この記事では、Eventhouse テーブル内の異常なパターンと外れ値を自動的に識別するように、Real-Time Intelligence で異常検出を設定する方法について説明します。 このシステムでは、推奨されるモデルが提供され、自動化されたアクションを使用して継続的な監視を設定できます。
主な機能は次のとおりです。
- モデルの推奨事項: データに最適なアルゴリズムとパラメーターを提案します。
- 対話型の異常探索: 検出された異常を視覚化し、モデルの感度を調整します。
- 継続的な監視: 自動通知を使用してリアルタイムの異常検出を設定します。
- 新しいデータを使用した再分析: 新しいデータが到着したらモデルを更新して精度を向上させます。
Important
この機能は プレビュー段階です。
[前提条件]
ワークスペースの管理者、共同作成者、またはメンバーのロール。
ワークスペース内の KQL データベースを含む Eventhouse。
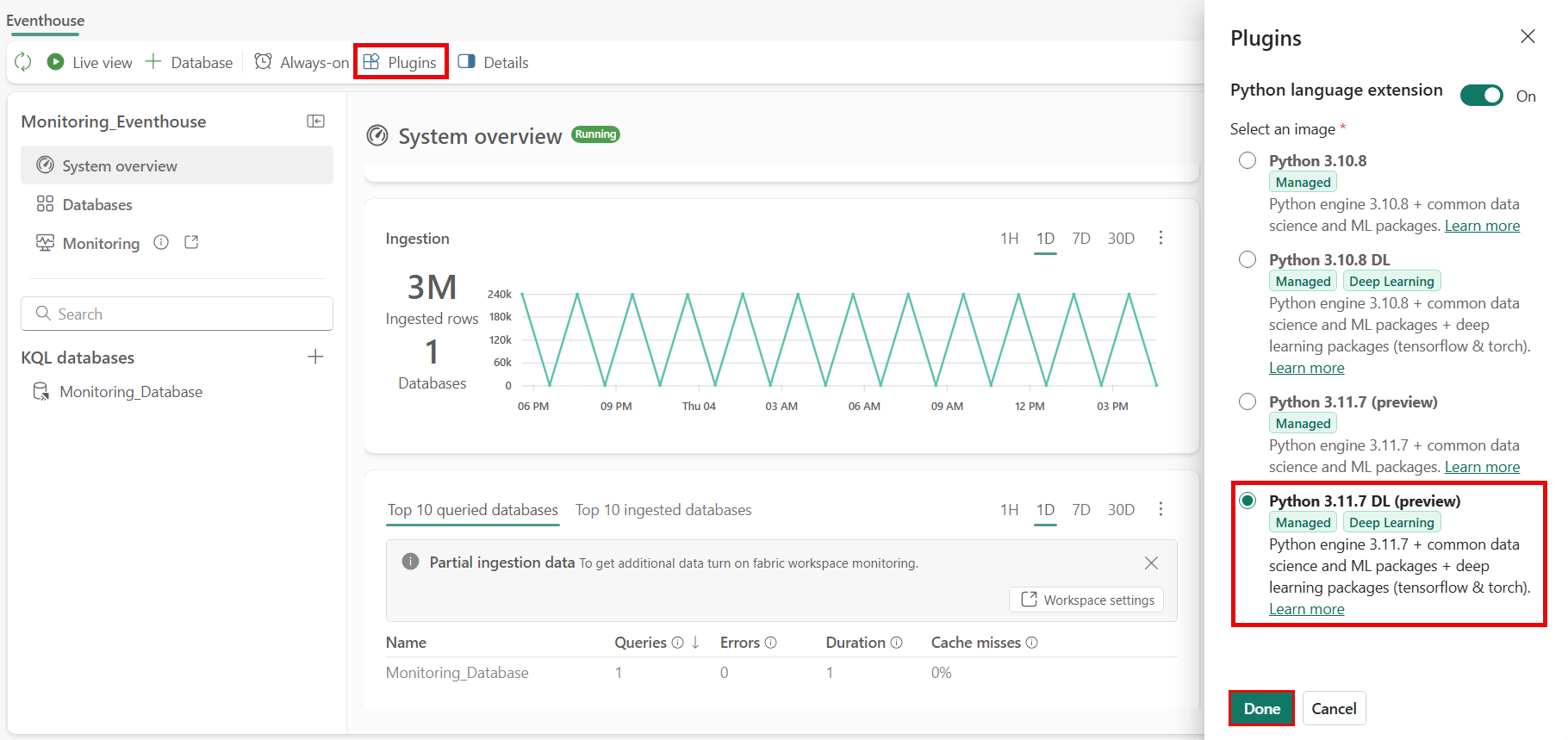
同じ Eventhouse で有効になっている Python プラグイン。
- プラグインを有効にするには、Eventhouse に移動します。
- 上部のツール バーで、[ プラグイン ] を選択し、 Python 言語拡張機能を有効にします。
- Python 3.11.7 DL プラグインを選択し、[ 完了] を選択します。

注
- モデルの推奨事項と異常検出の精度を向上させるために、Eventhouse テーブルに十分な履歴データが含まれていることを確認します。 たとえば、1 日に 1 つのデータ ポイントを持つデータセットには数か月のデータが必要ですが、1 秒あたり 1 つのデータ ポイントを持つデータセットには数日しか必要ない場合があります。
- この機能は、Microsoft Fabric が利用可能なすべてのリージョンで利用できます。
異常検出を設定する方法
作業の開始
異常検出は、次の 3 つの 方法で開始できます。
データベースと、分析する テーブル または ショートカット を選択します。
上部のツール バーで、[ Anomaly Detector の作成 ] を選択するか、データベース ツリーの省略記号 (⋯) から Anomaly Detector オプションを選択します。

![左側のナビゲーション ウィンドウの [Real-Time ハブ] ボタンのスクリーンショット。](media/anomaly-detection/real-time-hub.png)

![詳細ページの [異常の検出] オプションのスクリーンショット。](media/anomaly-detection/detect-details-page.png)

![Real-Time ハブの [Anomaly Detector の作成] ページのスクリーンショット。](media/anomaly-detection/real-time-hub-create-anomaly-detector-dialog.png)
![左側のナビゲーション ウィンドウの [作成] ボタンのスクリーンショット。](media/anomaly-detection/create-button.png)
![[異常検出] が選択されている [作成] ウィンドウのスクリーンショット。](media/anomaly-detection/create-anomaly-detection.png)
![[データ ソース] オプションが強調表示されている [異常検出の構成] ウィンドウのスクリーンショット。](media/anomaly-detection/add-source.png)
![[ソースの選択] ウィンドウのスクリーンショット。Eventhouse とテーブルが選択されています。](media/anomaly-detection/select-source.png)
分析用に入力列を構成する
分析する列と、データをグループ化する方法を指定します。
構成ウィンドウで、異常を監視する数値データを含む [ウォッチする値 ] 列を追加します。
![[監視対象の値]の構成設定のスクリーンショット。](media/anomaly-detection/value-to-watch.png)
注
異常検出では数値データのみがサポートされるため、選択した列に数値が含まれていることを確認します。
[ グループ化 ] 列を選択して、分析のためにデータをパーティション分割する方法を指定します。 この列は、通常、デバイス、場所、またはその他の論理グループなどのエンティティを表します。

各データ ポイントが記録された時刻を表す タイムスタンプ 列を選択します。 この列は、時系列の異常検出に不可欠であり、時間の経過に伴う傾向の正確な分析を保証します。

[ 分析の実行 ] を選択して、自動モデル評価を開始します。
分析の完了を待つ
システムはデータを分析して、最適な異常検出モデルを見つけます。
Important
通常、分析にはデータ サイズに応じて最大 4 分かかり、最大 30 分間実行できます。 別のページに移動し、分析が完了したら、もう一度確認できます。
分析中、システムは次の処理を行います。
- 効率的な処理のためにテーブル データをサンプリングする
- 複数の異常検出アルゴリズムをテストする
- さまざまなパラメーター構成を評価します
- 特定のデータ パターンに最も効果的なモデルを識別します
推奨されるモデルと異常を確認する
分析が完了したら、結果を確認し、検出された異常を調べます。
受信した通知を選択するか、テーブルに戻って [異常結果の表示] を選択して、 異常検出の結果を開きます。
結果ページには、次の分析情報が表示されます。
- 異常が明確に強調表示されたデータの 視覚化 。
- データの有効性によってランク付けされた 、推奨されるアルゴリズムの一覧。
- 検出しきい値を調整するための感度設定。
- 選択した時間範囲内で 検出された異常 の詳細な表。
モデル セレクターを使用して、さまざまな推奨アルゴリズムのパフォーマンスを比較し、ニーズに最適なものを選択します。
感度の設定を調整して、異常検出の結果を絞り込みます。
- オプションには、低、中、高の信頼レベルが含まれます。
- これらの設定を試して、より多くの異常を検出することと誤検知を減らすかのバランスを取ります。
ビジュアルとテーブルと対話して、検出された異常に関するより深い洞察を得て、データ内のパターンを理解します。
異常検出機能を保存して構成を保持し、後で再検討します。
検出された異常を Real-Time Hub に発行して、受信データを継続的に監視できるようにします。 Activator にアラートを送信するなど、ダウンストリーム アクションを構成することもできます。
結果を確認して微調整することで、異常検出のセットアップが特定のユース ケースに合わせて最適化されていることを確認できます。
新しいデータを使用して異常検出モデルを再分析する
新しいデータが利用可能になると、異常検出モデルを最新の状態に保ちます。
新しいデータでモデルを再分析するには、次の手順に従います。
- 異常検出項目に移動します。
- [編集] パネルで、必要に応じて、以前に入力したフィールドのいずれかを変更します。
- [Run analysis]\(解析の実行\) を選択します。 このアクションにより、更新された入力に基づいて新しい分析が開始されます。
Warnung
再分析では、既存の監視ルールによって使用されるモデルが更新され、ダウンストリーム アクションに影響する可能性があります。
異常検出イベントを調べてアラートを設定する
異常検出結果を公開した後、Real-Time Hub で検出された異常を調査し、将来の異常を通知するアラートを設定できます。 詳細については、以下を参照してください。
制限事項と考慮事項
現在の制限事項に注意してください。
- 入力テーブルが必要なスキーマ (数値列、datetime 列、文字列列) と一致しない場合、異常検出は無効になります。
- 十分な履歴データにより、モデルの推奨事項と精度が向上します。
- 各異常検出機能は、1 つのモデル構成のみをサポートします。
異常検出機能で複数の操作を実行する
異常検出機能と対話すると、Eventhouse はバックグラウンドで Python クエリを実行し、リアルタイム分析をサポートします。 記録される操作には次のようなものがあります。
- 異常検出またはその他の種類の分析を実行する。
- 推奨されるモデル間の切り替え。
- 表示している時間枠または ID を変更する。
- アラートを設定して、受信データの異常を継続的に監視します。
Eventhouse では、Eventhouse ごとに最大 8 つの同時クエリがサポートされます。 この制限を超えると、システムはクエリを再試行しますが、追加のクエリをキューに入れず、警告なしに失敗する可能性があります。 より明確なエラー メッセージが開発中です。
問題を回避するには:
- 新しいクエリを開始する前に、各クエリの完了を許可します。
- パフォーマンスが低下している、または応答していないと思われる場合は、同時実行クエリの数を減らします。
詳細については、「 Python プラグイン」を参照してください。
Python プラグインを有効にするための待機時間
データ分析を開始すると、異常検出機能によって Eventhouse で Python プラグインが自動的に有効になります。 プラグインを有効にするには、最大 1 時間かかることがあります。 有効にすると、分析が自動的に開始されます。
詳細については、「 Real-Time Intelligence で Python プラグインを有効にする」を参照してください。
次のステップ
異常検出を構成したら、次のことができます。