Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric is de volgende generatie van Azure Data Factory, met een eenvoudigere architectuur, ingebouwde AI en nieuwe functies. Als u nieuw bent in gegevensintegratie, begint u met Fabric Data Factory. Bestaande ADF-workloads kunnen upgraden naar Fabric om toegang te krijgen tot nieuwe mogelijkheden voor gegevenswetenschap, realtime analyses en rapportage.
Gegevensstromen zijn beschikbaar in zowel Azure Data Factory pijplijnen als Azure Synapse Analytics pijplijnen. Dit artikel is van toepassing op gegevensverwerkingsstromen. Als u nieuw bent met transformaties, raadpleegt u het inleidende artikel Gegevens transformeren met behulp van mapping-dataflows.
Tip
Zie Een handleiding voor Dataflow Gen2 voor gebruikers van gegevensstromen voor de equivalente transformatie (Query's samenvoegen) in Dataflow Gen2.
Gebruik de jointransformatie om gegevens uit twee bronnen of streams in een toewijzingsgegevensstroom te combineren. De uitvoerstroom bevat alle kolommen uit beide bronnen die overeenkomen op basis van een joinvoorwaarde.
Join-typen
Gegevensstromen in mapping ondersteunen momenteel vijf verschillende join-typen.
Inner Join (interne koppeling)
Inner join levert alleen rijen op met overeenkomende waarden in beide tabellen.
Linksbuitenste
Left outer join geeft alle rijen uit de linkerstream en overeenkomende records uit de rechterstream terug. Als een rij van de linkerstroom geen overeenkomst heeft, worden de uitvoerkolommen van de rechterstroom ingesteld op NULL. De uitvoer bestaat uit de rijen die worden geretourneerd door een inner join, plus de niet-matchende rijen uit de linkerstroom.
Notitie
De Spark-engine die door gegevensstromen wordt gebruikt, mislukt af en toe vanwege mogelijke cartesische producten in uw joinvoorwaarden. Als dit gebeurt, kunt u overschakelen naar een aangepaste cross join en handmatig uw joinvoorwaarde invoeren. Dit kan leiden tot tragere prestaties in uw gegevensstromen, omdat de uitvoeringsengine mogelijk alle rijen van beide zijden van de relatie moet berekenen en vervolgens rijen moet filteren.
Rechts buitenste
Right outer join haalt alle rijen uit de rechter stroom op en overeenkomende records uit de linkerstroom. Als een rij van de rechterstroom geen overeenkomst heeft, worden de uitvoerkolommen van de linkerstroom ingesteld op NULL. De uitvoer is de rijen die worden geretourneerd door een inner join plus de niet-overeenkomende rijen uit de rechterstroom.
Volledige Buitenste Join
Met volledige outer join worden alle kolommen en rijen van beide zijden uitgevoerd met NULL-waarden voor kolommen die niet overeenkomen.
Aangepaste cross join
Cross join levert het crossproduct van de twee streams op basis van een voorwaarde. Als u een voorwaarde gebruikt die geen gelijkheid is, geeft u een aangepaste expressie op als uw cross join-voorwaarde. De uitvoerstroom is alle rijen die voldoen aan de joinvoorwaarde.
U kunt dit jointype gebruiken voor non-equi joins en OR voorwaarden.
Als u expliciet een volledig cartesisch product wilt produceren, gebruikt u de transformatie Afgeleide Kolom in elk van de twee onafhankelijke streams voordat u de join uitvoert, om een synthetische sleutel te creëren waarop kan worden gekoppeld. Maak bijvoorbeeld een nieuwe kolom in Afgeleide Kolom in elke stroom, genaamd SyntheticKey, en stel deze gelijk aan 1. Gebruik dan a.SyntheticKey == b.SyntheticKey als uw aangepaste join-expressie.
Notitie
Zorg ervoor dat u ten minste één kolom van zowel de linker- als rechterrelatie moet opnemen in een aangepaste cross-join. Het uitvoeren van cross joins met statische waarden in plaats van kolommen van elke zijde resulteert in volledige scans van de volledige gegevensset, waardoor uw gegevensstroom slecht presteert.
Vage koppeling
U kunt ervoor kiezen om lid te worden op basis van fuzzy joinlogica in plaats van exacte kolomwaardekoppeling door het selectievakje 'Fuzzy matching gebruiken' in te schakelen.
- Tekstonderdelen combineren: gebruik deze optie om overeenkomsten te zoeken door spatie tussen woorden te verwijderen. Data Factory wordt bijvoorbeeld vergeleken met DataFactory als deze optie is ingeschakeld.
- Vergelijkingsscorekolom: u kunt er eventueel voor kiezen om de overeenkomende score voor elke rij in een kolom op te slaan door hier een nieuwe kolomnaam in te voeren om die waarde op te slaan.
- Drempelwaarde voor overeenkomsten: kies een waarde tussen 60 en 100 als een percentageovereenkomst tussen waarden in de kolommen die u hebt geselecteerd.

Notitie
Fuzzy matching werkt momenteel alleen met tekstkolomtypen en met inner -, left outer - en full outer-join-typen. U moet de optimalisatie van de uitzending uitschakelen wanneer u fuzzing overeenkomende joins gebruikt.
Configuratie
- Kies met welke gegevensstroom u deelneemt in de vervolgkeuzelijst Rechtse stroom .
- Selecteer uw jointype
- Kies op welke sleutelkolommen u wilt afstemmen voor de koppelingsvoorwaarde. Standaard zoekt de gegevensstroom naar gelijkheid tussen één kolom in elke stroom. Als u wilt vergelijken via een berekende waarde, plaatst u de muisaanwijzer op de keuzelijst kolom en selecteert u Berekende kolom.

Niet-equi joins
Als u een voorwaardelijke operator wilt gebruiken, zoals niet gelijk aan (!=) of groter dan (>) in uw joinvoorwaarden, moet u de vervolgkeuzelijst van de operator tussen de twee kolommen aanpassen. Voor niet-equi joins moet ten minste één van de twee streams worden uitgezonden met Fixed broadcasting op het tabblad Optimaliseren.

Join-prestaties optimaliseren
In tegenstelling tot samenvoegen in hulpprogramma's zoals SSIS, is de samenvoegtransformatie geen verplichte samenvoegbewerking. Voor de joinsleutels is geen sortering vereist. De join-bewerking gebeurt op basis van de optimale joinbewerking in Spark, ofwel een broadcast join of een map-side join.
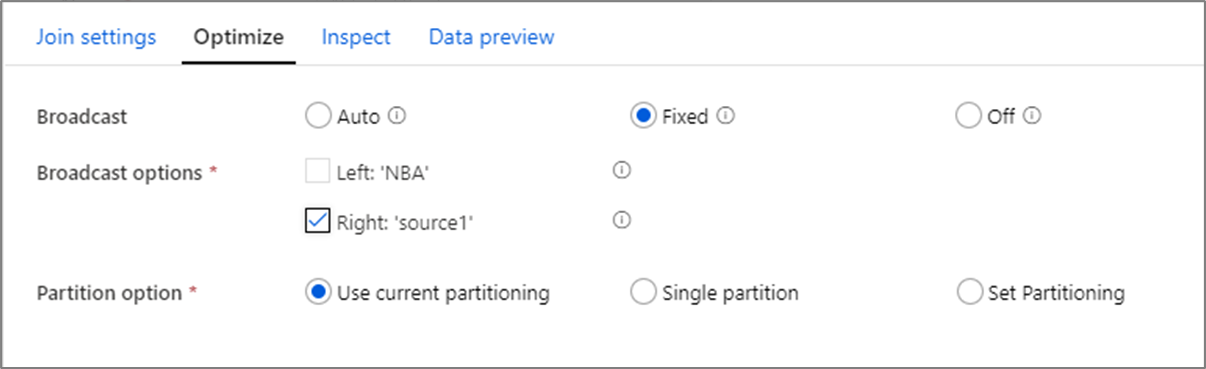
In joins, zoekopdrachten en exists-transformatie, als een of beide gegevensstromen in het geheugen van het werkknooppunt passen, kunt u de prestaties optimaliseren door Broadcasting in te schakelen. Standaard bepaalt de spark-engine automatisch of er wel of niet één zijde moet worden uitgezonden. Als u handmatig wilt kiezen welke kant u wilt uitzenden, selecteert u Vast.
Het is niet raadzaam om uitzenden uit te schakelen via de optie Uit, tenzij er time-out fouten optreden bij uw joins.
Zelf deelnemen
Als u zelf een gegevensstroom met zichzelf wilt koppelen, moet u een bestaande stroom aliasen met een selectietransformatie. Maak een nieuwe vertakking door op het pluspictogram naast een transformatie te klikken en Nieuwe vertakking te selecteren. Voeg een selectietransformatie toe om de oorspronkelijke stream te aliasen. Voeg een jointransformatie toe en kies de oorspronkelijke stroom als de linkerstroom en de selectietransformatie als de rechterstroom.

Het testen van join-voorwaarden
Wanneer u de jointransformaties test met een voorbeeld van gegevens in de foutopsporingsmodus, gebruikt u een kleine set bekende gegevens. Wanneer u rijen uit een grote gegevensset steekt, kunt u niet voorspellen welke rijen en sleutels worden gelezen voor testen. Het resultaat is niet-deterministisch, wat betekent dat uw samenvoegingsvoorwaarden mogelijk geen resultaten opleveren.
Script voor gegevensstroom
Syntaxis
<leftStream>, <rightStream>
join(
<conditionalExpression>,
joinType: { 'inner'> | 'outer' | 'left_outer' | 'right_outer' | 'cross' }
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <joinTransformationName>
Voorbeeld van een inner join
Dit voorbeeld is een join-transformatie met de naam JoinMatchedData die linkerstroom TripData en rechterstream TripFare neemt. De joinvoorwaarde is de expressie hack_license == { hack_license} && TripData@medallion == TripFare@medallion && vendor_id == { vendor_id} && pickup_datetime == { pickup_datetime} die waar retourneert als de kolommen hack_license, medallion, vendor_id en pickup_datetime in elke stroom overeenkomen. Het joinType is 'inner'. We schakelen uitzenden alleen in de linkerstream in, dus broadcast heeft waarde 'left'.
In de gebruikersinterface ziet deze transformatie er als volgt uit:
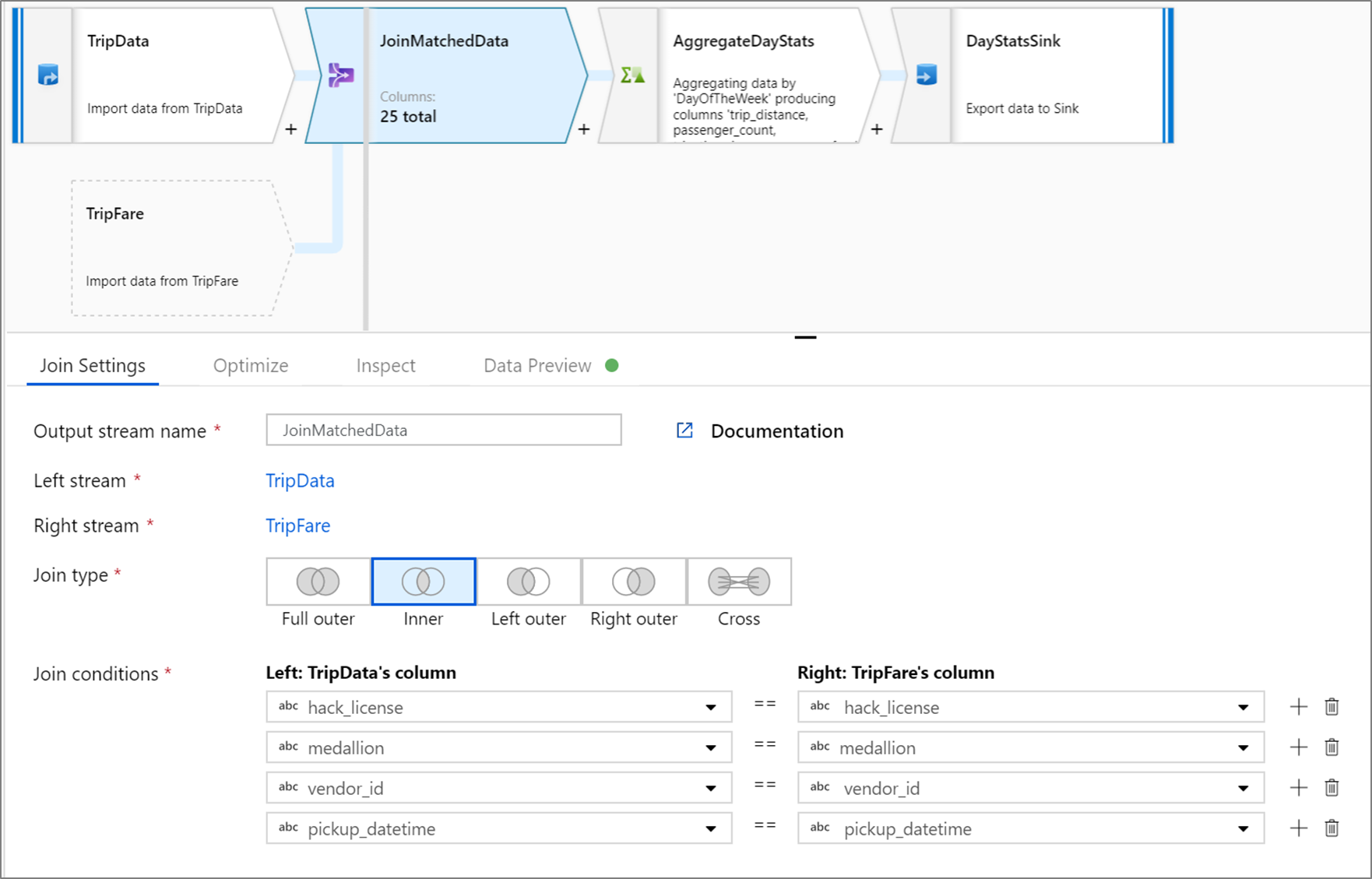
Het gegevensstroomscript voor deze transformatie bevindt zich in dit fragment:
TripData, TripFare
join(
hack_license == { hack_license}
&& TripData@medallion == TripFare@medallion
&& vendor_id == { vendor_id}
&& pickup_datetime == { pickup_datetime},
joinType:'inner',
broadcast: 'left'
)~> JoinMatchedData
Voorbeeld van aangepaste cross join
Dit voorbeeld is een jointransformatie met de naam JoiningColumns die de linkse stroom LeftStream en de rechter stroom RightStream neemt. Deze transformatie neemt twee streams in beslag en voegt alle rijen samen waarbij de kolom leftstreamcolumn groter is dan de kolom rightstreamcolumn. Het joinType is cross. Uitzenden is niet ingeschakeld broadcast heeft waarde 'none'.
In de gebruikersinterface ziet deze transformatie er als volgt uit:
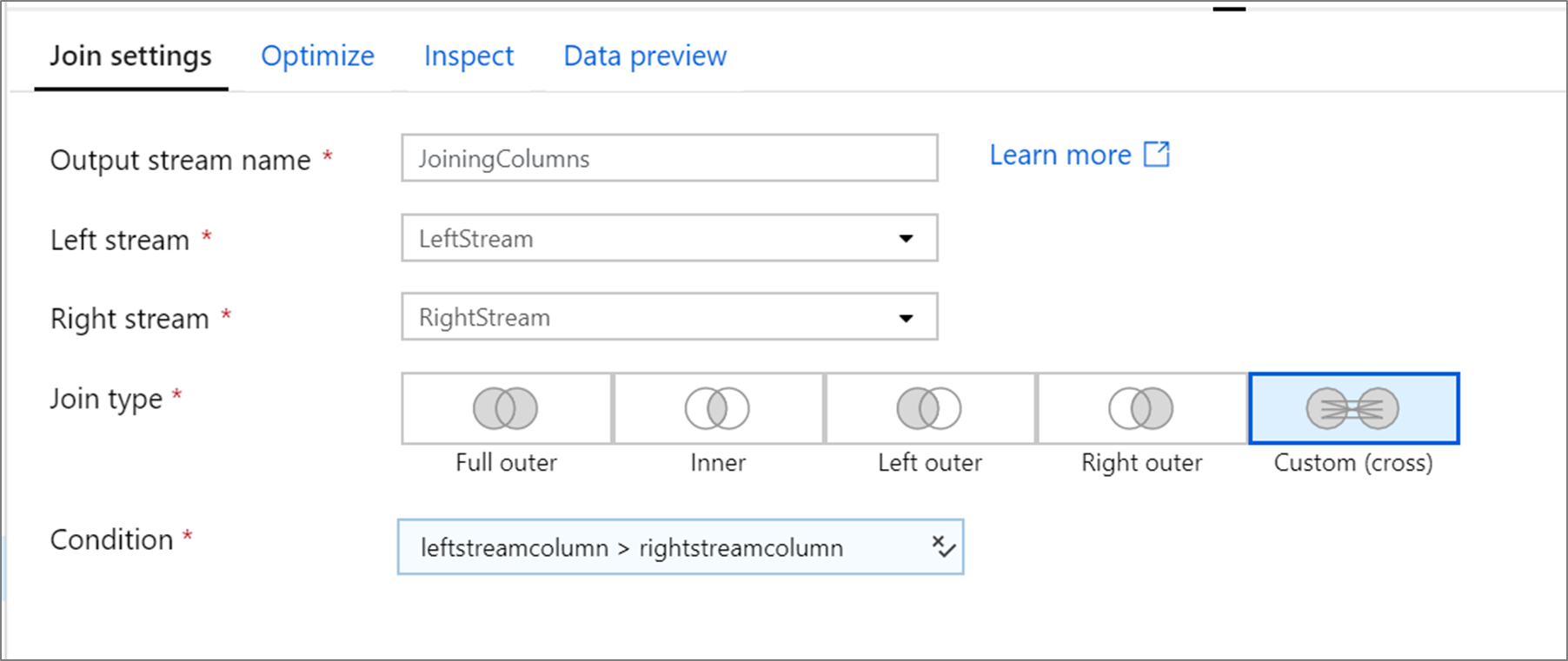
Het gegevensstroomscript voor deze transformatie bevindt zich in het fragment:
LeftStream, RightStream
join(
leftstreamcolumn > rightstreamcolumn,
joinType:'cross',
broadcast: 'none'
)~> JoiningColumns
Gerelateerde inhoud
Nadat u gegevens hebt gekoppeld, maakt u een afgeleide kolom en verplaatst u uw gegevens naar een doelgegevensarchief.