Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric is de volgende generatie van Azure Data Factory, met een eenvoudigere architectuur, ingebouwde AI en nieuwe functies. Als u nieuw bent in gegevensintegratie, begint u met Fabric Data Factory. Bestaande ADF-workloads kunnen upgraden naar Fabric om toegang te krijgen tot nieuwe mogelijkheden voor gegevenswetenschap, realtime analyses en rapportage.
Gegevensstromen zijn beschikbaar in zowel Azure Data Factory pijplijnen als Azure Synapse Analytics pijplijnen. Dit artikel is van toepassing op gegevensverwerkingsstromen. Als u nieuw bent met transformaties, raadpleegt u het inleidende artikel Gegevens transformeren met behulp van mapping-dataflows.
Tip
Zie Een gids voor Dataflow Gen2 voor het mappen van gegevensstroomgebruikers voor de equivalente transformatie (Aangepaste kolom) in Dataflow Gen2.
Gebruik de transformatie van afgeleide kolommen om nieuwe kolommen in uw gegevensstroom te genereren of om bestaande velden te wijzigen.
Kolommen maken en bijwerken
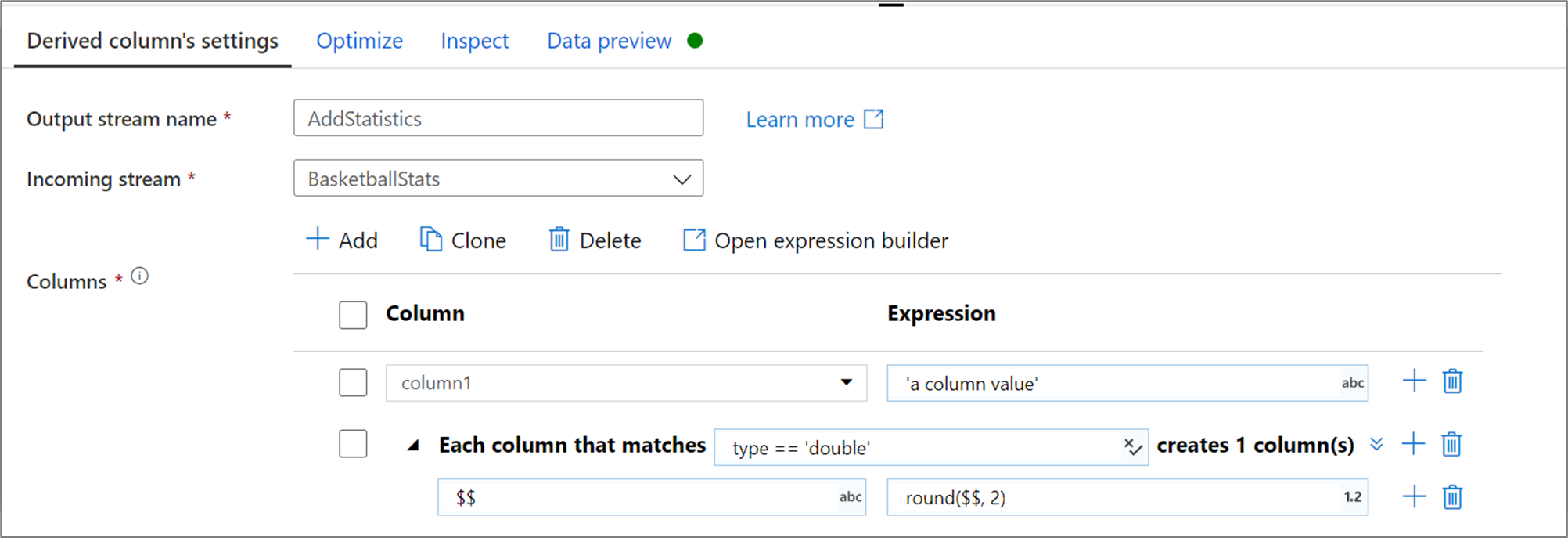
Wanneer u een afgeleide kolom maakt, kunt u een nieuwe kolom genereren of een bestaande kolom bijwerken. Voer in het tekstvak Kolom de kolom in die u maakt. Als u een bestaande kolom in uw schema wilt overschrijven, kunt u de kolom vervolgkeuzelijst gebruiken. Als u de expressie van de afgeleide kolom wilt maken, selecteert u het tekstvak Expressie invoeren . U kunt beginnen met het typen van uw expressie of de opbouwfunctie voor expressies openen om uw logica samen te stellen.

Als u meer afgeleide kolommen wilt toevoegen, selecteert u Toevoegen boven de kolomlijst of het pluspictogram naast een bestaande afgeleide kolom. Kies Kolom toevoegen of Kolompatroon toevoegen.

Kolompatronen
In gevallen waarin uw schema niet expliciet is gedefinieerd of als u een set kolommen bulksgewijs wilt bijwerken, moet u kolompatronen maken. Met kolompatronen kunt u kolommen vergelijken met behulp van regels op basis van de metagegevens van de kolom en afgeleide kolommen maken voor elke overeenkomende kolom. Voor meer informatie, leer hoe kolompatronen te bouwen in de afgeleide kolomtransformatie.
Schema's bouwen met de opbouwfunctie voor expressies
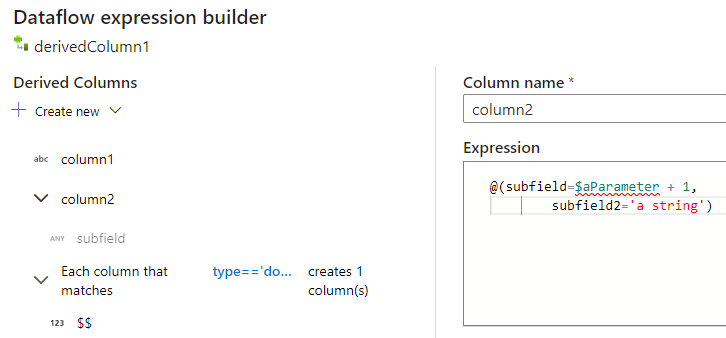
Wanneer u de expressiebouwer voor toewijzingsgegevensstromen gebruikt, kunt u uw afgeleide kolommen maken, bewerken en beheren in de Sectie Afgeleide Kolommen. Alle kolommen die in de transformatie worden gemaakt of gewijzigd, worden weergegeven. Kies interactief welke kolom of welk patroon u wilt bewerken door de kolomnaam te selecteren. Als u een andere kolom wilt toevoegen, selecteert u Nieuwe maken en kiest u of u één kolom of een patroon wilt toevoegen.

Wanneer u met complexe kolommen werkt, kunt u subkolommen maken. Hiervoor selecteert u het pluspictogram naast een kolom en selecteert u Subkolom toevoegen. Voor meer informatie over het verwerken van complexe typen in de gegevensstroom, zie JSON-verwerking in gegevensstroomtoewijzing.

Voor meer informatie over het verwerken van complexe typen in de gegevensstroom, zie JSON-verwerking in gegevensstroomtoewijzing.
Script voor gegevensstroom
Syntaxis
<incomingStream>
derive(
<columnName1> = <expression1>,
<columnName2> = <expression2>,
each(
match(matchExpression),
<metadataColumn1> = <metadataExpression1>,
<metadataColumn2> = <metadataExpression2>
)
) ~> <deriveTransformationName>
Voorbeeld
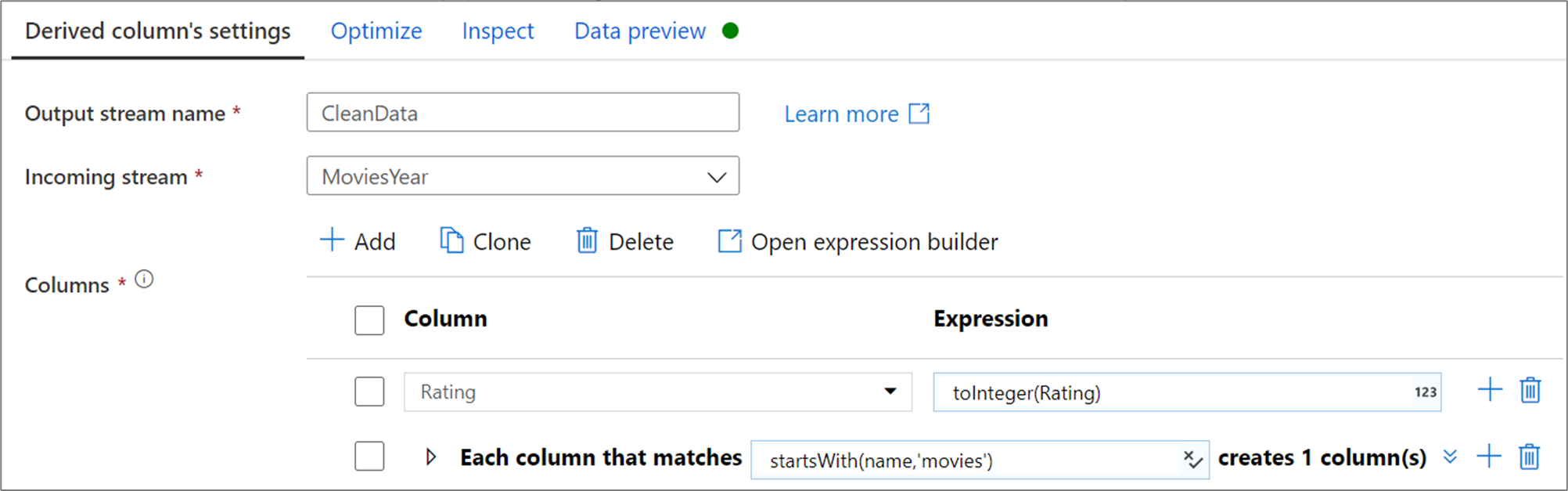
Het onderstaande voorbeeld is een afgeleide kolom met de naam CleanData die een binnenkomende stroom MoviesYear gebruikt en twee afgeleide kolommen maakt. De eerste afgeleide kolom vervangt de kolom Rating door de waarde van de Rating als een geheel getal. De tweede afgeleide kolom is een patroon dat overeenkomt met elke kolom waarvan de naam begint met 'films'. Voor elke overeenkomende kolom wordt een kolom movie gemaakt die gelijk is aan de waarde van de overeenkomende kolom met het voorvoegsel 'movie_'.
In de gebruikersinterface ziet deze transformatie eruit als in de onderstaande afbeelding:
Het gegevensstroomscript voor deze transformatie bevindt zich in het onderstaande codefragment:
MoviesYear derive(
Rating = toInteger(Rating),
each(
match(startsWith(name,'movies')),
'movie' = 'movie_' + toString($$)
)
) ~> CleanData
Gerelateerde inhoud
- Meer informatie over de Mapping Gegevensstroom expressietaal.