Important
この機能は プレビュー段階です。
Fabric Runtime は、Microsoft Fabric エコシステム内でシームレスな統合を実現し、Apache Spark を利用したデータ エンジニアリングおよびデータ サイエンス プロジェクト用の堅牢な環境を提供します。
この記事では、Microsoft Fabric のビッグ データ計算用に設計された最新のランタイムである Fabric Runtime 2.0 パブリック プレビューについて説明します。 このリリースをスケーラブルな分析と高度なワークロードにとって重要な一歩先に進める主な機能とコンポーネントについて説明します。
Fabric Runtime 2.0 には、データ処理機能を強化するために設計された次のコンポーネントとアップグレードが組み込まれています。
- Apache Spark 4.0
- オペレーティング システム: Azure Linux 3.0 (Mariner 3.0)
- Java: 21
- Scala: 2.13
- Python: 3.12
- Delta Lake: 4.0
- R: 4.5.2
ヒント
Fabric Runtime 2.0 には ネイティブ実行エンジンのサポートが含まれており、コストを増やすことなくパフォーマンスを大幅に向上させることができます。 ネイティブ実行エンジンを環境レベルで有効にして、すべてのジョブとノートブックが拡張パフォーマンス機能を自動的に継承するようにすることができます。
ランタイム 2.0 を有効にする
Runtime 2.0 は、ワークスペース レベルまたは環境項目レベルで有効にすることができます。 ワークスペース設定を使用して、ワークスペース内のすべての Spark ワークロードの既定値として Runtime 2.0 を適用します。 または、ランタイム 2.0 で環境項目を作成し、特定のノートブックまたは Spark ジョブ定義で使用します。これは、ワークスペースの既定値をオーバーライドします。
ワークスペース設定でランタイム 2.0 を有効にする
ワークスペース全体の既定値として Runtime 2.0 を設定するには:
Fabric ワークスペース内の [ワークスペース設定] ページに移動します。
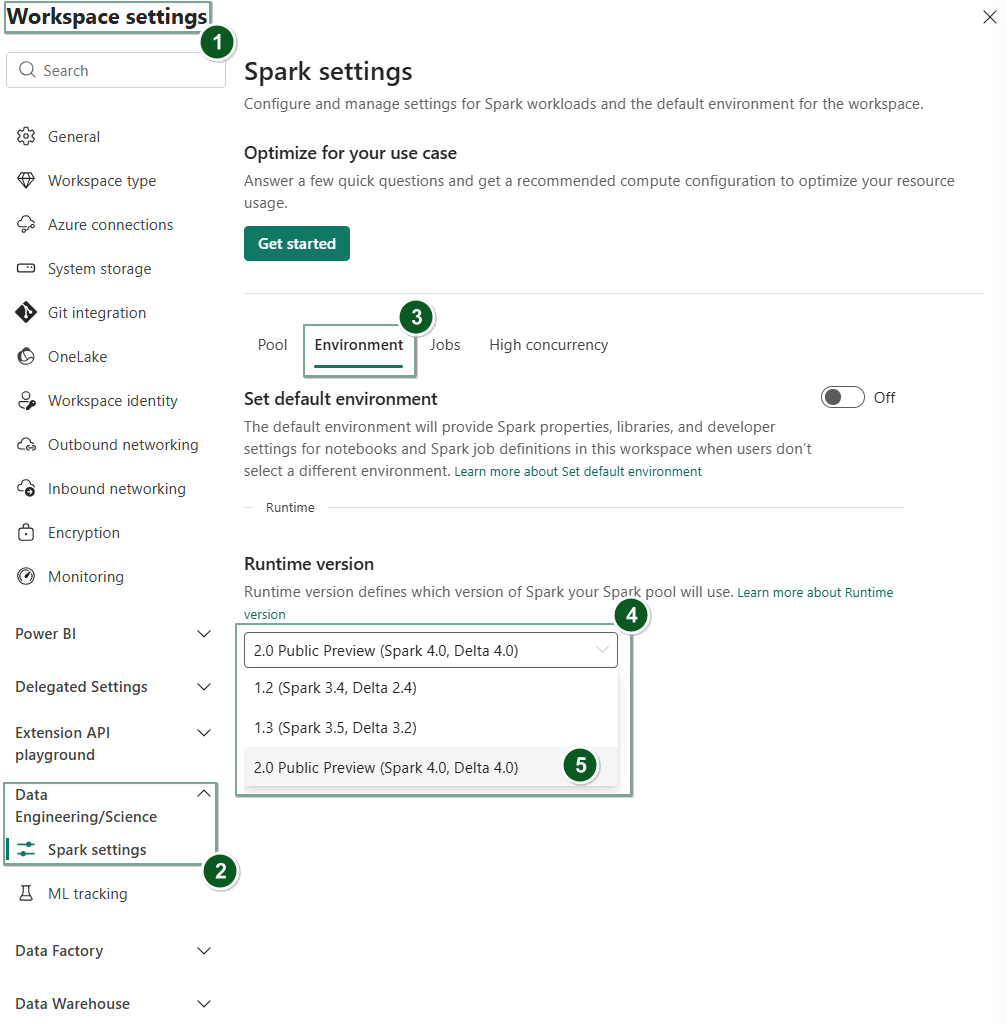
[ データ エンジニアリング/サイエンス ] タブを選択し、[ Spark の設定] を選択します。
[環境] タブを選択します。
[ ランタイム バージョン ] ドロップダウンで、 2.0 パブリック プレビュー (Spark 4.0、Delta 4.0) を選択し、変更を保存します。
ランタイム 2.0 は、ワークスペースの既定のランタイムとして設定されます。

環境項目でランタイム 2.0 を有効にする
特定のノートブックまたは Spark ジョブ定義で Runtime 2.0 を使用するには:
新しい 環境 項目を作成するか、既存の環境項目を開きます。
[ ランタイム ] ドロップダウンで、 2.0 パブリック プレビュー (Spark 4.0、Delta 4.0) を選択し、変更を
SaveしてPublishします。![[環境] 項目のランタイム バージョンを選択する場所を示すスクリーンショット。](media/mrs/runtime-2-environment.png)
次に、または
NotebookでこのSpark Job Definition項目を使用できます。
![[環境] 項目のランタイム バージョンを選択する場所を示すスクリーンショット。](media/mrs/runtime-2-environment.png#lightbox)
これで、Fabric Runtime 2.0 (Spark 4.0 および Delta Lake 4.0) で導入された最新の機能強化と機能の実験を開始できます。
ヒント
Runtime 2.0 の最初の Spark セッションの起動には、パブリック プレビュー中に数分かかる場合があります。 コールド スタートの遅延を減らすには、カスタム ライブ プール (プレビュー) を使用して Spark プールを事前にウォームアップするか、リソース プロファイルを構成してリソースを事前に割り当てます。
注
General Purpose v2 (GPv2) Azure Storage アカウントの WASB プロトコルは非推奨です。 GPv2 ストレージ アカウントの読み取りと書き込みには、代わりに最新の ABFS プロトコルを使用する必要があります。
パブリック プレビュー
Fabric Runtime 2.0 パブリック プレビュー ステージでは、Spark 4.0 と Delta Lake 4.0 の両方から新機能と API にアクセスできます。 プレビューでは、最新の Spark および Delta ベースの拡張機能をすぐに使用できます。また、新しい Java、Scala、Python バージョンなどの強化および改善された変更に対するスムーズな準備と移行を保証できます。
ヒント
最新の情報、変更の詳細な一覧、および Fabric ランタイムの特定のリリース ノートについては、Spark ランタイムのリリースと更新を確認しサブスクライブしてください。
主なハイライト
パフォーマンスと実行エンジンの機能強化
Fabric Runtime 2.0 には ネイティブ実行エンジンが含まれており、オープンソースの Spark よりもパフォーマンスが大幅に向上します。 エンジンはベクター化された処理を使用して、コードの変更を必要とせずに Lakehouse インフラストラクチャに対する Spark クエリを高速化します。
Runtime 2.0 の主なパフォーマンス機能:
- 最大 6 倍高速: ベンチマークは、TPC-DS ワークロード上のオープンソースの Spark と比較して最大 6 倍のパフォーマンスを示します。
- ベクター化された CSV 解析: ネイティブ実行エンジンには、CSV インジェストとクエリのワークロードを高速化するベクター化された CSV パーサーが含まれています。 ベクター化された JSON 解析と Spark 構造化ストリーミングのサポートは、今後の更新のために計画されています。
ネイティブ実行エンジンを有効にするには、 Fabric Data Engineering のネイティブ実行エンジンを参照してください。
Apache Spark 4.0
Apache Spark 4.0 は、4.x シリーズの初版リリースとして重要なマイルストーンをマークし、活気に満ちたオープンソース コミュニティの集合的な取り組みを体現しています。
このバージョンでは、SPARK SQL は、VARIANT データ型のサポート、SQL ユーザー定義関数、セッション変数、パイプ構文、文字列照合順序など、SQL ワークロードの表現力と汎用性を高めるために設計された強力な新機能で大幅に強化されています。 PySpark は、機能の幅と全体的な開発者エクスペリエンスの両方に継続的に取り組み、ネイティブプロット API、新しい Python データ ソース API、Python UDF のサポート、PySpark UDF の統合プロファイリング、およびその他の多くの機能強化を実現しています。 構造化ストリーミングは、より制御とデバッグの容易さを提供する重要な追加機能と共に進化します。特に、より柔軟な状態管理のための任意の State API v2 の導入と、デバッグを容易にする状態データ ソースの導入です。
完全な一覧と詳細な変更については、https://spark.apache.org/releases/spark-release-4-0-0.html をチェックしてください。
注
Spark 4.0 では、SparkR は非推奨となり、将来のバージョンで削除される可能性があります。
Delta Lake 4.0
Delta Lake 4.0 は、Delta Lake を複数の形式で相互運用可能にし、操作しやすく、パフォーマンスを高めるという一括コミットメントを示しています。 Delta 4.0 は、オープン データ レイクハウスの将来に向けた強力な新機能、パフォーマンスの最適化、および基本的な機能強化が満載されたマイルストーン リリースです。
Delta Lake 3.3 および 4.0 で導入された完全な一覧と詳細な変更については、 https://github.com/delta-io/delta/releases/tag/v3.3.0を参照してください。 https://github.com/delta-io/delta/releases/tag/v4.0.0。
データのレイアウトと最適化
ランタイム 2.0 では、デルタ テーブルのデータ レイアウトと最適化機能がサポートされています。
- Z オーダー: デルタ テーブル ファイル内のデータを指定された列で整理し、フィルター処理されたクエリのクエリ パフォーマンスを向上させます。
- 液体クラスタリング:手動メンテナンスなしでデータレイアウトを自動的に最適化する柔軟なクラスタリングアプローチ。
- 並列差分スナップショットの読み込み: ネイティブ実行エンジンは Delta テーブル スナップショットを並列に読み込み、大規模なテーブルのクエリの起動時間を短縮します。
Important
Delta Lake 4.0 固有の機能は試験的であり、ノートブックや Spark ジョブ定義などの Spark エクスペリエンスでのみ機能します。 複数の Microsoft Fabric ワークロードで同じ Delta Lake テーブルを使用する必要がある場合は、これらの機能を有効にしないでください。 すべての Microsoft Fabric エクスペリエンスで互換性のあるプロトコルのバージョンと機能の詳細については、 Delta Lake テーブル形式の相互運用性に関するページを参照してください。
ランタイム 2.0 でのコンピューティング管理
ランタイム 2.0 では、次のコンピューティング管理機能がサポートされています。
- リソース プロファイル: ワークロードの要件に合わせて Spark セッションの定義済みのリソース割り当てを構成し、コストを制御します。
- カスタム ライブ プール (プレビュー):セッションの起動時間を短縮する専用の事前ウォーミングされた Spark プールを作成します。 カスタム ライブ プールは、ランタイム 2.0 ワークロードのプレビューで利用できます。
制限事項と注意事項
- Delta Lake 4.0 固有の機能は試験段階であり、ノートブックや Spark ジョブ定義などの Spark エクスペリエンスでのみ機能します。 複数の Fabric ワークロードで同じ Delta Lake テーブルを使用する必要がある場合は、これらの機能を有効にしないでください。 詳細については、「 Delta Lake テーブル形式の相互運用性」を参照してください。
- ランタイム 2.0 はパブリック プレビュー段階です。 一部の機能と API は、一般公開前に変更される可能性があります。
- Fabric Spark 用の VS Code 拡張機能では、ノートブックおよび Spark ジョブ定義開発用のランタイム 2.0 がサポートされています。