適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
Data Factory in Microsoft Fabric は、よりシンプルなアーキテクチャ、組み込みの AI、および新機能を備えた次世代のAzure Data Factoryです。 データ統合を初めて使用する場合は、Fabric Data Factory から始めます。 既存の ADF ワークロードをFabricにアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
パイプラインの Azure Databricks Notebook アクティビティによって、Azure Databricks ワークスペースで Databricks Notebook が実行されます。 この記事は、データ変換とサポートされる変換アクティビティの概要を説明する、 データ変換アクティビティ に関する記事に基づいています。 Azure Databricksは、Apache Spark を実行するためのマネージド プラットフォームです。
JSON を使用するか、Azure Data Factory Studio ユーザー インターフェイスを使用して、ARM テンプレートを使用して Databricks ノートブックを作成できます。 ユーザー インターフェイスを使用して Databricks ノートブック アクティビティを作成する方法の詳細なチュートリアルについては、チュートリアル「
UI を使用してパイプラインにAzure Databricks用の Notebook アクティビティを追加する
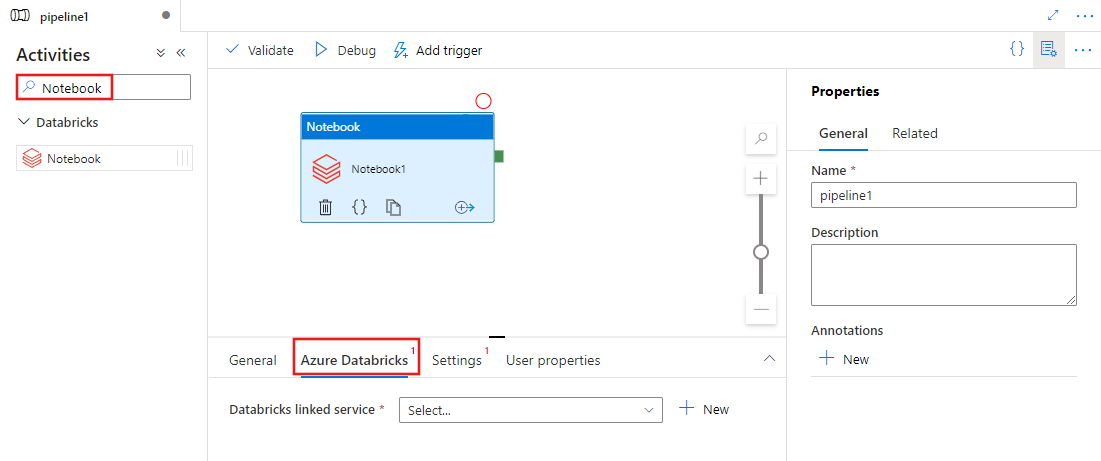
パイプラインのAzure Databricksに Notebook アクティビティを使用するには、次の手順を実行します。
パイプライン アクティビティ ペインで Notebook を検索し、ノートブック アクティビティをパイプライン キャンバスにドラッグします。
まだ選択されていない場合は、キャンバスで新しいノートブック アクティビティを選択します。
Azure Databricks タブを選択して、Notebook アクティビティを実行する新しいAzure Databricksリンクされたサービスを選択または作成します。
Settings タブを選択し、Azure Databricksで実行するノートブック パス、ノートブックに渡す省略可能な基本パラメーター、およびジョブを実行するためにクラスターにインストールするその他のライブラリを指定します。
![Notebook アクティビティの [設定] タブの UI を表示。](media/transform-data-databricks-notebook/notebook-settings.png)
Databricks Notebook アクティビティの定義
Databricks Notebook アクティビティのサンプルの JSON 定義を次に示します。
{
"activity": {
"name": "MyActivity",
"description": "MyActivity description",
"type": "DatabricksNotebook",
"linkedServiceName": {
"referenceName": "MyDatabricksLinkedservice",
"type": "LinkedServiceReference"
},
"typeProperties": {
"notebookPath": "/Users/user@example.com/ScalaExampleNotebook",
"baseParameters": {
"inputpath": "input/folder1/",
"outputpath": "output/"
},
"libraries": [
{
"jar": "dbfs:/docs/library.jar"
}
]
}
}
}
Databricks ノートブックのアクティビティプロパティ
次の表で、JSON 定義で使用される JSON プロパティについて説明します。
| プロパティ | 内容 | 必須 |
|---|---|---|
| 名前 | パイプラインのアクティビティの名前。 | はい |
| 説明 | アクティビティの動作を説明するテキスト。 | いいえ |
| 型 | Databricks Notebook アクティビティでは、アクティビティの種類は DatabricksNotebook です。 | はい |
| linkedServiceName | Databricks ノートブックが実行される Databricks Linked Service の名前です。 このリンクされたサービスの詳細については、計算のリンクされたサービスに関する記事をご覧ください。 | はい |
| ノートブックパス | Databricks ワークスペースで実行するノートブックの絶対パスです。 このパスはスラッシュで始まる必要があります。 | はい |
| baseParameters | キーと値ペアの配列です。 基本パラメーターは、各アクティビティの実行に使うことができます。 指定されていないパラメーターをノートブックが受け取った場合は、ノートブックの既定値が使われます。 パラメーターについて詳しくは、Databricks Notebook に関する記事をご覧ください。 | いいえ |
| ライブラリ | ジョブを実行するクラスターにインストールされるライブラリのリスト。 <文字列, オブジェクト> の配列を指定できます。 | いいえ |
Databricks アクティビティでサポートされるライブラリ
前述の Databricks アクティビティ定義では、jar、egg、whl、maven、pypi、cran というライブラリの種類を指定しています。
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"whl": "dbfs:/mnt/libraries/mlflow-0.0.1.dev0-py2-none-any.whl"
},
{
"whl": "dbfs:/mnt/libraries/wheel-libraries.wheelhouse.zip"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
ライブラリの種類の詳細については、Databricks のドキュメントを参照してください。
ノートブックとパイプラインの間でのパラメーターの受け渡し
Databricks アクティビティの baseParameters プロパティを使用して、パラメーターをノートブックに渡すことができます。
場合によっては、ノートブックからサービスに特定の値を戻す必要があり、サービスの制御フロー (条件チェック) のために使用したり、ダウンストリームのアクティビティで使用したりできます (サイズの上限は 2 MB)。
ノートブックでは、dbutils.notebook.exit("returnValue") を呼び出すことができ、対応する "returnValue" がサービスに返されます。
@{activity('databricks notebook activity name').output.runOutput}などの式を使用して、サービスで出力を使用できます。重要
JSON オブジェクトを渡す場合は、プロパティ名を追加すると値を取得できます。 例:
@{activity('databricks notebook activity name').output.runOutput.PropertyName}
Databricks でライブラリをアップロードする方法
ワークスペース UI を使用できます。
UI を使用して追加されたライブラリの dbfs パスを取得するには、Databricks CLI を使用します。
UI を使用する場合、通常、Jar ライブラリは dbfs:/FileStore/jars に保存されます。 CLI databricks fs ls dbfs:/FileStore/job-jars を使用してすべてを一覧表示することができます
または、Databricks CLI を使用できます。
Databricks CLI を使用します (インストール手順)。
たとえば、JAR を dbfs にコピーする場合:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar