Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Met de no-code-editor kunt u eenvoudig een Stream Analytics-taak ontwikkelen om uw realtime streaminggegevens te verwerken. Gebruik slepen-en-neerzetten-functionaliteit zonder code te schrijven. De ervaring biedt een canvas waar u verbinding kunt maken met invoerbronnen om snel uw streaminggegevens te zien. Vervolgens kunt u deze transformeren voordat u naar uw bestemmingen schrijft.
Met behulp van de editor zonder code kunt u het volgende eenvoudig doen:
- Invoerschema's wijzigen.
- Voer gegevensvoorbereidingsbewerkingen zoals joins en filters uit.
- Benader geavanceerde scenario's, zoals tijdvensteraggregaties (tumbling, hopping en sessievensters) voor groepsbewerkingen.
Nadat u uw Stream Analytics-taken hebt gemaakt en uitgevoerd, kunt u eenvoudig productieworkloads operationeel maken. Gebruik de juiste set ingebouwde metrische gegevens voor bewakings- en probleemoplossingsdoeleinden. Stream Analytics-taken worden gefactureerd volgens het prijsmodel wanneer ze worden uitgevoerd.
Vereisten
Voordat u uw Stream Analytics-taken ontwikkelt met behulp van de no-code-editor, moet u ervoor zorgen dat u aan deze vereisten voldoet:
- De streaming-invoerbronnen en doeldoelresources voor de Stream Analytics-taak moeten openbaar toegankelijk zijn en kunnen zich niet in een virtueel Azure-netwerk bevinden.
- U moet over de vereiste machtigingen beschikken om toegang te krijgen tot de streaming-invoer- en uitvoerresources.
- U moet machtigingen behouden om Azure Stream Analytics-resources te maken en te wijzigen.
Notitie
De no-code-editor is momenteel niet beschikbaar in de regio China.
Azure Stream Analytics-job
Een Stream Analytics-taak is gebaseerd op drie hoofdonderdelen: streaming-invoer, transformaties en uitvoer. U kunt zoveel onderdelen opnemen als u wilt, zoals meerdere invoer, parallelle vertakkingen met meerdere transformaties en meerdere uitvoer. Zie Documentatie voor Azure Stream Analytics voor meer informatie.
Notitie
De volgende functies en uitvoertypen zijn niet beschikbaar wanneer u de editor zonder code gebruikt:
- Door de gebruiker gedefinieerde functies.
- Bewerken van queries op de querypagina van Azure Stream Analytics. U kunt echter de query bekijken die is gegenereerd door de codevrije editor, op de querypagina.
- Invoer en uitvoer toevoegen in Azure Stream Analytics invoer- en uitvoerpagina's. U kunt echter de invoer en uitvoer bekijken die door de editor zonder code zijn gegenereerd op de invoer- en uitvoerpagina.
- De volgende uitvoertypen zijn niet beschikbaar: Azure Function, Azure Data Lake Storage Gen1, PostgreSQL DB, Service Bus wachtrij/onderwerp, Table Storage.
Gebruik een van de volgende methoden om toegang te krijgen tot de no-code-editor voor het bouwen van uw Stream Analytics-taak:
Via de Azure Stream Analytics-portal (preview): Maak een Stream Analytics-taak en selecteer vervolgens de editor zonder code op het tabblad Aan de slag op de overzichtspagina of selecteer De editor Zonder code in het linkerdeelvenster.
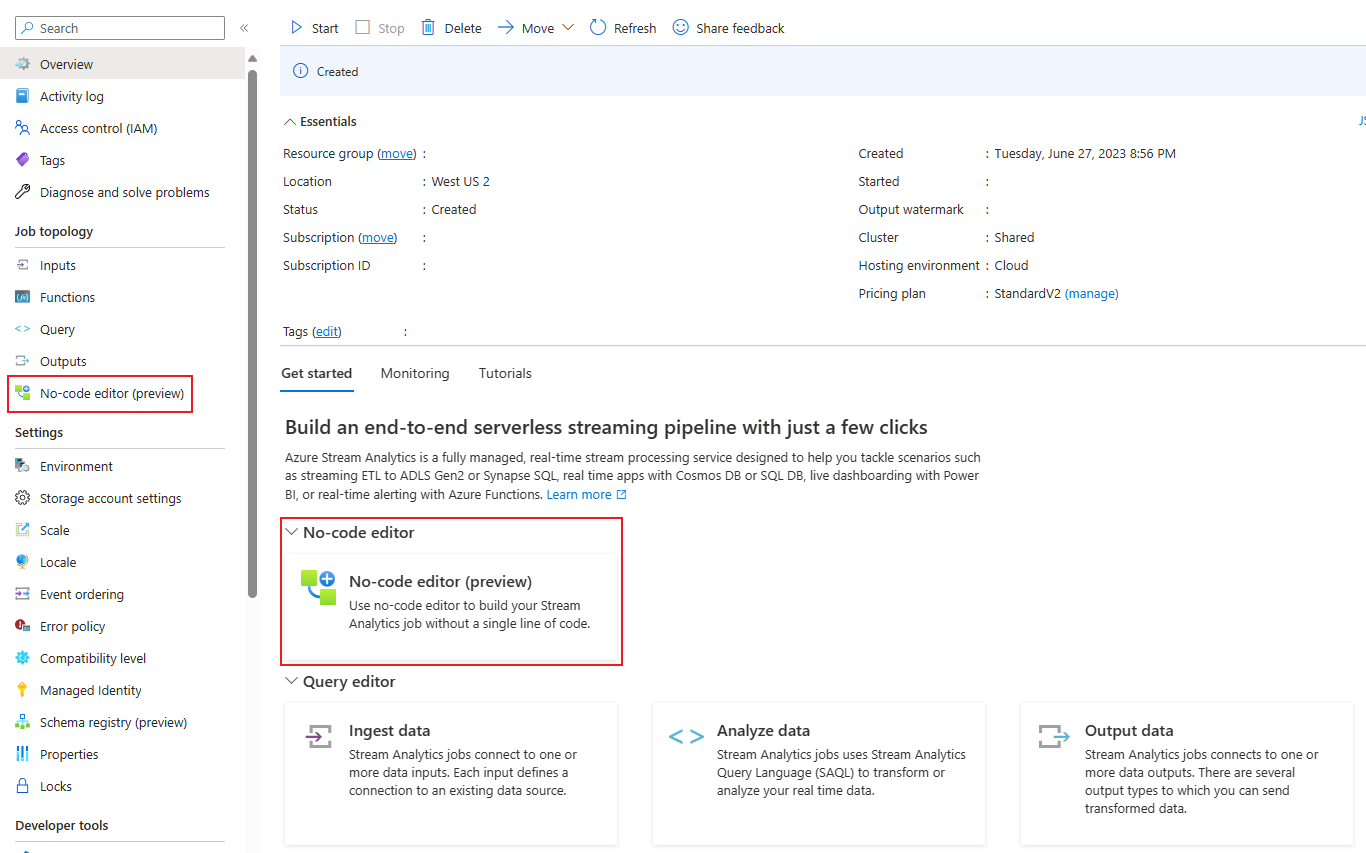
Via de Azure Event Hubs-portal: Open een Event Hubs-exemplaar. Selecteer Procesgegevens en selecteer vervolgens een vooraf gedefinieerde sjabloon.
Met de vooraf gedefinieerde sjablonen kunt u een taak ontwikkelen en uitvoeren om verschillende scenario's aan te pakken, waaronder:
- Gegevens van Event Hubs opslaan in Delta Lake-formaat (preview)
- Filteren en opnemen in Azure Synapse SQL
- Het vastleggen van uw Event Hubs-gegevens in de Parquet-indeling binnen Azure Data Lake Storage Gen2
- Gegevens materialiseren in Azure Cosmos DB
- Filteren en opnemen in Azure Data Lake Storage Gen2
- Gegevens verrijken en opnemen in Event Hub
- Gegevens transformeren en opslaan in Azure SQL-database
- Filteren en opnemen in Azure Data Explorer


In de volgende schermopname ziet u een voltooide Stream Analytics-taak. Hiermee worden alle secties gemarkeerd die voor u beschikbaar zijn terwijl u schrijft.

- Lint: op het lint volgen secties de volgorde van een klassiek analyseproces: een Event Hub als invoer (ook wel gegevensbron genoemd), transformaties (streaming-bewerkingen extraheren, transformeren en laden), uitvoer, een knop om uw voortgang op te slaan en een knop om de taak te starten.
- Diagramweergave: Deze weergave is een grafische weergave van uw Stream Analytics-taak, van invoer tot bewerkingen tot uitvoer.
- Zijvenster: Afhankelijk van welk onderdeel u selecteert in de diagramweergave, ziet u instellingen voor het wijzigen van invoer, transformatie of uitvoer.
- Tabbladen voor gegevensvoorbeelden, ontwerpfouten, runtimelogboeken en metrische gegevens: Voor elke tegel toont het gegevensvoorbeeld de resultaten voor die stap (live voor invoer; op aanvraag voor transformaties en uitvoer). Deze sectie bevat ook een overzicht van eventuele ontwerpfouten of waarschuwingen die u mogelijk in uw taak hebt wanneer deze wordt ontwikkeld. Als u elke fout of waarschuwing selecteert, wordt die transformatie geselecteerd. Het biedt ook de taakmetingen waarmee u de gezondheid van de lopende taak kunt controleren.
Invoer van streaminggegevens
De no-code-editor biedt ondersteuning voor het streamen van gegevensinvoer van drie typen resources:
- Azure Event Hubs
- Azure IoT Hub
- Azure Data Lake Storage Gen2
Zie Stream-gegevens als invoer in Stream Analytics voor meer informatie over de invoer van streaminggegevens.
Notitie
De editor zonder code in de Azure Event Hubs-portal heeft alleen Event Hub als invoeroptie.

Azure Event Hubs als streaming-invoer
Azure Event Hubs is een streamingplatform voor big data en een service voor gebeurtenisopname. Het kan miljoenen gebeurtenissen per seconde ontvangen en verwerken. U kunt gegevens die naar een Event Hub worden verzonden, transformeren en opslaan via elke realtime analyseprovider of batchverwerking en opslagadapter.
Als u een Event Hub wilt configureren als invoer voor uw taak, selecteert u het Event Hub-pictogram . Er wordt een tegel weergegeven in de diagramweergave, inclusief een zijvenster voor de configuratie en verbinding.
Wanneer u verbinding maakt met uw Event Hub in de editor zonder code, maakt u een nieuwe consumentengroep (dit is de standaardoptie). Met deze methode voorkomt u dat de Event Hub de limiet voor gelijktijdige lezers bereikt. Zie Consumentengroepen voor meer informatie over consumentengroepen en of u een bestaande consumentengroep moet selecteren of een nieuwe groep moet maken.
Als uw Event Hub zich in de Basic-laag bevindt, kunt u alleen de bestaande $Default consumentengroep gebruiken. Als uw Event Hub zich in een Standard- of Premium-laag bevindt, kunt u een nieuwe consumentengroep maken.
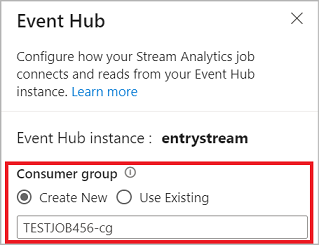
Wanneer u verbinding maakt met de Event Hub en u Managed Identity selecteert als verificatiemodus, wordt de rol Azure Event Hubs Gegevenseigenaar verleend aan de beheerde identiteit voor de Stream Analytics-taak. Zie Beheerde identiteiten gebruiken voor toegang tot een Event Hub vanuit een Azure Stream Analytics-taak voor meer informatie over beheerde identiteiten voor een Event Hub.
Beheerde identiteiten elimineren de beperkingen van verificatiemethoden op basis van gebruikers. Deze beperkingen omvatten de noodzaak om opnieuw te verifiëren vanwege wachtwoordwijzigingen of verloop van gebruikerstoken die elke 90 dagen plaatsvinden.
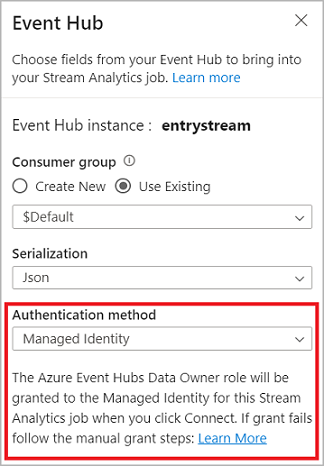
Nadat u de details van uw Event Hub hebt ingesteld en Verbinding maken hebt geselecteerd, kunt u handmatig velden toevoegen met behulp van + Veld toevoegen als u de veldnamen kent. Als u in plaats daarvan velden en gegevenstypen automatisch wilt detecteren op basis van een voorbeeld van de binnenkomende berichten, selecteert u Autodetectie-velden. Als u het tandwielsymbool selecteert, kunt u de referenties zo nodig bewerken.
Wanneer Stream Analytics-taken de velden detecteren, ziet u deze in de lijst. U ziet ook een livevoorbeeld van de inkomende berichten in de tabel Gegevensvoorbeeld onder de diagramweergave.
Invoergegevens wijzigen
U kunt de veldnamen bewerken, velden verwijderen, het gegevenstype wijzigen of de gebeurtenistijd wijzigen (Markeren als gebeurtenistijd: TIMESTAMP BY-component als een datum/tijd-typeveld) door het symbool met drie punten naast elk veld te selecteren. U kunt ook geneste velden uit de binnenkomende berichten uitvouwen, selecteren en bewerken, zoals wordt weergegeven in de volgende afbeelding.
Tip
Dit proces is ook van toepassing op de invoergegevens uit Azure IoT Hub en Azure Data Lake Storage Gen2.

De beschikbare gegevenstypen zijn:
- Datum/tijd: datum- en tijdveld in ISO-indeling.
- Float: Decimaal getal.
- Int: integer.
- Record: Genest object met meerdere records.
- Tekenreeks: Tekst.
Azure IoT Hub als streaming-invoer
Azure IoT Hub is een beheerde service die wordt gehost in de cloud die fungeert als een centrale berichtenhub voor communicatie tussen een IoT-toepassing en de bijbehorende apparaten. U kunt IoT-apparaatgegevens gebruiken die naar IoT Hub worden verzonden als invoer voor een Stream Analytics-taak.
Notitie
U kunt Azure IoT Hub invoer gebruiken in de editor zonder code in Azure Stream Analytics portal.
Als u een IoT-hub wilt toevoegen als streaming-invoer voor uw taak, selecteert u de IoT Hub onder Invoer op het lint. Vul vervolgens de benodigde informatie in het rechterdeelvenster in om IoT Hub te verbinden met uw taak. Zie Stream-gegevens van IoT Hub naar Stream Analytics-taak voor meer informatie over de details van elk veld.

Azure Data Lake Storage Gen2 als streaming-invoer
Azure Data Lake Storage Gen2 (ADLS Gen2) is een data lake-oplossing in de cloud. Het is ontworpen om enorme hoeveelheden gegevens op te slaan in elk formaat en om big data-analytische workloads te vergemakkelijken. Stream Analytics kan de gegevens verwerken die zijn opgeslagen in ADLS Gen2 als gegevensstroom. Zie Stream-gegevens van ADLS Gen2 naar de Stream Analytics-taak voor meer informatie over dit type invoer.
Notitie
U kunt Azure Data Lake Storage Gen2 invoer gebruiken in de editor zonder code in Azure Stream Analytics portal.
Als u een ADLS Gen2 wilt toevoegen als streaming-invoer voor uw taak, selecteert u de ADLS Gen2 onder Invoer op het lint. Vul vervolgens de benodigde informatie in het rechterdeelvenster in om ADLS Gen2 aan uw taak te koppelen. Zie Stream-gegevens van ADLS Gen2 naar de Stream Analytics-taak voor meer informatie over de details van elk veld.

Referentiegegevensinvoer
Referentiegegevens zijn statisch of worden langzaam gewijzigd in de loop van de tijd. Normaal gesproken gebruikt u deze om binnenkomende streams te verrijken en zoekacties uit te voeren in uw taak. U kunt bijvoorbeeld gegevensstroominvoer samenvoegen om te verwijzen naar gegevens, net zoals u een SQL-join zou uitvoeren om statische waarden op te zoeken. Zie Referentiegegevens gebruiken voor zoekacties in Stream Analytics voor meer informatie over verwijzingsgegevensinvoer.
De no-code-editor ondersteunt nu twee referentiegegevensbronnen:
- Azure Data Lake Storage Gen2
- Azure SQL Database

Azure Data Lake Storage Gen2 als referentiegegevens
Modelreferentiegegevens als een reeks blobs in oplopende volgorde van de combinatie van datum en tijd die is opgegeven in de blobnaam. U kunt blobs alleen toevoegen aan het einde van de reeks door een datum en tijd te gebruiken die groter is dan die van de laatste blob die in de reeks is opgegeven. Definieer blobs in de invoerconfiguratie.
Selecteer eerst Verwijzing ADLS Gen2 onder de sectie Invoer op het lint. Zie de sectie over Azure Blob Storage in Use reference data for lookups in Stream Analytics voor meer informatie over elk veld.
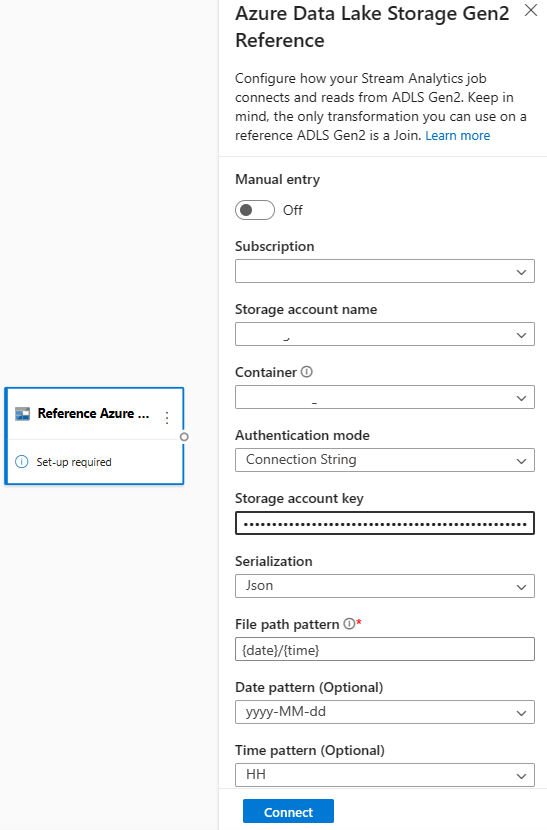
Upload vervolgens een JSON-matrixbestand. Het systeem detecteert de velden. Gebruik deze referentiegegevens om transformatie uit te voeren met streaming-invoergegevens van Event Hubs.

Azure SQL Database als referentiegegevens
U kunt Azure SQL Database gebruiken als referentiegegevens voor uw Stream Analytics-taak in de no-code-editor. Raadpleeg de sectie over SQL Database in Use reference data for lookups in Stream Analytics voor meer informatie.
Als u SQL Database wilt configureren als referentiegegevensinvoer, selecteert u Referentie-SQL Database onder de sectie Invoer op het lint. Vul vervolgens de gegevens in om uw referentiedatabase te verbinden en selecteer de tabel met de benodigde kolommen. U kunt ook de referentiegegevens uit de tabel ophalen door de SQL-query handmatig te bewerken.

Transformaties
Streaminggegevenstransformaties verschillen inherent van batchgegevenstransformaties. Bijna alle streaminggegevens hebben een tijdonderdeel dat van invloed is op alle betrokken taken voor gegevensvoorbereiding.
Als u een streaminggegevenstransformatie aan uw taak wilt toevoegen, selecteert u het transformatiesymbool onder de sectie Bewerkingen op het lint voor die transformatie. De respectieve tegel wordt toegevoegd aan de diagramweergave. Nadat u deze hebt geselecteerd, ziet u het zijvenster voor die transformatie om deze te configureren.

Filter
Gebruik de filtertransformatie om gebeurtenissen te filteren op basis van de waarde van een veld in de invoer. Afhankelijk van het gegevenstype (getal of tekst) behoudt de transformatie de waarden die overeenkomen met de geselecteerde voorwaarde.

Notitie
Binnen elke tegel ziet u informatie over wat er nog meer nodig is om de transformatie gereed te maken. Wanneer u bijvoorbeeld een nieuwe tegel toevoegt, ziet u het bericht Setup vereist . Als u een knooppuntconnector mist, ziet u een foutbericht of een waarschuwingsbericht .
Velden beheren
Met de transformatie Velden beheren kunt u velden toevoegen, verwijderen of de naam ervan wijzigen die afkomstig zijn van een invoer of een andere transformatie. Met de instellingen in het zijdeelvenster kunt u een nieuw veld toevoegen door veld toevoegen te selecteren of alle velden tegelijk toe te voegen.

U kunt ook een nieuw veld toevoegen met behulp van de ingebouwde functies om de gegevens van upstream te aggregeren. Momenteel zijn de ingebouwde functies die worden ondersteund enkele functies in tekenreeksfuncties, datum- en tijdfuncties en wiskundige functies. Zie Ingebouwde functies (Azure Stream Analytics) voor meer informatie over de definities van deze functies.

Tip
Nadat u een tegel hebt geconfigureerd, ziet u in de diagramweergave een glimp van de instellingen in de tegel. In het gebied Velden beheren van de voorgaande afbeelding ziet u bijvoorbeeld de eerste drie velden die worden beheerd en de nieuwe namen die eraan zijn toegewezen. Elke tegel bevat informatie die relevant is voor deze tegel.
Samenvoegen
Gebruik de aggregatietransformatie om telkens wanneer een nieuwe gebeurtenis plaatsvindt in een bepaalde periode een aggregatie (Som, Minimum, Maximum of Gemiddelde) te berekenen. Met deze bewerking kunt u de aggregatie ook filteren of segmenteren op basis van andere dimensies in uw gegevens. U kunt een of meer aggregaties opnemen in dezelfde transformatie.
Als u een aggregatie wilt toevoegen, selecteert u het transformatiesymbool. Verbind vervolgens een invoer, selecteer de aggregatie, voeg een filter- of segmentdimensies toe en selecteer de periode waarin de aggregatie wordt berekend. In dit voorbeeld berekent u de som van de tolwaarde per staat waaruit het voertuig in de afgelopen 10 seconden afkomstig is.

Als u een andere aggregatie wilt toevoegen aan dezelfde transformatie, selecteert u de functie Aggregatie toevoegen. Het filter of segment is van toepassing op alle aggregaties in de transformatie.
Deelnemen
Gebruik de jointransformatie om gebeurtenissen van twee invoer te combineren op basis van de veldparen die u selecteert. Als u geen veldpaar selecteert, is de join standaard gebaseerd op tijd. De standaardinstelling is wat deze transformatie anders maakt dan een batch.
Net als bij gewone joins hebt u opties voor uw joinlogica:
- Inner join: Neem alleen records op uit beide tabellen waarin het paar overeenkomt. In dit voorbeeld komen de kentekenplaat en beide invoer overeen.
- Left outer join: neem alle records uit de linkertabel (eerste) op en alleen de records uit de tweede die overeenkomen met het paar velden. Als er geen overeenkomst is, zijn de velden uit de tweede invoer leeg.
Als u het type join wilt selecteren, selecteert u het symbool voor het gewenste type in het zijvenster.
Selecteer ten slotte de periode waarvoor u de join wilt berekenen. In dit voorbeeld kijkt de join naar de laatste 10 seconden. Hoe langer de periode is, hoe minder vaak de uitvoer is en hoe meer verwerkingsresources u gebruikt voor de transformatie.
De uitvoer bevat standaard alle velden uit beide tabellen. Met voorvoegsels links (eerste knooppunt) en rechts (tweede knooppunt) kunt u onderscheid maken tussen de bron.

Groeperen op
Gebruik de transformatie Groeperen op om aggregaties te berekenen voor alle gebeurtenissen binnen een bepaald tijdvenster. U kunt groeperen op de waarden in een of meer velden. Het is net als de Aggregatie-transformatie, maar biedt meer opties voor aggregaties. Het bevat ook complexere opties voor tijdvensters. U kunt ook meer dan één aggregatie per transformatie toevoegen, zoals Aggregaat.
De aggregaties die beschikbaar zijn in de transformatie zijn:
- Gemiddeld
- Tellen
- Maximum
- Minimum
- Percentiel (doorlopend en discreet)
- Standaarddeviatie
- Sum
- Variantie
De transformatie configureren:
- Selecteer de gewenste aggregatie.
- Selecteer het veld waarop u wilt aggregeren.
- Selecteer een optioneel group-by-veld als u de cumulatieve berekening wilt ophalen voor een andere dimensie of categorie. Bijvoorbeeld: Staat.
- Selecteer uw functie voor tijdvensters.
Als u een andere aggregatie wilt toevoegen aan dezelfde transformatie, selecteert u de functie Aggregatie toevoegen. Houd er rekening mee dat het veld Groeperen op en de windowfunctie van toepassing zijn op alle aggregaties in de transformatie.

Een tijdstempel voor het einde van het tijdvenster wordt weergegeven als onderdeel van de transformatie-uitvoer ter referentie. Zie Windowing-functies (Azure Stream Analytics) voor meer informatie over tijdvensters die door Stream Analytics-taken worden ondersteund.
Vakbond
Gebruik de uniontransformatie om twee of meer invoer te verbinden. Voeg gebeurtenissen toe met gedeelde velden (met dezelfde naam en hetzelfde gegevenstype) in één tabel. De uitvoer sluit velden uit die niet overeenkomen.
Matrix uitvouwen
Gebruik de matrixtransformatie Uitvouwen om een nieuwe rij te maken voor elke waarde in een matrix.

Streaming-uitvoer
De ervaring met slepen en neerzetten zonder code ondersteunt momenteel verschillende uitvoersinks om uw verwerkte realtime gegevens op te slaan.

Azure Data Lake Storage Gen2
Data Lake Storage Gen2 maakt van Azure Storage de basis voor het bouwen van zakelijke data lakes op Azure. Het is ontworpen om meerdere petabytes aan informatie te verwerken, terwijl honderden gigabits aan doorvoer worden gehandhaafd. Hiermee kunt u eenvoudig enorme hoeveelheden gegevens beheren. Azure Blob Storage biedt een rendabele en schaalbare oplossing voor het opslaan van grote hoeveelheden ongestructureerde gegevens in de cloud.
Selecteer in de sectie Uitvoer op het lint ADLS Gen2 als uitvoer voor uw Stream Analytics-taak. Selecteer vervolgens de container waarin u de uitvoer van de taak wilt verzenden. Zie Blob Storage- en Azure Data Lake Gen2-uitvoer van Azure Stream Analytics voor meer informatie over Azure Data Lake Gen2-uitvoer voor een Stream Analytics-taak.
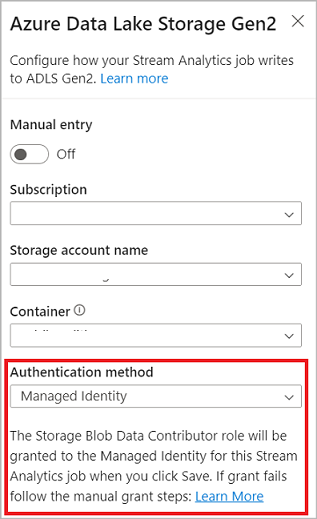
Wanneer u verbinding maakt met Azure Data Lake Storage Gen2 en u Managed Identity selecteert als verificatiemodus, wordt de rol Inzender voor opslagblobgegevens verleend aan de beheerde identiteit voor de Stream Analytics-taak. Zie Beheerde identiteiten gebruiken om uw Azure Stream Analytics-taak te verifiëren bij Azure Blob Storage voor meer informatie over beheerde identiteiten voor Azure Data Lake Storage Gen2.
Beheerde identiteiten elimineren de beperkingen van verificatiemethoden op basis van gebruikers. Deze beperkingen omvatten de noodzaak om opnieuw te verifiëren vanwege wachtwoordwijzigingen of verloop van gebruikerstoken die elke 90 dagen plaatsvinden.
Precies zodra levering (preview) wordt ondersteund in ADLS Gen2, omdat er geen uitvoer van de code-editor is. U kunt deze inschakelen in de sectie Schrijfmodus in de ADLS Gen2-configuratie. Zie Exactly once delivery (preview) in Azure Data Lake Gen2 voor meer informatie over deze functie.

Schrijven naar Delta Lake-tabel (preview) wordt ondersteund in ADLS Gen2 omdat er geen uitvoer van de code-editor is. U hebt toegang tot deze optie in secties serialisatie in de ADLS Gen2-configuratie. Zie Schrijven naar Delta Lake-tabel voor meer informatie over deze functie.

Azure Synapse Analytics
Azure Stream Analytics-taken kunnen uitvoer verzenden naar een toegewezen SQL-pooltabel in Azure Synapse Analytics en doorvoersnelheden verwerken tot 200 MB per seconde. Stream Analytics biedt ondersteuning voor de meest veeleisende realtime analyses en dynamische gegevensverwerkingsbehoeften voor workloads zoals rapportage en dashboarding.
Belangrijk
De toegewezen SQL-pooltabel moet bestaan voordat u deze als uitvoer kunt toevoegen aan uw Stream Analytics-taak. Het schema van de tabel moet overeenkomen met de velden en de bijbehorende typen in de uitvoer van uw taak.
Selecteer Synapse in de sectie Uitvoer op het lint als uitvoer voor uw Stream Analytics-taak. Selecteer vervolgens de SQL-pooltabel waarin u de uitvoer van de taak wilt verzenden. Zie Azure Synapse Analytics-uitvoer van Azure Stream Analytics voor meer informatie over Azure Synapse-uitvoer voor een Stream Analytics-taak.
Azure Cosmos DB
Azure Cosmos DB is een wereldwijd gedistribueerde databaseservice die onbeperkte elastische schaal over de hele wereld biedt. Het biedt ook uitgebreide query's en automatische indexering via schemaagnostische gegevensmodellen.
Selecteer in de sectie Uitvoer op het lint CosmosDB als uitvoer voor uw Stream Analytics-job. Zie Azure Cosmos DB-uitvoer van Azure Stream Analytics voor meer informatie over Azure Cosmos DB-uitvoer voor een Stream Analytics-taak.
Wanneer u verbinding maakt met Azure Cosmos DB en u Managed Identity selecteert als verificatiemodus, wordt de rol Inzender verleend aan de beheerde identiteit voor de Stream Analytics-taak. Zie Beheerde identiteiten gebruiken voor toegang tot Azure Cosmos DB vanuit een Azure Stream Analytics-taak (preview) voor meer informatie over beheerde identiteiten voor Azure Cosmos DB.
De Azure Cosmos DB-uitvoer in de editor zonder code ondersteunt ook de verificatiemethode voor beheerde identiteiten. Deze methode biedt dezelfde voordelen als in de ADLS Gen2-uitvoer.
Azure SQL Database
Azure SQL Database is een volledig beheerde PaaS-database-engine (Platform as a Service), waarmee u een maximaal beschikbare en krachtige gegevensopslaglaag voor toepassingen en oplossingen in Azure kunt maken. Met behulp van de no-code-editor kunt u Azure Stream Analytics-taken configureren om de verwerkte gegevens naar een bestaande tabel in SQL Database te schrijven.
Als u Azure SQL Database als uitvoer wilt configureren, selecteert u SQL Database onder de sectie Uitvoer op het lint. Voer vervolgens de gegevens in waarnaar u verbinding wilt maken met uw SQL-database en selecteer de tabel waarnaar u gegevens wilt schrijven.
Belangrijk
De Azure SQL Database-tabel moet bestaan voordat u deze als uitvoer kunt toevoegen aan uw Stream Analytics-taak. Het schema van de tabel moet overeenkomen met de velden en de bijbehorende typen in de uitvoer van uw taak.
Event Hubs
Met realtime gegevens die naar ASA worden verzonden, kan de editor zonder code de gegevens transformeren en verrijken en de gegevens vervolgens uitvoeren naar een andere Event Hub. U kunt de Event Hubs-uitvoer kiezen wanneer u uw Azure Stream Analytics-taak configureert.
Als u Event Hubs als uitvoer wilt configureren, selecteert u Event Hub onder de sectie Uitvoer op het lint. Voer vervolgens de informatie in die nodig is om verbinding te maken met uw Event Hub voor het schrijven van gegevens.
Zie Event Hubs-uitvoer van Azure Stream Analytics voor meer informatie over Event Hubs-uitvoer voor een Stream Analytics-taak.
Azure Data Explorer
Azure Data Explorer is een volledig beheerd, krachtige, big data-analyseplatform waarmee u eenvoudig grote hoeveelheden gegevens kunt analyseren. U kunt Azure Data Explorer ook gebruiken als uitvoer voor uw Azure Stream Analytics taak met behulp van de editor zonder code.
Als u Azure Data Explorer als uitvoer wilt configureren, selecteert u Azure Data Explorer onder de sectie Outputs op het lint. Voer vervolgens de vereiste gegevens in om verbinding te maken met uw Azure Data Explorer-database en geef de tabel op waarnaar u gegevens wilt schrijven.
Belangrijk
De tabel moet bestaan in de geselecteerde database en het schema van de tabel moet exact overeenkomen met de velden en de bijbehorende typen in de uitvoer van uw taak.
Zie Azure Data Explorer-uitvoer van Azure Stream Analytics (preview) voor meer informatie over azure Data Explorer-uitvoer voor een Stream Analytics-taak.
Power BI
Power BI biedt een uitgebreide visualisatie-ervaring voor het resultaat van uw gegevensanalyse. Door Power BI uitvoer naar Stream Analytics te gebruiken, worden de verwerkte streaminggegevens naar een Power BI streaminggegevensset geschreven en kunt u deze gebruiken om het bijna realtime Power BI dashboard te bouwen.
Als u Power BI wilt configureren als uitvoer, selecteert u Power BI onder de sectie Outputs op het lint. Voer vervolgens de vereiste gegevens in om verbinding te maken met uw Power BI werkruimte en geef de namen op voor de streaminggegevensset en tabel waarnaar u de gegevens wilt schrijven. Zie Power BI-uitvoer van Azure Stream Analytics voor meer informatie over de details van elk veld.
Gegevensvoorbeeld, ontwerpfouten, runtimelogboeken en metrische gegevens
De ervaring voor slepen en neerzetten zonder code biedt hulpprogramma's waarmee u de prestaties van uw analysepijplijn voor streaminggegevens kunt ontwerpen, oplossen en evalueren.
Voorbeeld van livegegevens voor invoer
Wanneer u verbinding maakt met een invoerbron, zoals een Event Hub, en de tegel ervan selecteert in de diagramweergave (het tabblad Gegevensvoorbeeld ), ziet u een livevoorbeeld van binnenkomende gegevens als aan alle volgende voorwaarden wordt voldaan:
- Er worden gegevens verzonden.
- De invoer is correct geconfigureerd.
- Velden worden toegevoegd.
Zoals te zien is in de volgende schermopname, kunt u het voorbeeld pauzeren als u iets specifieks wilt bekijken of verder wilt verkennen (1). Of u kunt het opnieuw starten als u klaar bent.
U kunt ook de details van een specifieke record, een cel in de tabel bekijken door deze te selecteren en vervolgens details weergeven/verbergen (2) te selecteren. In de schermopname ziet u de gedetailleerde weergave van een genest object in een record.

Statische preview voor transformaties en uitvoer
Nadat u alle stappen in de diagramweergave hebt toegevoegd en ingesteld, kunt u hun gedrag testen door statische preview ophalen te selecteren.

Wanneer u de knop selecteert, evalueert de Stream Analytics-taak alle transformaties en uitvoer om ervoor te zorgen dat deze correct zijn geconfigureerd. Stream Analytics geeft vervolgens de resultaten weer in het voorbeeld van statische gegevens, zoals wordt weergegeven in de volgende afbeelding.

U kunt de preview vernieuwen door Statische preview vernieuwen (1) te selecteren. Wanneer u de preview vernieuwt, worden met de Stream Analytics-taak nieuwe gegevens uit de invoer opgehaald en worden alle transformaties geëvalueerd. Vervolgens wordt uitvoer opnieuw verzonden met eventuele updates die u mogelijk hebt uitgevoerd. De optie Details weergeven/verbergen is ook beschikbaar (2).
Ontwerpfouten
Als u ontwerpfouten of waarschuwingen hebt, worden deze weergegeven op het tabblad Ontwerpfouten , zoals wordt weergegeven in de volgende schermopname. De lijst bevat details over de fout of waarschuwing, het type kaart (invoer, transformatie of uitvoer), het foutniveau en een beschrijving van de fout of waarschuwing.

Runtimelogboeken
Runtimelogboeken worden weergegeven op waarschuwings-, fout- of informatieniveau wanneer een taak wordt uitgevoerd. Deze logboeken zijn handig als u de topologie of configuratie van uw Stream Analytics-taak wilt bewerken voor probleemoplossing. Schakel diagnostische logboeken in en stuur ze naar Log Analytics werkruimte in Settings om meer inzicht te krijgen in uw actieve taken voor foutopsporing.

In het volgende schermopnamevoorbeeld configureert de gebruiker SQL Database-uitvoer met een tabelschema dat niet overeenkomt met de velden van de taakuitvoer.

Metrische gegevens
Als de taak wordt uitgevoerd, kunt u de status van uw taak controleren op het tabblad Metrische gegevens. De vier metrische gegevens die standaard worden weergegeven, zijn watermerkvertraging, invoergebeurtenissen, backloginvoergebeurtenissen en uitvoergebeurtenissen. Gebruik deze metrische gegevens om te begrijpen of de gebeurtenissen in en uit de taak stromen zonder enige invoerachterstand.

U kunt meer metrische gegevens selecteren in de lijst. Zie Metrische Gegevens van Azure Stream Analytics-taak om alle metrische gegevens in detail te begrijpen.
Een Stream Analytics-taak starten
U kunt de taak op elk gewenst moment opslaan tijdens het maken ervan. Nadat u de streaming-invoer, transformaties en streaming-uitvoer voor de taak hebt geconfigureerd, kunt u de taak starten.
Notitie
Hoewel de no-code-editor in de Azure Stream Analytics-portal in preview is, is de Azure Stream Analytics-service algemeen beschikbaar.

U kunt deze opties configureren:
-
Begintijd van uitvoer: wanneer u een taak start, selecteert u een tijd voor de taak om uitvoer te maken.
- Nu: Met deze optie wordt het beginpunt van de uitvoer gebeurtenisstroom hetzelfde als wanneer de taak wordt gestart.
- Aangepast: kies het beginpunt van de uitvoer.
- Wanneer de taak voor het laatst is gestopt: deze optie is beschikbaar wanneer de taak eerder is gestart, maar handmatig is gestopt of mislukt. Wanneer u deze optie kiest, wordt de laatste uitvoertijd gebruikt om de taak opnieuw op te starten, zodat er geen gegevens verloren gaan.
- Streaming-eenheden: Streaming-eenheden (RU's) vertegenwoordigen de hoeveelheid rekenkracht en geheugen die aan de taak is toegewezen terwijl deze wordt uitgevoerd. Als u niet zeker weet hoeveel SU's u moet kiezen, begint u met drie en past u deze indien nodig aan.
- Verwerking van uitvoergegevensfouten: beleidsregels voor het verwerken van uitvoergegevensfouten zijn alleen van toepassing wanneer de uitvoer gebeurtenis die door een Stream Analytics-taak wordt geproduceerd, niet voldoet aan het schema van de doelsink. Configureer het beleid door opnieuw te proberen of te verwijderen. Zie het uitvoerfoutbeleid van Azure Stream Analytics voor meer informatie.
- Start: Met deze knop wordt de Stream Analytics-taak gestart.

Stream Analytics-takenlijst in de Azure Event Hubs-portal
Als u een lijst wilt zien van alle Stream Analytics-taken die u hebt gemaakt met behulp van de no-code slepen-en-neerzetten-ervaring in de Azure Event Hubs-portal, selecteer Verwerk gegevens>Stream Analytics-taken.

Dit zijn de elementen van het tabblad Stream Analytics-taken :
- Filter: Filter de lijst op taaknaam.
- Vernieuwen: Op dit moment wordt de lijst niet automatisch vernieuwd. Gebruik de knop Vernieuwen om de lijst te vernieuwen en de meest recente status weer te geven.
- Taaknaam: De naam die u hier ziet is de naam die u in de eerste stap bij het aanmaken van de taak opgeeft. U kunt het niet bewerken. Selecteer de taaknaam om de taak te openen in de ervaring zonder code slepen en neerzetten, waar u de taak kunt stoppen, bewerken en opnieuw kunt starten.
- Status: In dit gebied wordt de status van de taak weergegeven. Selecteer Vernieuwen boven aan de lijst om de meest recente status weer te geven.
- Streaming-eenheden: in dit gebied ziet u het aantal streaming-eenheden dat u selecteert wanneer u de taak start.
- Uitvoerwatermerk: Dit gebied geeft een indicator van activiteit voor de gegevens die door de opdracht worden geproduceerd. Alle gebeurtenissen vóór het tijdstempel worden al berekend.
- Taakbewaking: selecteer Metrische gegevens openen om de metrische gegevens te bekijken die betrekking hebben op deze Stream Analytics-taak. Zie Azure Stream Analytics taakstatistieken voor meer informatie over de statistieken die u kunt gebruiken om uw Stream Analytics-taak te monitoren.
- Bewerkingen: de taak starten, stoppen of verwijderen.
Volgende stappen
Meer informatie over het gebruik van de editor zonder code om veelvoorkomende scenario's aan te pakken met behulp van vooraf gedefinieerde sjablonen: