analisar dados de logs e métricas com consultas de análise de logs do Azure Monitor, você pode definir as configurações de diagnóstico para o recurso do Foundry Tools. Execute essa operação em cada recurso.

Para configurar as configurações de diagnóstico para o recurso Foundry:
Vá para o Azure portal e localize o recurso Foundry.
Em Monitoramento no menu da barra lateral, selecione Configurações de diagnóstico.
Selecione Adicionar configuração de diagnóstico.
Insira um nome para a configuração de diagnóstico.
Em Logs, selecione as categorias de log que você deseja coletar (por exemplo, RequestResponseLogs).
Em Métricas, selecione AllMetrics para exportar métricas.
Em Destination details, selecione Enviar para o espaço de trabalho do Log Analytics e escolha um espaço de trabalho em sua assinatura.
Selecione Salvar.
Nota
Há um custo para coletar dados em um workspace do Log Analytics, portanto, colete apenas as categorias necessárias para cada serviço. O volume de dados para logs de recursos varia significativamente entre os serviços.
Consultar logs com KQL
Depois de configurar as definições de diagnóstico para enviar métricas ao Log Analytics, você pode consultar e analisar os dados de log usando a linguagem de consulta Kusto (KQL).
Para consultar as métricas, siga estas etapas:
Acesse o portal Azure.
Localize o recurso Foundry que você deseja consultar.
Em Monitoramento no menu da barra lateral, selecione Logs. Se as opções da janela de consulta forem exibidas, feche a janela.
Uma nova aba de consulta será aberta. Selecione o menu suspenso Modo de Amostra e selecione o Modo KQL.
Para examinar as métricas de Azure, digite uma consulta personalizada ou copie e cole a seguinte consulta:
AzureMetrics | take 100 | project TimeGenerated, MetricName, Total, Count, Maximum, Minimum, Average, TimeGrain, UnitNameSelecionar Executar
Nota
Quando você seleciona Monitoring>Logs no menu do recurso, Log Analytics é aberto com o escopo de consulta definido para o recurso atual. As consultas de log visíveis incluem dados somente desse recurso específico. Para executar uma consulta que inclua dados de outros recursos ou dados de outros serviços Azure, selecione Logs no menu Azure Monitor no portal Azure. Para obter mais informações, consulte Escopo de consulta de log e intervalo de tempo no Azure Monitor Log Analytics.
Solucionando problemas
| Questão | Causa possível | Resolução |
|---|---|---|
| Métricas que não aparecem no gerenciador de métricas | O filtro de tipo de recurso pode não ser definido corretamente. | Certifique-se de que Tipos de Recursos esteja definido como Foundry Tools no seletor de escopo. |
| Nenhum dado de log no Log Analytics | As configurações de diagnóstico não estão configuradas ou os dados ainda não chegaram. | Defina as configurações de diagnóstico e aguarde até 15 minutos para que os dados apareçam. |
| As métricas mostram valores zero | A implantação do modelo pode não ter recebido tráfego no intervalo de tempo selecionado. | Ajuste o intervalo de tempo no gerenciador de métricas ou verifique se a implantação está recebendo solicitações. |
| Dados de custo não visíveis no Gerenciamento de Custos da Microsoft | Permissões ausentes ou atraso de cobrança. | Verifique se você tem pelo menos read acesso à conta Azure. Os dados de custo podem levar até cinco horas para serem exibidos. |
| 429 erros em chamadas de modelo | A utilização provisionada está em ou acima de 100%. | Verifique a métrica Utilização Provisionada e aumente as PTUs ou reduza o volume de solicitações. |