Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Aplica-se somente a:![]() Portal Foundry (clássico). Este artigo não está disponível para o novo portal do Foundry.
Saiba mais sobre o novo portal.
Portal Foundry (clássico). Este artigo não está disponível para o novo portal do Foundry.
Saiba mais sobre o novo portal.
Nota
Links neste artigo podem abrir conteúdo na nova documentação do Microsoft Foundry em vez da documentação da Foundry (clássica) que você está exibindo agora.
Se você já tiver um projeto de IA no Microsoft Foundry, o Catálogo de Modelos implanta modelos de provedores parceiros de modelos como endpoints autônomos em seu projeto por padrão. Cada implantação de modelo tem seu próprio conjunto de URI e credenciais para acessá-la. Por outro lado, os modelos do Azure OpenAI são implantados no recurso Foundry ou no recurso Azure OpenAI nos modelos Foundry.
Importante
Azure SDK beta de inferência de IA foi preterido e será desativado em 26 de agosto de 2026. Mudar para a API OpenAI/v1 geralmente disponível com um SDK estável da OpenAI. Siga o guia de migração para alternar para OpenAI/v1 usando o SDK para sua linguagem de programação preferida.
Você pode alterar esse comportamento e implantar ambos os tipos de modelos em recursos do Foundry. Depois de configuradas, implantações de modelos como implantações de API sem servidor são realizadas no recurso Foundry conectado em vez do próprio projeto, fornecendo um único conjunto de endpoints e credenciais para acessar todos os modelos implantados na Foundry. Você pode gerenciar modelos do Azure OpenAI e modelos de provedores parceiros da mesma maneira.
Além disso, a implantação de modelos no Foundry Models traz os benefícios adicionais de:
- Funcionalidade de roteamento
- Filtros de conteúdo personalizados
- Tipo de implantação de capacidade global
- A autenticação sem chave com Microsoft Entra ID
Neste artigo, você aprenderá a configurar seu projeto para usar implantações do Foundry Models.
Pré-requisitos
Para concluir este tutorial, você precisa:
Uma assinatura Azure. Se você estiver usando modelos GitHub, poderá atualizar sua experiência e criar uma assinatura Azure no processo. Para saber mais, consulte Upgrade de modelos de GitHub para Foundry Models.
Um recurso do Foundry. Para obter mais informações, consulte Criar seu primeiro recurso do Foundry.
Um projeto e um hub do Foundry. Para obter mais informações, consulte Como criar e gerenciar um hub do Foundry.
Dica
Quando o hub de IA é provisionado, um recurso do Foundry é criado com ele e os dois recursos são conectados. Para ver qual recurso está conectado ao seu projeto, vá para o portal Foundry>Centro de Gerenciamento>Recursos Conectados e localize as conexões do tipo Ferramentas do Foundry.
Configurar o projeto para usar Foundry Models
Para configurar o projeto para usar a capacidade de Modelos do Foundry, siga estas etapas:
Na página de aterrissagem do projeto, selecione o Centro de Gerenciamento na parte inferior do menu da barra lateral. Identifique o recurso Foundry conectado ao seu projeto.
Se nenhum recurso estiver listado, o hub de IA não terá um recurso do Foundry conectado a ele. Crie uma nova conexão.
Selecione +Nova conexão e escolha Microsoft Foundry nos blocos.
Na janela, procure um recurso existente em sua assinatura e selecione Adicionar conexão.
A nova conexão é adicionada ao hub.
Retorne à página inicial do projeto.
Em Capacidades incluídas, selecione Azure AI Inference. A URI do endpoint de inferência do modelo Azure AI é exibida junto com as credenciais para acessar.

Dica
Cada recurso do Foundry possui um único ponto de extremidade de inferência de modelo da IA do Azure, que pode ser usado para acessar qualquer implantação de modelo nele. O mesmo endpoint atende a vários modelos, dependendo de quais são configurados. Para saber como funciona o endpoint, consulte o Azure OpenAI endpoint de inferência.
Anote a URL e as credenciais do ponto de extremidade.

Criar a implantação do modelo em Foundry Models
Para cada modelo que você deseja implantar nos Modelos Foundry, siga estas etapas:
Vá para o catálogo de modelos no portal do Foundry.
Role até o modelo no qual você está interessado e selecione-o.

Você pode examinar os detalhes do modelo no cartão de modelo.
Selecione Usar este modelo.
Para provedores de modelo que exigem mais termos de contrato, você é solicitado a aceitar esses termos selecionando Concordar e continuar.
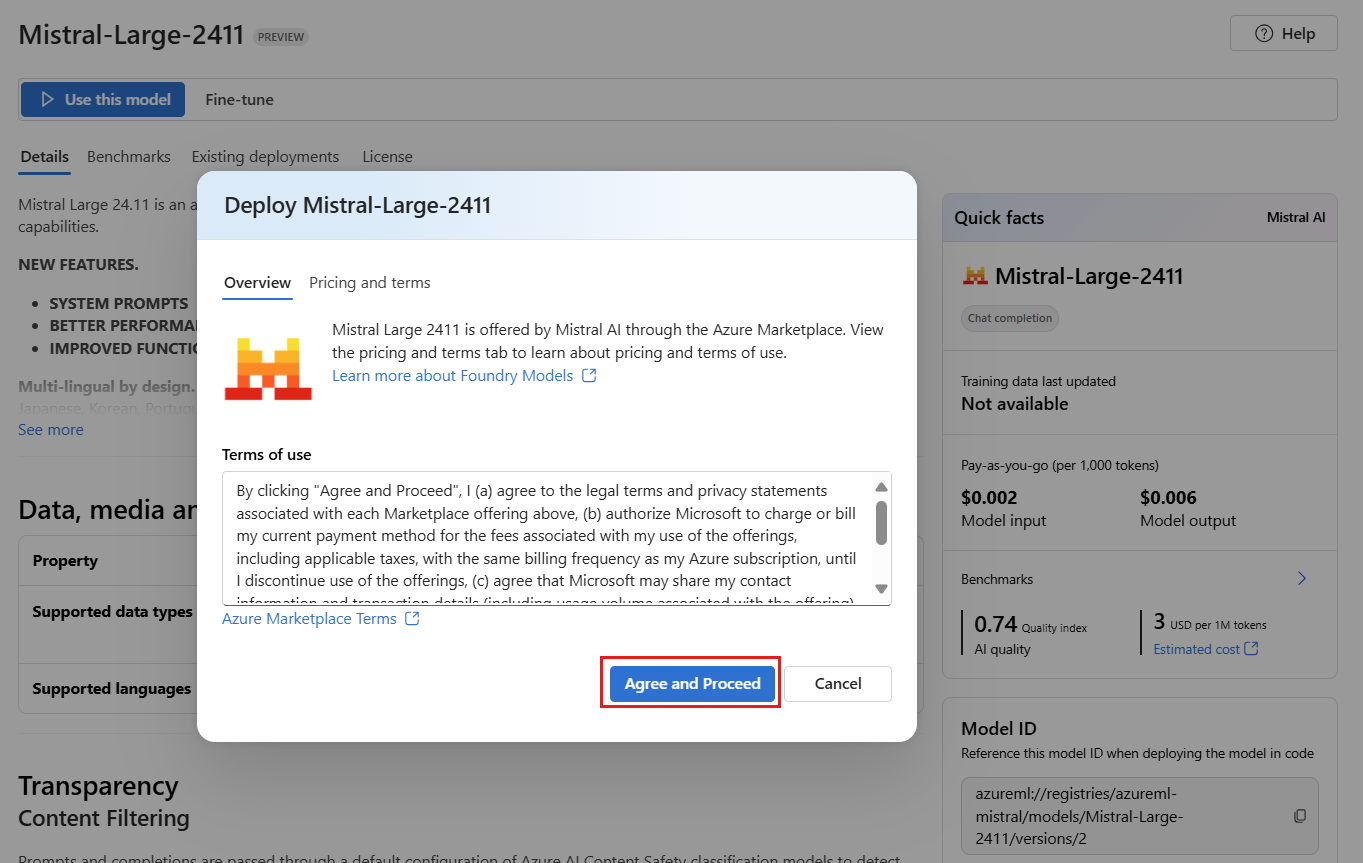
Você pode definir as configurações de implantação no momento. Por padrão, a implantação recebe o nome do modelo que você está implantando. O nome da implantação
modelé usado no parâmetro da solicitação para rotear para esta implantação específica. Ele permite que você configure nomes específicos para seus modelos ao anexar configurações específicas. Por exemplo,o1-preview-safepara um modelo com um filtro de conteúdo estrito.Selecionamos automaticamente uma conexão Foundry dependendo do seu projeto porque você ativou o recurso Implantar modelos no serviço de inferência de modelos da Azure AI. Selecione Personalizar para alterar a conexão com base em suas necessidades. Se você estiver implantando no tipo de implantação de API sem servidor , os modelos precisarão estar disponíveis na região do recurso Foundry.
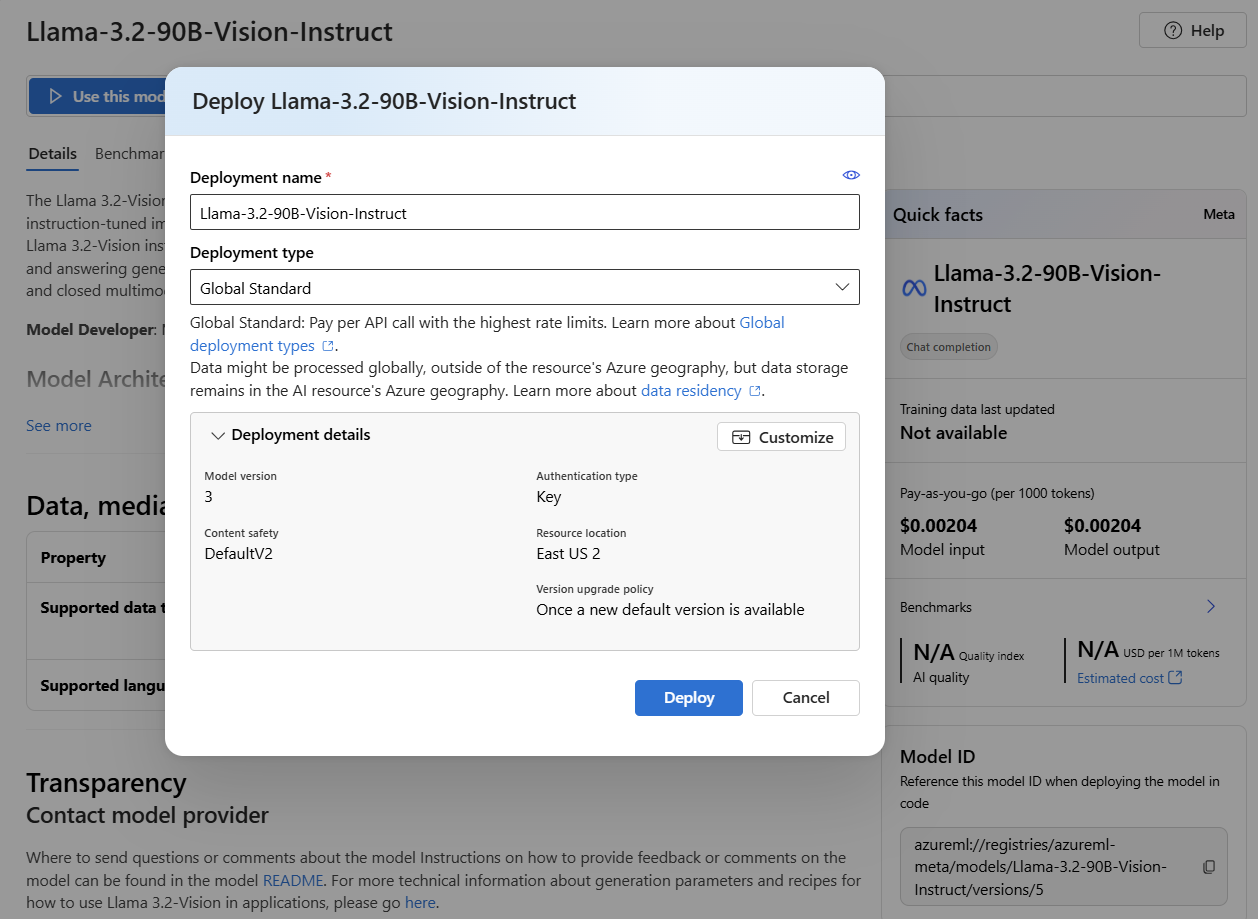
Selecione Implantar.
Depois que a implantação for concluída, você verá o URL do endpoint e as credenciais para acessar o modelo. Observe que agora a URL e as credenciais fornecidas são as mesmas exibidas na página de destino do projeto para o endpoint Foundry Models.
Você pode exibir todos os modelos disponíveis no recurso acessando a seção Modelos + pontos de extremidade e localizando o grupo para a conexão com seu recurso:





Melhore o seu código com o novo endpoint
Depois que o recurso Foundry estiver configurado, você poderá começar a utilizá-lo no código. Você precisa da URL do ponto de extremidade e da chave para ela, que podem ser encontradas na seção Visão geral :
Você pode usar qualquer um dos SDKs com suporte para obter previsões do endpoint. Os seguintes SDKs têm suporte oficial:
- OpenAI SDK
- SDK Azure do OpenAI
- Pacote de Inferência de IA do Azure
- Pacote de Projetos de IA Azure
Para obter mais informações e exemplos, consulte Supported programming languages for Azure AI Inference SDK. O exemplo a seguir mostra como usar o pacote de inferência de IA Azure com o modelo recém-implantado:
Instale o pacote azure-ai-inference usando o gerenciador de pacotes, como pip:
pip install azure-ai-inference
Em seguida, você pode usar o pacote para consumir o modelo. O exemplo a seguir mostra como criar um cliente para consumir conclusões de chat:
import os
from azure.ai.inference import ChatCompletionsClient
from azure.core.credentials import AzureKeyCredential
client = ChatCompletionsClient(
endpoint="https://<resource>.services.ai.azure.com/models",
credential=AzureKeyCredential(os.environ["AZURE_INFERENCE_CREDENTIAL"]),
)
Explore nossas samples e leia a documentação de referência API para começar.
Gere sua primeira conclusão de chat:
from azure.ai.inference.models import SystemMessage, UserMessage
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="Explain Riemann's conjecture in 1 paragraph"),
],
model="mistral-large"
)
print(response.choices[0].message.content)
Use o parâmetro model="<deployment-name> para rotear sua solicitação para essa implantação.
As implantações funcionam como um alias de um determinado modelo em determinadas configurações. Para saber como o Foundry Models roteia implantações, consulte Roteamento.
Mover de implantações de API sem servidor para modelos do Foundry
Embora você tenha configurado o projeto para usar o Foundry Models, as implantações de modelo existentes continuam a existir dentro do projeto como implantações de API sem servidor. Essas implantações não são movidas para você. Portanto, você pode atualizar progressivamente qualquer código existente que faça referência a implantações de modelo anteriores. Para começar a mover as implantações de modelo, recomendamos o seguinte fluxo de trabalho:
Recrie a implantação do modelo em Modelos de Fundiário. Essa implantação de modelo é acessível no ponto de extremidade de modelos do Foundry.
Atualize seu código para usar o novo endpoint.
Limpe o projeto removendo a implantação da API sem servidor.
Melhore o seu código com o novo endpoint
Depois que os modelos forem implantados no Foundry, você poderá atualizar seu código para usar o endpoint dos modelos do Foundry. A principal diferença entre como as implantações de API sem servidor e os Modelos de Foundry funcionam reside na URL do ponto de extremidade e no parâmetro de modelo. Embora as implantações de API sem servidor tenham um conjunto de URI e chave por cada implantação de modelo, o Foundry Models tem apenas um para todos eles.
A tabela a seguir resume as alterações que você precisa introduzir:
| Propriedade | Implantações de API sem servidor | Modelos de fundição |
|---|---|---|
| Endpoint | https://<endpoint-name>.<region>.inference.ai.azure.com |
https://<ai-resource>.services.ai.azure.com/models |
| Credenciais | Um por modelo/endpoint. | Um por recurso do Foundry. Você também pode usar Microsoft Entra ID. |
| Parâmetro de modelo | Nenhum. | Obrigatório. Use o nome da implantação do modelo. |
Limpar implantações de API sem servidor existentes do seu projeto
Depois de refatorar seu código, convém excluir as implantações de API sem servidor existentes dentro do projeto (se houver).
Para cada modelo implantado como implantações de API sem servidor, siga estas etapas:
Vá para o portal do Foundry.
Selecione Modelos + pontos de extremidade e, em seguida, escolha a guia Pontos de Extremidade de Serviço .
Identifique os pontos de extremidade do tipo implantação de API sem servidor e selecione aquele que você deseja excluir.
Selecione a opção Excluir.
Aviso
Esta operação não pode ser revertida. Verifique se o endpoint não esteja atualmente usado por qualquer outro usuário ou parte do código.
Confirme a operação selecionando Excluir.
Se você criou uma conexão de implantação de API sem servidor de outros projetos para esse ponto de extremidade, essas conexões não serão removidas e continuarão apontando para o ponto de extremidade inexistente. Exclua qualquer uma dessas conexões para evitar erros.
Limitações
Considere as seguintes limitações ao configurar seu projeto para usar Foundry Models:
- Somente os modelos que dão suporte a implantações de API sem servidor estão disponíveis para implantação no Foundry Models. Modelos que exigem cota de computação de sua assinatura (computação gerenciada), incluindo modelos personalizados, só podem ser implantados em um determinado projeto como Pontos de Extremidade Online Gerenciados e continuam acessíveis usando seu próprio conjunto de URI e credenciais de ponto de extremidade.
- Os modelos disponíveis como implantações de API sem servidor e ofertas de computação gerenciada são, por padrão, implantados nos Modelos do Foundry em recursos do Foundry. O portal Foundry não oferece uma maneira de implantá-los em endpoints gerenciados online. Você precisa desativar o recurso mencionado em Configurar o projeto para usar Foundry Models ou usar o CLI do Azure/SDK do Azure ML/modelos ARM para fazer a implantação.