ネイティブ実行エンジンは、Microsoft Fabric での Apache Spark ジョブ実行の画期的な機能強化です。 このベクター化されたエンジンでは、Lakehouse インフラストラクチャで直接実行することで、Spark クエリのパフォーマンスと効率を最適化します。 エンジンのシームレスな統合は、コードの変更を必要とせず、ベンダーのロックインが回避されます。 Apache Spark API をサポートし、 Runtime 1.3 (Apache Spark 3.5) および Runtime 2.0 (Apache Spark 4.0) と互換性があり、Parquet、Delta、CSV の形式で動作します。 OneLake 内のデータの場所に関係なく、またはショートカットを使用してデータにアクセスする場合でも、ネイティブ実行エンジンは効率とパフォーマンスが最大化します。
ネイティブ実行エンジンは、運用コストを最小限に抑えながら、クエリのパフォーマンスが大幅に向上します。 実際の結果は、ワークロードの特性と構成によって異なります。 エンジンは、ルーチン データ インジェスト、バッチ ジョブ、ETL (抽出、変換、読み込み) タスクから複雑なデータ サイエンス分析や応答性の高い対話型クエリまでの、さまざまなデータ処理シナリオの管理に熟達しています。 ユーザーは、処理時間の短縮、スループットの向上、リソース使用率の最適化の恩恵を受けます。
ネイティブ実行エンジンは、2 つの主要な OSS コンポーネントに基づいています。Meta によって導入された C++ データベース アクセラレーション ライブラリである Velox と、Intel によって導入されたネイティブ エンジンに JVM ベースの SQL エンジンの実行をオフロードする中間層である Apache Gluten (incubating) です。
サポートされる演算子は、JVM ベースの Spark からベクター化された C++ 実行パスにオフロードされ、Parquet 形式と Delta 形式をネイティブにサポートする、列形式の SIMD 高速処理が提供されます。 ネイティブ エンジンでは、アダプティブ クエリ実行 (AQE)、コストベースの書き換え、列の排除、述語のプッシュダウンなど、Fabric Spark クエリの主要な最適化が保持されるため、これらのオプティマイザーの動作は、演算子がオフロードされるときに完全にアクティブなままです。 また、エンジンは並列差分スナップショットの読み込みをサポートし、デルタ テーブルでの Z オーダーと Liquid Clustering の利点を活用する操作を高速化し、整理されたデータ レイアウトのパフォーマンスをさらに向上させます。
ネイティブ実行エンジンを使用するタイミング
ネイティブ実行エンジンでは、大規模なデータ セットに対してクエリを実行するためのソリューションを提供します。基になるデータ ソースのネイティブ機能を使用してパフォーマンスを最適化し、従来の Spark 環境でのデータ移動とシリアル化に通常関連するオーバーヘッドを最小限に抑えます。 エンジンは、ロールアップ ハッシュ集計、ブロードキャスト入れ子ループ結合 (BNLJ)、正確なタイムスタンプ形式など、さまざまな演算子とデータ型のサポートをしています。 ただし、エンジンの機能を最大限に活用するには、最適なユース ケースを検討することが必要です。
- エンジンは、Parquet 形式とデルタ形式のデータを操作する場合に効果的であり、ネイティブかつ効率的に処理ができます。
- 複雑な変換と集計を伴うクエリは、エンジンの縦棒処理とベクター化機能により大きなメリットを得られます。
- パフォーマンスの向上は、サポートされていない機能や式を回避してクエリがフォールバック メカニズムをトリガーしないシナリオで最も顕著です。
- エンジンは、単純または I/O バインドではなく、計算負荷の高いクエリに適しています。
ネイティブ実行エンジンでサポートされる演算子と関数の詳細については、Apache Gluten のドキュメントを参照してください。
ネイティブ実行エンジンを有効にする
プレビュー フェーズ中にネイティブ実行エンジンのすべての機能を使用するには、特定の構成が必要となります。 次の手順では、ノートブック、Spark ジョブ定義、および環境全体に対してこの機能をアクティブ化する方法が示されます。
重要
ネイティブ実行エンジンは、 ランタイム 1.3 (Apache Spark 3.5、Delta Lake 3.2) と Runtime 2.0 (Apache Spark 4.0、Delta Lake 4.0) をサポートしています。 ランタイム 1.3 でのネイティブ実行エンジンのリリースにより、以前のバージョン の Runtime 1.2 (Apache Spark 3.4、Delta Lake 2.4) のサポートは廃止されました。 すべてのお客様に、最新の Runtime 1.3 にアップグレードすることをお勧めします。 ランタイム 1.2 でネイティブ実行エンジンを使用している場合、ネイティブ アクセラレーションは無効になります。
環境レベルで有効にする
パフォーマンスの向上を確実に統一するには、環境に関連付けられているジョブとノートブックすべてでネイティブ実行エンジンを有効にします。
環境が含まれているワークスペースに移動し、環境を選択します。 環境を作成していない場合は、「 Fabric で環境を作成、構成、および使用する」を参照してください。
Spark コンピューティング で Acceleration を選択します。
[ネイティブ実行エンジンを有効にする] のラベルが付いたボックスをオンにします。
変更を保存して発行します。
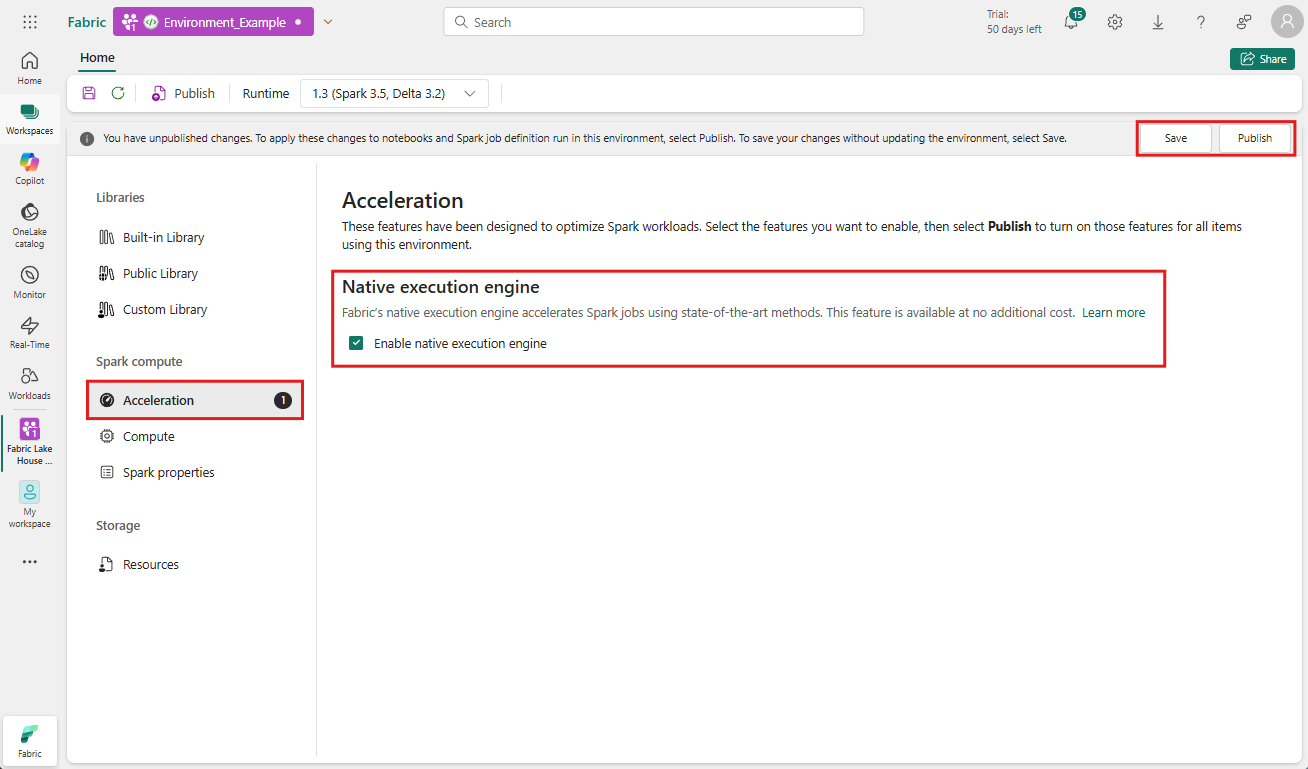

環境レベルで有効にする場合、後続のすべてのジョブとノートブックが設定を継承します。 この継承で、環境内で作成された新しいセッションまたはリソースは、拡張された実行機能の恩恵を自動的に受けることができます。
重要
以前は、ネイティブ実行エンジンは、環境内の Spark 設定を使用して有効にされていました。 環境設定の [高速化 ] タブのトグルを使用して、ネイティブ実行エンジンをより簡単に有効にできるようになりました。 引き続き使用するには、[ アクセラレーション ] タブに移動し、トグルをオンにします。 必要に応じて、Spark プロパティを使用して有効にすることもできます。
ノートブックまたは Spark ジョブ定義を有効化する
単一のノートブックまたは Spark ジョブ定義に対してネイティブ実行エンジンを有効にすることもできます。実行スクリプトの先頭に必要な構成を組み込む必要があります。
%%configure
{
"conf": {
"spark.native.enabled": "true",
}
}
ノートブックの場合、最初のセルに必要な構成コマンドを挿入します。 Spark ジョブ定義の場合は、構成を Spark ジョブ定義の先頭に含めてください。 ネイティブ実行エンジンはライブ プールと統合されるため、、新しいセッションを開始しなくても、機能を有効にするとすぐに有効になります。
クエリ レベルでの制御
テナント、ワークスペース、環境の各レベルでネイティブ実行エンジンを有効にするメカニズムは、UI とシームレスに統合され、開発が進められています。 その間、特定のクエリ、特に現在サポートされていない演算子を含むクエリについては、ネイティブ実行エンジンを無効にすることができます (「制限事項」を参照)。 無効にするには、クエリなど特定のセルに対して Spark 構成 spark.native.enabled を false に設定します。
%%sql
SET spark.native.enabled=FALSE;

ネイティブ実行エンジンが無効になっているクエリを実行した後、spark.native.enabled を true に設定して、後続のセルに対して再度有効にすることが必要です。 Spark はコード セルを順番に実行するために、この手順が必要です。
%%sql
SET spark.native.enabled=TRUE;
エンジンによって実行される操作を識別
Apache Spark ジョブのオペレーターがネイティブ実行エンジンを使用して処理されたかどうかの判断には、いくつかの方法があります。
Spark UI と Spark 履歴サーバー
Spark UI または Spark 履歴サーバーにアクセスして、検査する必要のあるクエリを見つけます。 Spark Web UI にアクセスするには、Spark ジョブ定義に移動して実行します。 [

Spark UI インターフェイス内に表示されるクエリ プランで、サフィックス Transformer、*NativeFileScan、または VeloxColumnarToRowExecで終わるノード名を探します。 サフィックスは、ネイティブ実行エンジンが操作を実行したことを表示します。 たとえば、ノードには RollUpHashAggregateTransformer、ProjectExecTransformer、BroadcastHashJoinExecTransformer、ShuffledHashJoinExecTransformer、BroadcastNestedLoopJoinExecTransformer などのラベルが付けられます。 CSV データ ソースの場合、ネイティブ スキャンは、Parquet および Delta スキャン ノードと同様に、Spark UI でネイティブ ファイル スキャンまたはトランスフォーマー ノードとして表示される場合があります。

DataFrame の説明
または、ノートブックでコマンドを df.explain() 実行して実行プランを表示することもできます。 出力内で、同じ Transformer、*NativeFileScan、または VeloxColumnarToRowExec サフィックスを探します。 このメソッドは、特定の操作がネイティブ実行エンジンによって処理されているかどうかを簡単に確認する方法を提供します。

Fabric Spark Advisor アラート
Fabric Spark Advisor は、ノートブック セルの実行中にリアルタイムのフォールバック可視性を提供します。 オペレーターまたはプラン セグメントがネイティブ パスではなく JVM ベースの Spark にフォールバックすると、Advisor はノートブック セルの出力にアラートを直接表示し、ノートブックから離れることなく、サポートされていないオペレーターや構成をすばやく特定するのに役立ちます。 これらのアラートを使用して、ネイティブ オフロードが適用されていないタイミングを診断し、クエリまたは構成を調整するかどうかを決定できます。
フォールバック メカニズム
サポートされていない機能などの理由によって、ネイティブ実行エンジンがクエリを実行できない場合があります。 このような場合は、操作は従来の Spark エンジンにフォールバックします。 この自動フォールバック メカニズムにより、ワークフローが中断されることがなくなります。


エンジンによって実行されるクエリとデータフレームを監視する
ネイティブ実行エンジンが SQL クエリと DataFrame 操作にどのように適用されるかを理解し、ステージと演算子レベルにドリルダウンするには、Spark UI と Spark History Server を参照してネイティブ エンジンの実行に関する詳細を参照してください。
[ネイティブ実行エンジン] タブ
新しい [Gluten SQL/ DataFrame] タブに移動すると、Gluten のビルド情報とクエリ実行の詳細を表示できます。 [クエリ] テーブルには、ネイティブ エンジンで実行されているノードの数と、クエリごとに JVM にフォールバックするノードの数に関する分析情報が表示されます。

クエリの実行グラフ
Apache Spark クエリ実行プランの視覚化のクエリの説明を選択することもできます。 実行グラフには、ステージとそれぞれの操作にわたるネイティブ実行の詳細が表示されます。 背景色で実行エンジンを区別できます。緑色はネイティブ実行エンジンを表し、水色は操作が既定の JVM エンジンで実行されていることを示します。

制限事項
Microsoft Fabric のネイティブ実行エンジン (NEE) は Apache Spark ジョブのパフォーマンスを大幅に向上させますが、現在、次の制限があります。
既存の制限事項
互換性のない Spark 機能: ネイティブ実行エンジンは、現在、ユーザー定義関数 (UDF)、
array_contains関数、または構造化ストリーミングをサポートしていません。 これらの関数またはサポートされていない機能が直接またはインポートされたライブラリを介して使用されている場合、Spark は既定のエンジンに戻ります。サポートされていないファイル形式:
JSON形式とXML形式に対するクエリは、ネイティブ実行エンジンによって高速化されません。 これらの既定値は、通常の Spark JVM エンジンに戻って実行されます。 CSV は、ベクター化された CSV パーサーを使用してサポートされるようになりました。ANSI モードはサポートされていません。ネイティブ実行エンジンは ANSI SQL モードをサポートしていません。 有効にすると、実行はバニラ Spark エンジンにフォールバックします。
日付フィルターの種類の不一致: ネイティブ実行エンジンの高速化のメリットを得るために、日付比較の両側がデータ型で一致していることを確認します。 たとえば、
DATETIME列と文字列リテラルを比較する代わりに、次のように明示的にキャストします。CAST(order_date AS DATE) = '2024-05-20'
その他の考慮事項と制限事項
10 進数から浮動小数点数へのキャストの不一致:
DECIMALからFLOATにキャストする場合、Spark は文字列に変換して解析することで精度を維持します。 NEE (Velox 経由) は、内部のint128_t表現から直接変換を行うため、丸め誤差が生じる可能性があります。タイムゾーンの構成エラー : Spark で認識できないタイムゾーンを設定すると、ジョブは NEE で失敗しますが、Spark JVM では正常に処理されます。 例えば次が挙げられます。
"spark.sql.session.timeZone": "-08:00" // May cause failure under NEE一貫性のない丸め動作:
round()関数は、Spark の丸めロジックをレプリケートしないstd::roundに依存しているため、NEE で動作が異なります。 これにより、結果の丸めで数値の不整合が発生する可能性があります。map()関数に重複するキー チェックがありません:spark.sql.mapKeyDedupPolicyが EXCEPTION に設定されている場合、Spark は重複するキーのエラーをスローします。 NEE は現在、このチェックをスキップし、クエリが正しく成功しません。
例:SELECT map(1, 'a', 1, 'b'); -- Should fail, but returns {1: 'b'}並べ替えによる
collect_list()の順序の差異:DISTRIBUTE BYとSORT BYを使用する場合、Spark は要素の順序をcollect_list()で保持します。 NEE は、シャッフルの違いにより異なる順序で値を返す可能性があり、順序指定に依存するロジックに対する期待が一致しない可能性があります。collect_list()/collect_set()の中間型の不一致: Spark では、これらの集計の中間型としてBINARYが使用されますが、NEE ではARRAYが使用されます。 この不一致は、クエリの計画または実行中に互換性の問題につながる可能性があります。ストレージ アクセスに必要なマネージド プライベート エンドポイント: ネイティブ実行エンジン (NEE) が有効になっていて、Spark ジョブがマネージド プライベート エンドポイントを使用してストレージ アカウントにアクセスしようとしている場合、ユーザーは、同じストレージ アカウントを指している場合でも、BLOB (blob.core.windows.net) エンドポイントと DFS/ファイル システム (dfs.core.windows.net) エンドポイントの両方に対して個別のマネージド プライベート エンドポイントを構成する必要があります。 1 つのエンドポイントを両方に再利用することはできません。 これは現在の制限事項であり、ストレージ アカウントに対してマネージド プライベート エンドポイントを持つワークスペースでネイティブ実行エンジンを有効にする場合は、追加のネットワーク構成が必要になる場合があります。