注
このチュートリアルはシリーズの一部です。 前のセクションについては、「 Real-Time Intelligence チュートリアル パート 6: Real-Time ダッシュボードを作成する」を参照してください。
異常検出は、データ内の異常なパターンを識別するのに役立つ Real-Time インテリジェンスの機能です。 チュートリアルのこのパートでは、ワークスペースに Anomaly Detector 項目を作成して、ステーションの空のドックの数の異常を検出する方法について説明します。
作業の開始
- 左側のナビゲーション バーから [ リアルタイム ] を選択して 、Real-Time ハブを開きます。
- [ すべてのデータ ストリーム] で、前のチュートリアルで作成した eventhouse テーブル TransformedData を選択します。 テーブルの詳細ページが開きます。 上部のメニューから [ 異常の検出 ] を選択します。
データベースと、分析する テーブル または ショートカット を選択します。
上部のツール バーで、[ Anomaly Detector の作成 ] を選択するか、データベース ツリーの省略記号 (⋯) から Anomaly Detector オプションを選択します。

![左側のナビゲーション ウィンドウの [Real-Time ハブ] ボタンのスクリーンショット。](media/anomaly-detection/real-time-hub.png)

![詳細ページの [異常の検出] オプションのスクリーンショット。](media/anomaly-detection/detect-details-page.png)

![Real-Time ハブの [Anomaly Detector の作成] ページのスクリーンショット。](media/anomaly-detection/real-time-hub-create-anomaly-detector-dialog.png)
![左側のナビゲーション ウィンドウの [作成] ボタンのスクリーンショット。](media/anomaly-detection/create-button.png)
![[異常検出] が選択されている [作成] ウィンドウのスクリーンショット。](media/anomaly-detection/create-anomaly-detection.png)
![[データ ソース] オプションが強調表示されている [異常検出の構成] ウィンドウのスクリーンショット。](media/anomaly-detection/add-source.png)
![[ソースの選択] ウィンドウのスクリーンショット。Eventhouse とテーブルが選択されています。](media/anomaly-detection/select-source.png)
異常検出を構成する
[ 属性の選択 ] セクションで、次のオプションを選択します。
フィールド 価値 監視する値 空のドックなし グループ化 Street タイムスタンプ タイムスタンプ 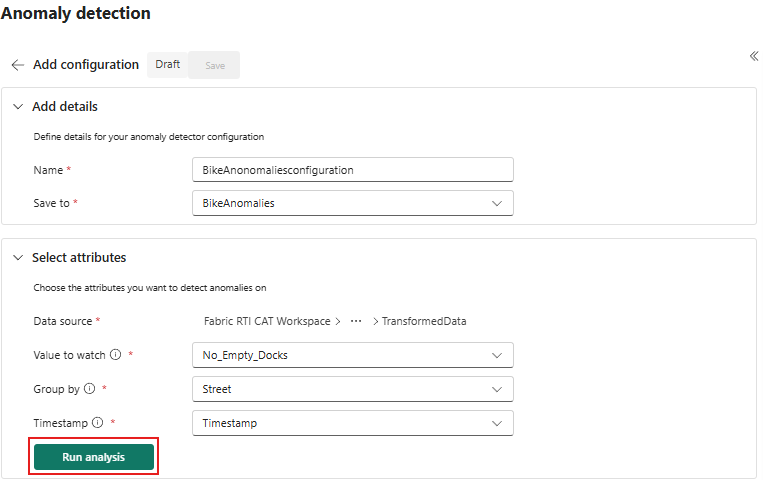
[Run analysis]\(解析の実行\) を選択します。
Important
通常、分析にはデータ サイズに応じて最大 4 分かかり、最大 30 分間実行できます。 ページから離れて移動し、分析が完了したらもう一度チェックインできます。
注
モデルの推奨事項と異常検出の精度を向上させるために、Eventhouse テーブルに十分な履歴データが含まれていることを確認します。 たとえば、1 日に 1 つのデータ ポイントを持つデータセットには数か月のデータが必要ですが、1 秒あたり 1 つのデータ ポイントを持つデータセットには数日しか必要ない場合があります。
分析が完了すると、異常と表形式のデータが右側に表示されます。

注
[検出のカスタマイズ] セクションで検出モデルを試し、[検出結果] ウィンドウの上にあるタイムスタンプを試します。 データが多いほど、異常検出の精度が向上する可能性があります。
保存 を選択します。


関連コンテンツ
このチュートリアルで実行されるタスクの詳細については、以下を参照してください。