Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Met geheugen kunnen AI-agents informatie van eerder in het gesprek of van eerdere gesprekken onthouden. Hierdoor kunnen agents contextbewuste antwoorden bieden en gepersonaliseerde ervaringen bouwen in de loop van de tijd. Gebruik Databricks Lakebase, een volledig beheerde Postgres OLTP-database, om de gespreksstatus en -geschiedenis te beheren.
Requirements
- Databricks-apps inschakelen in uw werkruimte. Zie Uw Databricks Apps-werkruimte en -ontwikkelomgeving instellen.
- Een Lakebase-exemplaar, zie Een database-exemplaar maken en beheren.
Korte termijn versus langetermijngeheugen
Kortlopend geheugen legt context vast in één gesprekssessie, terwijl langetermijngeheugen belangrijke informatie over meerdere gesprekken extraheert en opslaat. U kunt uw agent bouwen met een of beide typen geheugen.
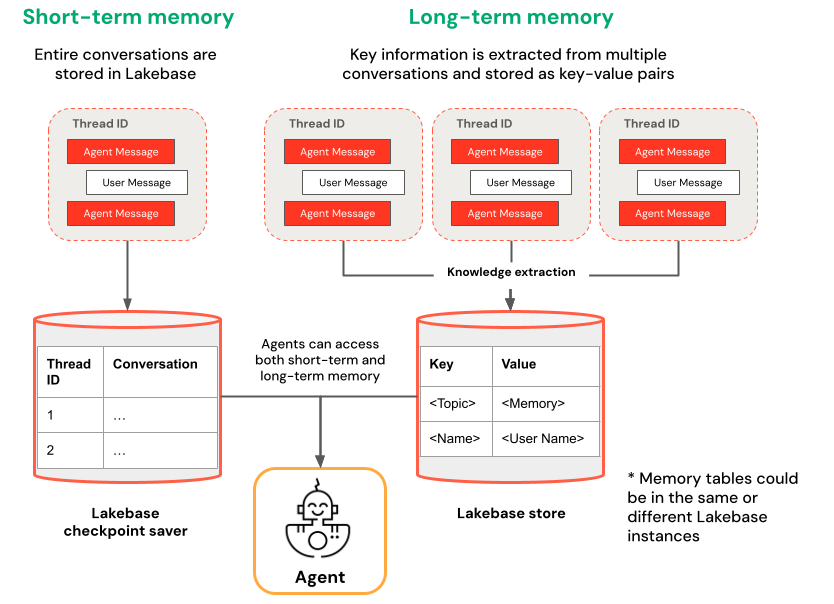
| Kortlopend geheugen | Langetermijngeheugen |
|---|---|
| Context vastleggen in één gesprekssessie met thread-id's en controlepunten Context behouden voor vervolgvragen binnen een sessie |
Belangrijke inzichten automatisch extraheren en opslaan in meerdere sessies Interacties aanpassen op basis van eerdere voorkeuren Een knowledge base bouwen over gebruikers die reacties in de loop van de tijd verbeteren |
Aan de slag
Als u een agent met geheugen in Databricks-apps wilt maken, kloont u een vooraf gebouwde app-sjabloon en volgt u de ontwikkelwerkstroom die wordt beschreven in Een AI-agent ontwerpen en implementeert u deze in Apps. De volgende sjablonen laten zien hoe u kort- en langetermijngeheugen toevoegt aan agents met behulp van populaire frameworks.
LangGraph
Kloon de agent-langgraph-geavanceerde sjabloon om een LangGraph-agent te bouwen met zowel korte als langetermijngeheugen. De sjabloon maakt gebruik van de ingebouwde controlepunten van LangGraph met Lakebase voor duurzaam statusbeheer, inclusief gesprekscontext op basis van threads en permanente gebruikersinzichten in sessies.
git clone https://github.com/databricks/app-templates.git
cd app-templates/agent-langgraph-advanced
OpenAI Agents SDK
Kloon de agent-openai-geavanceerde sjabloon om een agent te bouwen met behulp van de OpenAI Agents SDK met kort geheugen. De sjabloon maakt gebruik van Lakebase voor duurzaam statusbeheer, waardoor gesprekken met statusbehoud met meerdere beurten mogelijk worden gemaakt met automatisch gespreksgeschiedenisbeheer.
git clone https://github.com/databricks/app-templates.git
cd app-templates/agent-openai-advanced
Uitvoering op de achtergrond voor langlopende processen
Databricks Apps dwingt een time-out voor een HTTP-verbinding af van ongeveer 300 seconden. Met uitvoering op de achtergrond kunnen agenttaken die deze limiet overschrijden, actief blijven nadat de verbinding is gesloten; de client haalt resultaten op van een afzonderlijk eindpunt of maakt opnieuw verbinding om streaming te hervatten.
De geavanceerde sjablonen , agent-langgraph-advanced en agent-openai-advanced - breiden de basissjablonen uit met kortetermijngeheugen en langlopende achtergronduitvoering via LongRunningAgentServerdatabricks-ai-bridge, die het volgende biedt:
-
Achtergrondmodus: Stel
background=truein de aanvraagbody in om onmiddellijk een antwoord-id te retourneren en de agent asynchroon uit te voeren. -
Eindpunt ophalen: Verzenden
GET /responses/{id}om het uiteindelijke resultaat op te halen of om een streamingverbinding te openen met een actieve uitvoering. -
Hervatbaar streamen: elke serververzendde gebeurtenis bevat een
sequence_number. Als de verbinding wegvalt, verbind opnieuw metstarting_after=Nom door te gaan vanaf de volgende gebeurtenis. - TASK_TIMEOUT_SECONDS Omgevingsvariabele waarbij de duur van de achtergrondtaak wordt afkapt. Dit is onafhankelijk van de time-out voor HTTP-verbindingen van 120 seconden voor Databricks Apps, die alleen van toepassing is op één HTTP-aanvraag. (standaard: 1 uur)
In de geavanceerde sjabloon README ziet u aanvraagvoorbeelden voor vijf clientmodi:
- Aanroepen: Een standaard niet-streaming POST.
- Stream: Een standaardstreaming-POST.
-
Achtergrond en peiling vervolgens: POST met
background=true, en pollGET /responses/{id}totdat u klaar bent. -
Achtergrondstreaming, hervatten via stream: POST met
background=trueenstream=true; als de verbinding wegvalt, maakt u opnieuw verbinding metGET /responses/{id}enstream=true. -
Achtergrondstreaming, hervatten via poll: dezelfde start; als de verbinding wegvalt, peilt u
GET /responses/{id}naar het uiteindelijke resultaat.
Uw agent implementeren en er query's op uitvoeren
Nadat u uw agent met geheugen hebt geconfigureerd, volgt u de stappen in Een AI-agent ontwerpen en implementeert u deze in Apps om uw agent lokaal uit te voeren, te evalueren en te implementeren in Databricks Apps.