適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
Data Factory in Microsoft Fabric は、よりシンプルなアーキテクチャ、組み込みの AI、および新機能を備えた次世代のAzure Data Factoryです。 データ統合を初めて使用する場合は、Fabric Data Factory から始めます。 既存の ADF ワークロードをFabricにアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
このチュートリアルでは、Azure ポータルを使用して、Databricks ジョブ クラスターに対して Databricks ノートブックを実行するAzure Data Factory パイプラインを作成します。 また、実行中Azure Data Factoryパラメーターを Databricks ノートブックに渡します。
このチュートリアルでは、以下の手順を実行します。
データ ファクトリを作成します。
Databricks Notebook アクティビティを使用するパイプラインを作成します。
パイプラインの実行をトリガーする。
パイプラインの実行を監視します。
Azure サブスクリプションがない場合は、開始する前に free アカウントを作成します。
注
ライブラリの使用や、入力と出力のパラメーターの受け渡しなど、Databricks ノートブック アクティビティの使用方法について詳しくは、Databricks ノートブック アクティビティのドキュメントをご覧ください。
前提条件
- Azure Databricks ワークスペース。 Databricks ワークスペースを作成するか、既存のワークスペースを使用します。 Azure Databricks ワークスペースにPython ノートブックを作成します。 次に、ノートブックを実行し、Azure Data Factoryを使用してパラメーターを渡します。
Data Factory の作成
Microsoft EdgeまたはGoogle Chrome Web ブラウザーを起動します。 現在、Data Factory UI は、Microsoft Edgeおよび Google Chrome Web ブラウザーでのみサポートされています。
Azure ポータル メニューリソースの作成を選択し、Analytics>Data Factory を選択します。
![[新規] ウィンドウでの [Data Factory] の選択を示すスクリーンショット。](media/doc-common-process/new-azure-data-factory-menu.png)
Create Data Factory ページの Basics タブで、データ ファクトリを作成する Azure Subscription を選択します。
[リソース グループ] で、次の手順のいずれかを行います。
ドロップダウン リストから既存のリソース グループを選択します。
[新規作成] を選択し、新しいリソース グループの名前を入力します。
リソース グループの詳細については、「リソース グループを使用してAzure リソースを管理するを参照してください。
[リージョン] で、データ ファクトリの場所を選択します。
この一覧には、Data Factory でサポートされている場所と、Azure Data Factoryメタデータが格納される場所のみが表示されます。 関連付けられているデータ ストア (Azure StorageやAzure SQL Databaseなど) と、Data Factory が使用するコンピューティング (Azure HDInsight など) は、他のリージョンで実行できます。
[名前] に「ADFTutorialDataFactory」と入力します。
Azure データ ファクトリの名前は、グローバルに一意である必要があります。 次のエラーが発生した場合は、データ ファクトリの名前を変更します ( <yourname>ADFTutorialDataFactory などを使用)。 Data Factory アーティファクトの名前付け規則については、Data Factory の名前付け規則に関する記事を参照してください。
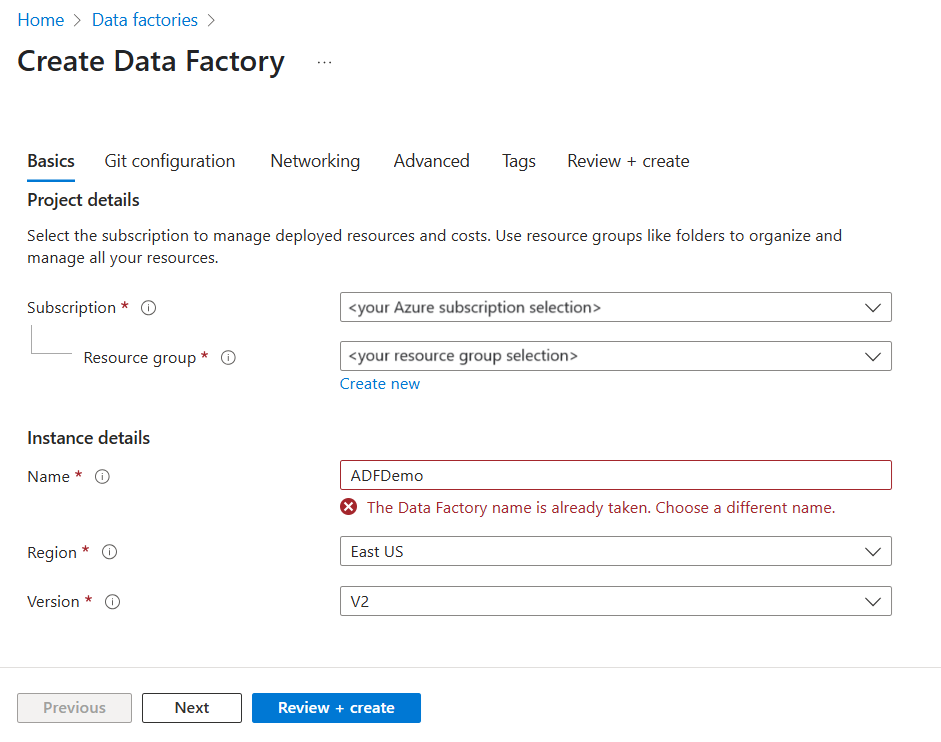
[バージョン] で、 [V2] を選択します。
Next:Git configuration(次へ: Git の構成) を選択し、Configure Git later(後で Git を構成する) チェック ボックスをオンにします。
[確認と作成] を選択し、検証に成功したら [作成] を選択します。
作成後、 [リソースに移動] を選択して、 [Data factory] ページに移動します。 Open Azure Data Factory Studio タイルを選択して、別のブラウザー タブでAzure Data Factoryユーザー インターフェイス (UI) アプリケーションを起動します。
Azure Data Factoryのホーム ページを示すスクリーンショット、[Azure Data Factory Studioを開く] タイルが表示されています。
リンクされたサービスを作成します
このセクションでは、Databricks のリンクされたサービスを作成します。 このリンクされたサービスには、Databricks クラスターへの接続情報が含まれています。
Azure Databricksリンクされたサービスを作成する
ホーム ページの左側のパネルで [管理] タブに切り替えます。
![[管理] タブを示すスクリーンショット。](media/doc-common-process/get-started-page-manage-button.png)
[接続] で [リンク サービス] を選択して、 [+ 新規] を選択します。
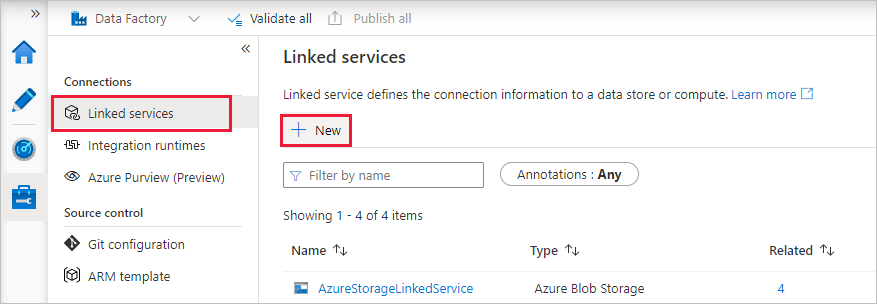
新しいリンクされたサービス ウィンドウで、Compute>Azure Databricks を選択し、Continue を選択します。

[新しいリンク サービス] ウィンドウで、次の手順を完了します。
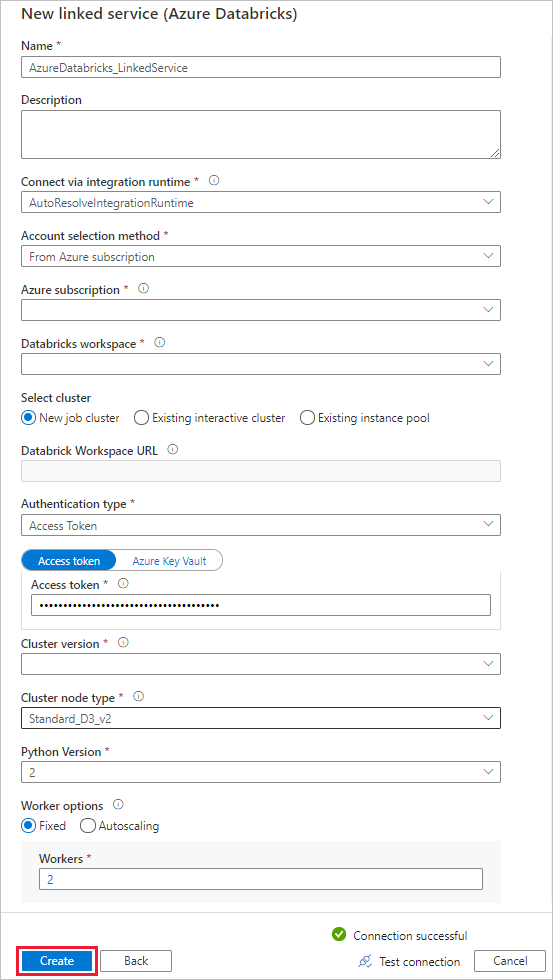
[名前] に AzureDatabricks_LinkedService と入力します。
ノートブックを実行する適切な Databricks ワークスペースを選択します。
[Select cluster]\(クラスターの選択) で [New job cluster]\(新しいジョブ クラスター) を選択します。
[Databricks ワークスペースの URL] では、情報が自動入力されます。
認証の種類で、Access Token を選択した場合は、Azure Databricks ワークスペースから生成してください。 手順については、こちらを参照してください。 管理サービス ID と ユーザー割り当て管理 ID に対して、Azure Databricks リソースのアクセス制御メニューで両方の ID にコントリビューターロールを付与します。
[クラスターのバージョン] で、使用するバージョンを選択します。
このチュートリアルでは、[Cluster node type]\(クラスター ノードの種類) で、[General Purpose (HDD)]\(一般的な目的 (HDD)) カテゴリの [Standard_D3_v2] を選択します。
[ワーカー] に「2」と入力します。
[作成] を選択します
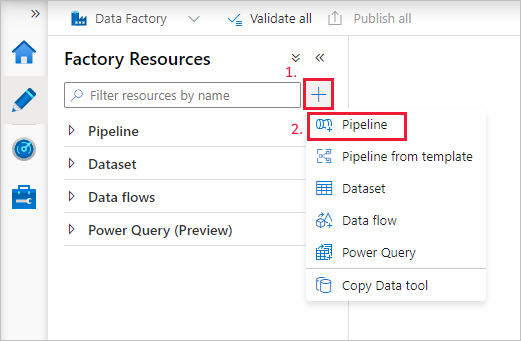
パイプラインを作成する
+ (正符号) ボタンを選択し、メニューの [パイプライン] を選択します。
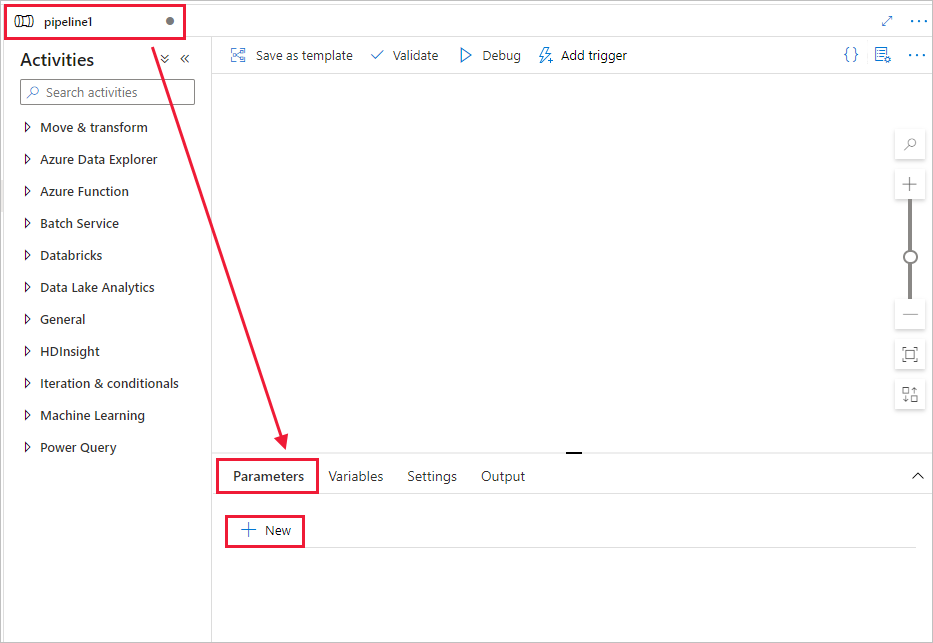
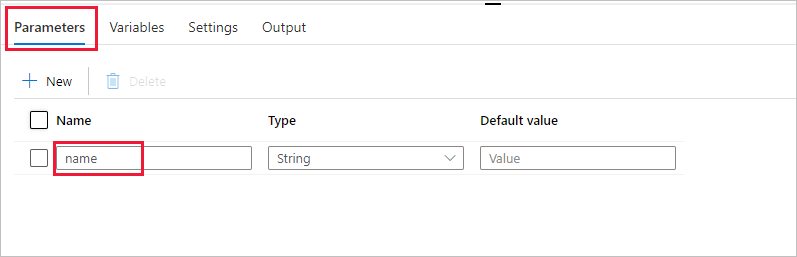
パイプラインで使用されるパラメーターを作成します。 後で、このパラメーターを Databricks Notebook アクティビティに渡します。 空のパイプラインで [パラメーター] タブをクリックし、次に [+ 新規] をクリックして、"name" という名前を付けます。
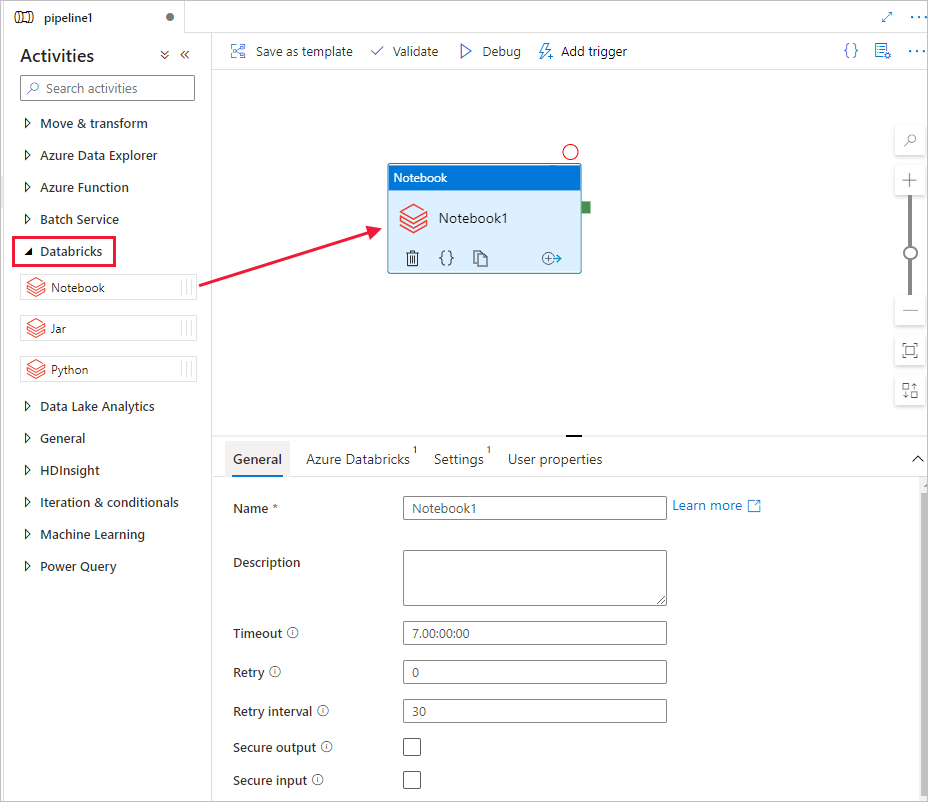
[アクティビティ] ツールボックスで [Databricks] を展開します。 [アクティビティ] ツールボックスからパイプライン デザイナー画面に Notebook アクティビティをドラッグします。
下部の DatabricksNotebook アクティビティ ウィンドウのプロパティで、次の手順を完了します。
Azure Databricks タブに切り替えます。
[AzureDatabricks_LinkedService] (前の手順で作成したもの) を選択します。
[設定] タブに切り替えます。
参照して、Databricks のノートブックのパスを選択します。 ノートブックを作成し、ここでパスを指定しましょう。 次の手順に従って、ノートブックのパスを取得します。
Azure Databricks ワークスペースを起動します。
ワークスペースで新しいフォルダーを作成し、adftutorial という名前にします。
新しいノートブックを作成し、それを mynotebook と呼びます。 [adftutorial] フォルダーを右クリックし、[作成] を選択します。
新しく作成されたノートブック "mynotebook" に次のコードを追加します。
# Creating widgets for leveraging parameters, and printing the parameters dbutils.widgets.text("input", "","") y = dbutils.widgets.get("input") print ("Param -\'input':") print (y)ここでの Notebook パスは、 /adftutorial/mynotebook です。
Data Factory UI 作成ツールに戻ります。 Notebook1 アクティビティの [設定] タブに移動します。
a. Notebook アクティビティにパラメーターを追加します。 前にパイプラインに追加したのと同じパラメーターを使用します。
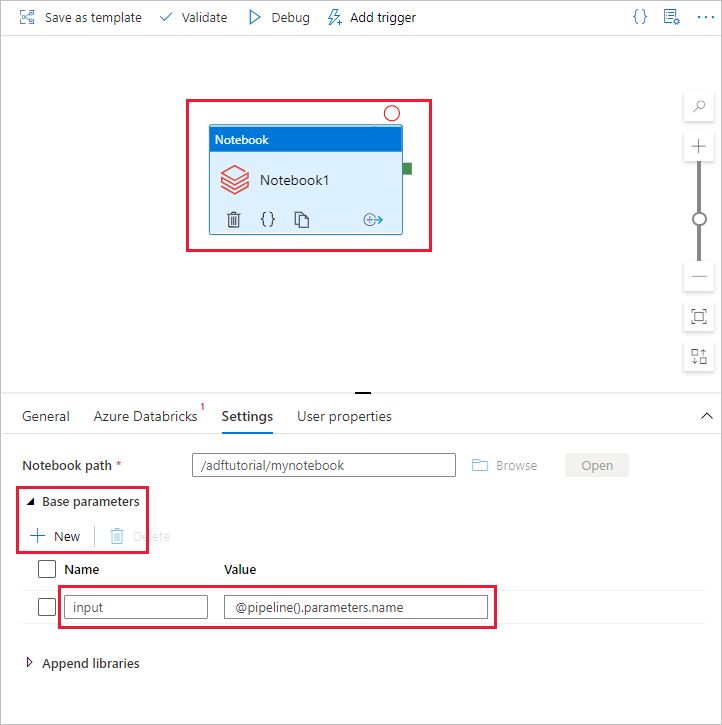
b。 パラメーターの名前を input にして、値を式 @pipeline().parameters.name として指定します。
パイプラインを検証するために、ツール バーの [検証] ボタンを選択します。 検証ウィンドウを閉じるには、 [閉じる] ボタンを選択します。
[すべて公開] を選択します。 Data Factory UI は、エンティティ (リンクされたサービスとパイプライン) をAzure Data Factory サービスに発行します。
パイプラインの実行をトリガーする
ツール バーで [トリガーの追加] を選択し、 [Trigger now](今すぐトリガー) を選択します。
![[Trigger now]\(今すぐトリガー\) コマンドを選択する方法を示すスクリーンショット。](media/transform-data-using-databricks-notebook/databricks-notebook-activity-image-20.png)
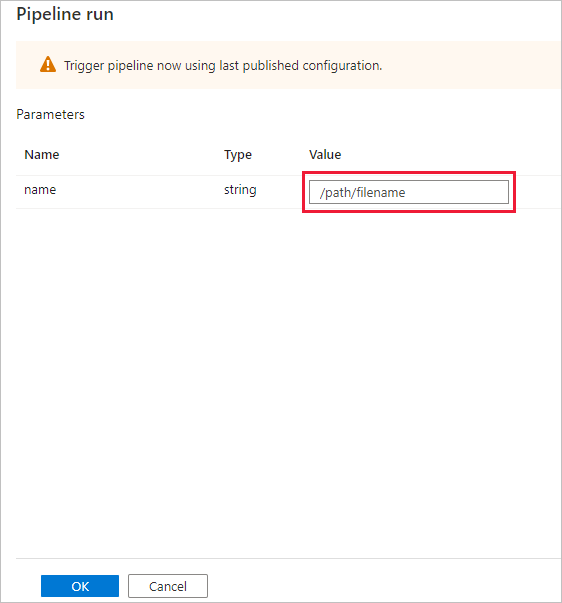
[パイプライン実行] ダイアログ ボックスで、name パラメーターの指定を求められます。 ここでは、パラメーターとして /path/filename を使用します。 [OK] を選択します。
パイプラインの稼働を監視します
[監視] タブに切り替えます。パイプラインが実行されていることを確認します。 ノートブックが実行される Databricks ジョブ クラスターを作成するには、5 分から 8 分ほどかかります。
[最新の情報に更新] を定期的にクリックして、パイプラインの実行の状態を確認します。
パイプラインの実行に関連付けられているアクティビティの実行を表示するには、 [パイプライン名] 列の pipeline1 リンクを選択します。
[アクティビティの実行] ページで、 [アクティビティ名] 列の [出力] を選択して各アクティビティの出力を表示します。さらに詳細な Spark ログについては、 [出力] ウィンドウの Databricks ログへのリンクを参照してください。
上部の階層リンク メニューの [すべてのパイプラインの実行] リンクを選択して、[パイプラインの実行] ビューに戻ることができます。
出力を検証する
Azure Databricks ワークスペースにログオンできます。 Job Runs に移動すると、Job状態が 保留中の実行、実行中、または終了として表示されます。
ジョブ名を選択すると、より詳しい情報が表示されます。 正常に実行されると、渡されたパラメーターと、Python ノートブックの出力を検証できます。
まとめ
このサンプルのパイプラインでは、Databricks Notebook アクティビティをトリガーし、それにパラメーターを渡します。 以下の方法を学習しました。
データ ファクトリを作成します。
Databricks Notebook アクティビティを使用するパイプラインを作成します。
パイプラインの実行をトリガーする。
パイプラインの実行を監視します。