Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
L'origine è la posizione in cui i dati vengono immessi in un flusso di dati o in un grafico del flusso di dati. Configuri la sorgente specificando un riferimento all'endpoint e un elenco di fonti di dati (argomenti) per tale endpoint.
Suggerimento
Una singola origine del flusso di dati può sottoscrivere più argomenti MQTT o Kafka contemporaneamente. Non è necessario creare flussi di dati separati per ogni argomento. Usare il campo dataSources (o Topic(s)>Aggiungi riga nell'esperienza delle operazioni) per aggiungere più filtri topic, inclusi i caratteri jolly. Per altre informazioni, vedere Sottoscrivere più argomenti.
Questa pagina si applica sia ai flussi di dati che ai grafici del flusso di dati. Per i flussi di dati, l'origine è un'operazione nella Dataflow risorsa. Per i grafici del flusso di dati, l'origine è un Source nodo nella DataflowGraph risorsa.
Importante
I flussi di dati supportano gli endpoint di origine MQTT e Kafka. I grafici del flusso di dati supportano endpoint di origine MQTT, Kafka e OpenTelemetry. Ogni flusso di dati deve avere l'endpoint predefinito del broker MQTT locale di Azure IoT Operations come origine o destinazione. Per altre informazioni, vedere Flussi di dati che devono usare l'endpoint broker MQTT locale.
È possibile usare una delle opzioni seguenti come origine.
Usare l'endpoint predefinito
In Dettagli origine selezionare Endpoint del flusso di dati.
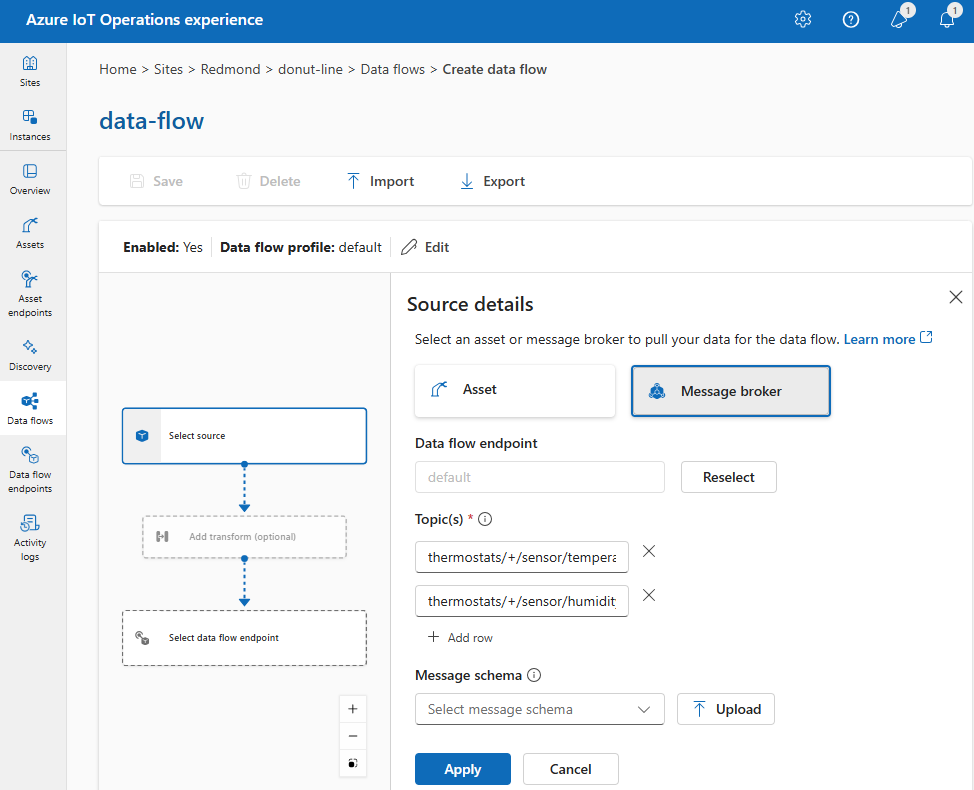
Immettere le impostazioni seguenti per l'origine del broker di messaggi:
Impostazione Descrizione Endpoint del flusso di dati Selezionare l'impostazione predefinita per usare l'endpoint predefinito del broker messaggi MQTT. Argomento Filtro dell'argomento a cui sottoscrivere per i messaggi in arrivo. Usare Argomento/i>Aggiungi riga per aggiungere più argomenti. Per altre informazioni sugli argomenti, vedere Sottoscrivere più argomenti. Schema del messaggio Schema da utilizzare per deserializzare i messaggi in arrivo. Vedere Specificare lo schema per deserializzare i dati. Seleziona Applica.
Poiché dataSources accetta argomenti MQTT o Kafka senza modificare la configurazione dell'endpoint, è possibile riutilizzare l'endpoint per più flussi di dati anche se gli argomenti sono diversi. Per altre informazioni, vedere Sottoscrivere più argomenti.
Usare una risorsa come origine
È possibile usare un asset come origine per il data flow. È possibile usare un asset come origine solo nell'esperienza operativa.
In Dettagli origine, selezionare Asset.
Selezionare l'asset da usare come endpoint di origine.
Selezionare Continua.
Verrà visualizzato un elenco di punti dati per l'asset selezionato.
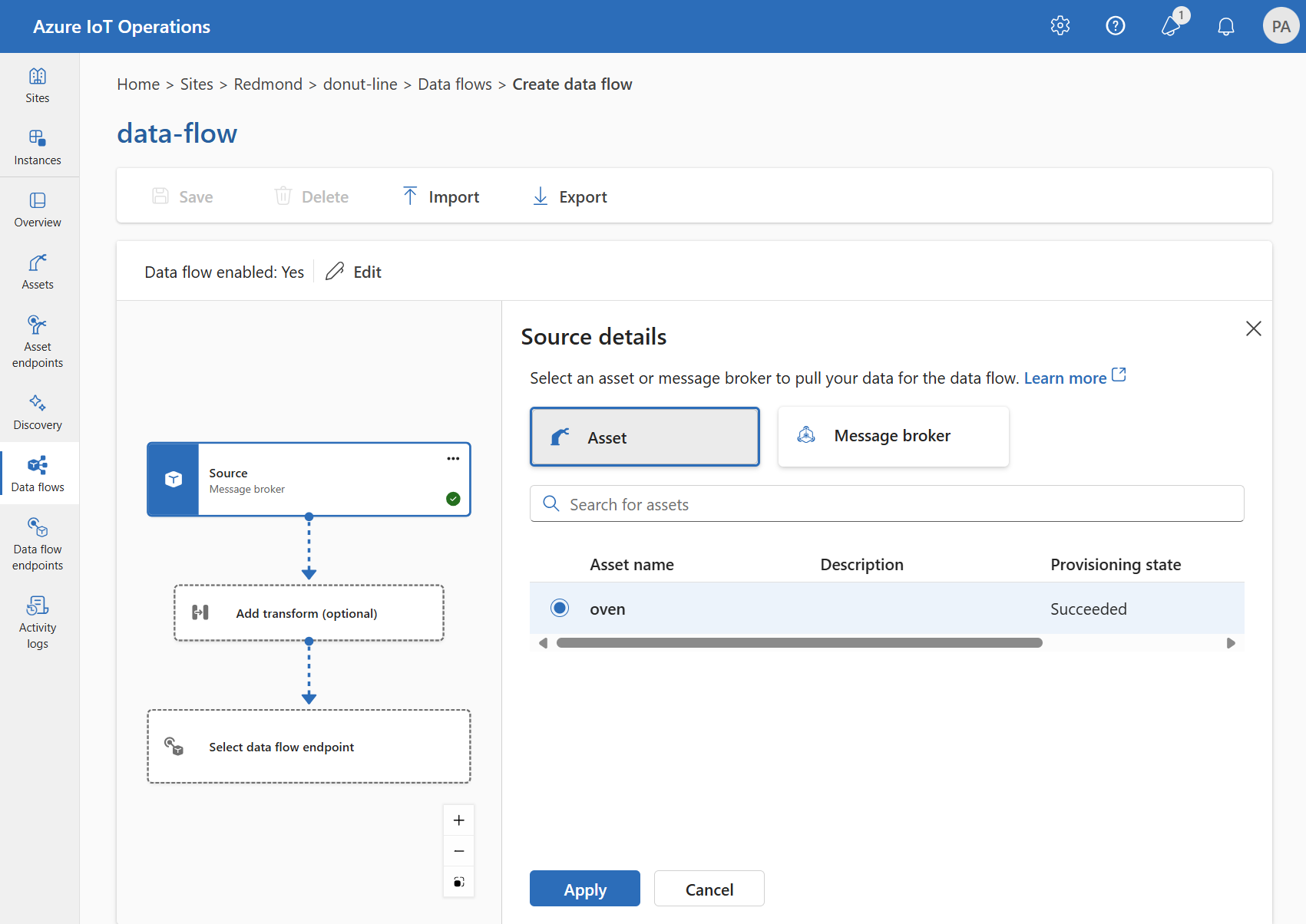
Selezionare Applica per usare l'asset come endpoint di origine.
Quando si usa un asset come origine, la definizione dell'asset fornisce lo schema per il flusso di dati. La definizione dell'asset include lo schema per i punti dati dell'asset. Per altre informazioni, vedere Gestire le configurazioni degli asset in modalità remota.
Dopo aver configurato l'origine, i dati dell'asset raggiungono il flusso di dati tramite il broker MQTT locale. Pertanto, quando si usa un asset come origine, il flusso di dati usa l'endpoint predefinito del broker MQTT locale come origine.
Usare un endpoint MQTT o Kafka personalizzato
Se è stato creato un endpoint di data flow MQTT o Kafka personalizzato (ad esempio, da usare con Griglia di eventi o Hub eventi), è possibile usarlo come origine per il data flow. Tenere presente che gli endpoint dei tipi di archiviazione, ad esempio Data Lake o Fabric OneLake, non possono essere usati come origine.
In Dettagli origine selezionare Endpoint del flusso di dati.
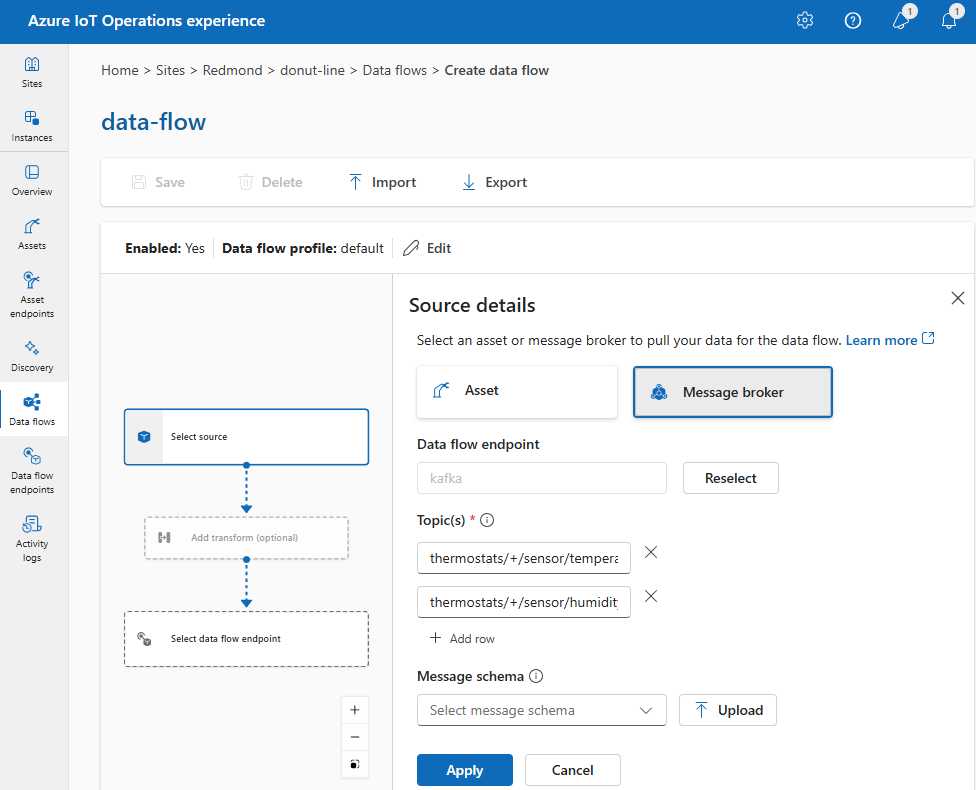
Immettere le impostazioni seguenti per l'origine del broker di messaggi:
Impostazione Descrizione Endpoint del flusso di dati Usare il pulsante Reselect per selezionare un endpoint data flow MQTT o Kafka personalizzato. Per altre informazioni, vedere Configurare gli endpoint data flow MQTT o Configurare Azure Event Hubs e Kafka data flow endpoint. Argomento Filtro dell'argomento a cui sottoscrivere per i messaggi in arrivo. Usare Argomento/i>Aggiungi riga per aggiungere più argomenti. Per altre informazioni sugli argomenti, vedere Sottoscrivere più argomenti. Schema del messaggio Schema da utilizzare per deserializzare i messaggi in arrivo. Vedere Specificare lo schema per deserializzare i dati. Seleziona Applica.
Sottoscrivere più argomenti
È possibile specificare più argomenti MQTT o Kafka in un'origine senza dover modificare la configurazione dell'endpoint data flow. Questa flessibilità significa che è possibile riutilizzare lo stesso endpoint in più flussi di dati, anche se gli argomenti variano. Per altre informazioni, consultare riutilizzare il punto finale del flusso di dati.
Caratteri jolly dell'argomento MQTT
Quando l'origine è un endpoint MQTT (Griglia di eventi inclusa), usare il filtro dell'argomento MQTT per sottoscrivere i messaggi in ingresso. Il filtro dell'argomento può includere caratteri jolly per sottoscrivere a più argomenti. Ad esempio, thermostats/+/sensor/temperature/# sottoscrive tutti i messaggi dei sensori di temperatura dai termostati. Per configurare i filtri degli argomenti MQTT:
Nel flusso di dati dell'esperienza operativa Dettagli origine, selezionare Endpoint del flusso di dati, quindi usare il campo Topic(s) per specificare i filtri del topic MQTT a cui sottoscriversi per i messaggi in arrivo. Per aggiungere più argomenti MQTT, selezionare Aggiungi riga e immettere un nuovo argomento.
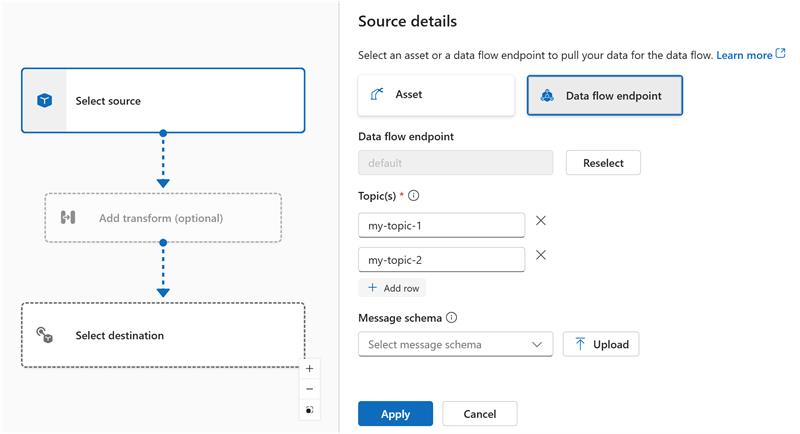
Sottoscrizioni condivise
Per usare sottoscrizioni condivise con le origini del broker messaggi, specificare l'argomento della sottoscrizione condivisa con il formato $shared/<GROUP_NAME>/<TOPIC_FILTER>.
Nel flusso di dati dell'esperienza operativa Dati di origine selezionare Endpoint del flusso di dati e usare il campo Topic per specificare il gruppo e l'argomento della sottoscrizione condivisa.
Se il numero di istanze nel profilo dei flussi di dati è maggiore di uno, la sottoscrizione condivisa viene abilitata automaticamente per tutti i flussi di dati che utilizzano un'origine broker di messaggi. In questo caso, viene aggiunto il prefisso $shared e il nome del gruppo di sottoscrizioni condiviso viene generato automaticamente. Ad esempio, se si dispone di un profilo di data flow con un numero di istanze pari a 3 e il data flow usa un endpoint del broker di messaggi come origine configurato con argomenti topic1 e topic2, vengono convertiti automaticamente in sottoscrizioni condivise come $shared/<GENERATED_GROUP_NAME>/topic1 e $shared/<GENERATED_GROUP_NAME>/topic2.
È possibile creare in modo esplicito un argomento denominato $shared/mygroup/topic nella configurazione. Tuttavia, l'aggiunta esplicita dell'argomento $shared non è consigliata perché il $shared prefisso viene aggiunto automaticamente quando necessario. I flussi di dati possono eseguire ottimizzazioni con il nome del gruppo, se non impostato. Ad esempio, se $shared non è impostato, i flussi di dati devono operare solo sul nome dell'argomento.
Importante
Le sottoscrizioni condivise sono importanti per i flussi di dati quando il numero di istanze è maggiore di uno e si usa il broker MQTT di Griglia di eventi come origine, perché non supporta le sottoscrizioni condivise. Per evitare messaggi persi, impostare il numero di istanze del profilo di flusso di dati su uno quando si utilizza il broker MQTT di Event Grid come origine. Ovvero quando il flusso di dati è il sottoscrittore e riceve i messaggi dal cloud.
Argomenti di Kafka
Quando l'origine è un endpoint Kafka (Hub eventi incluso), specificare i singoli argomenti Kafka a cui sottoscrivere per i messaggi in arrivo. I caratteri jolly non sono supportati, pertanto è necessario specificare ogni argomento in modo statico.
Annotazioni
Quando si usano Hub eventi tramite l'endpoint Kafka, ogni singolo hub eventi all'interno dello spazio dei nomi è l'argomento Kafka. Ad esempio, se si dispone di uno spazio dei nomi di Hub eventi con due hub eventi thermostats e humidifiers, è possibile specificare ogni hub eventi come argomento Kafka.
Per configurare gli argomenti Kafka:
Nel flusso di dati dell'esperienza operativa Dettagli origine, selezionare Endpoint del flusso di dati, quindi usare il campo Topic(s) per specificare il filtro del topic Kafka a cui sottoscriversi per i messaggi in arrivo.
Annotazioni
È possibile specificare un solo filtro argomento nell'esperienza operativa. Per usare più filtri di argomento, usare Bicep o Kubernetes.
Usare l'argomento di origine nel percorso di destinazione
Quando ci esegue la sottoscrizione a più argomenti con caratteri jolly, è possibile usare l'argomento di origine come variabile nel percorso di destinazione. Questa funzionalità funziona sia con i flussi di dati che con i grafici del flusso di dati.
Usare ${inputTopic} per l'argomento di origine completo o ${inputTopic.N} per estrarre un segmento specifico (indicizzato da 1). Ad esempio, se si sottoscrive a factory/+/telemetry/#, è possibile instradare un messaggio in arrivo su factory/line1/telemetry/temp a un tema di destinazione come processed/${inputTopic.2}/data, che si risolve in processed/line1/data.
Per informazioni dettagliate ed esempi, vedere Argomenti sulla destinazione dinamica.
Specificare lo schema di origine
Quando si usa MQTT o Kafka come origine, è possibile specificare uno schema per visualizzare l'elenco dei punti dati nell'interfaccia utente Web dell'esperienza operativa. L'uso di uno schema per deserializzare e convalidare i messaggi in ingresso non è attualmente supportato.
Se l'origine è un asset, il portale deduce automaticamente lo schema dalla definizione dell'asset.
Suggerimento
Per generare lo schema da un file di dati di esempio, usare l'helper di Schema Gen.
Per configurare lo schema usato per deserializzare i messaggi in ingresso da un'origine:
Nel flusso di dati dell'esperienza operativa Dettagli origine, selezionare Endpoint del flusso di dati e usare il campo Schema messaggio per specificare lo schema. Selezionare Carica per caricare un file di schema. Per altre informazioni, vedere Informazioni sugli schemi dei messaggi.
Per altre informazioni, vedere Informazioni sugli schemi dei messaggi.