Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Un hub de tâches est une représentation de l’état actuel de l’application dans le stockage, y compris tout le travail en attente. Pendant qu’une application s’exécute, le hub de tâches stocke continuellement la progression de l’orchestration, de l’activité et des fonctions d’entité. Cette approche garantit que l’application peut reprendre le traitement là où elle s’est arrêtée si elle redémarre après avoir été temporairement arrêtée ou interrompue. Un hub de tâches permet également aux applications de faire évoluer dynamiquement les travailleurs informatiques.
Cet article explique ce qu’un hub de tâches stocke, comment configurer et nommer des hubs de tâches, comment les créer et les gérer avec différents back-ends de stockage et comment fonctionnent en interne les hubs de tâches.
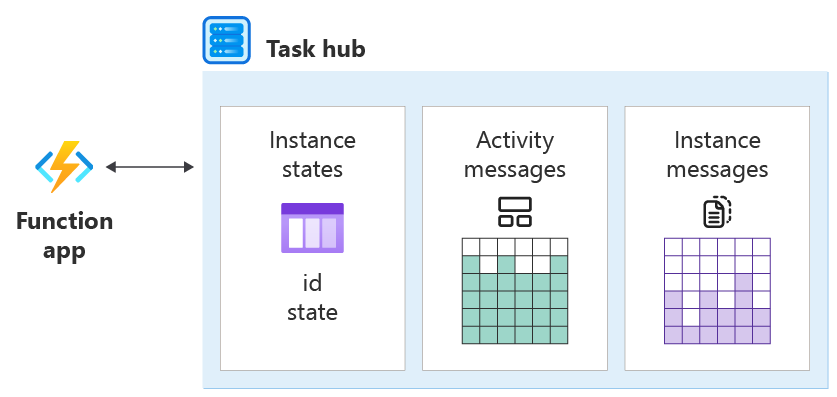
Conceptuellement, un hub de tâches stocke les informations suivantes :
- Les états d’instance de toutes les instances d’orchestration et d’entité.
- Messages à traiter, notamment :
- Tous les messages d’activité qui représentent les activités en attente d’exécution.
- Tous les messages d’instance qui attendent d’être remis aux instances.
Les messages d’activité sont sans état et peuvent être traités n’importe où. Les messages d’instance doivent être remis à une instance avec état particulier (orchestration ou entité), identifiée par son ID d’instance.
En interne, chaque fournisseur de stockage peut utiliser une organisation différente pour représenter les états d’instance et les messages. Par exemple, le fournisseur Azure Storage stocke les messages dans les files d’attente Azure Storage, mais le fournisseur MSSQL les stocke dans des tables relationnelles. Ces différences n’ont pas d’importance pour la conception d’applications, mais certaines d’entre elles peuvent influencer les caractéristiques de performances. Pour plus d’informations, consultez Représentation dans le stockage.
Les SDKs de tâches durables utilisent le planificateur de tâches durables comme back-end pour les hubs de tâches. Le planificateur de tâches durables est un service entièrement géré qui gère le stockage en interne.
Noms du hub de tâches
Les hubs de tâches sont identifiés par un nom conforme aux règles suivantes :
- Contient uniquement des caractères alphanumériques
- Commence par une lettre
- A une longueur minimale de 3 caractères, longueur maximale de 45 caractères
Déclarez le nom du hub de tâches dans le fichier host.json , comme indiqué dans l’exemple suivant :
host.json (Functions 2.0)
{
"version": "2.0",
"extensions": {
"durableTask": {
"hubName": "MyTaskHub"
}
}
}
host.json (Functions 1.x)
{
"durableTask": {
"hubName": "MyTaskHub"
}
}
Vous pouvez également configurer des hubs de tâches à l’aide des paramètres d’application, comme indiqué dans l’exemple de fichier suivant host.json :
host.json (Functions 2.0)
{
"version": "2.0",
"extensions": {
"durableTask": {
"hubName": "%MyTaskHub%"
}
}
}
host.json (Functions 1.x)
{
"durableTask": {
"hubName": "%MyTaskHub%"
}
}
Le nom du hub de tâches est défini sur la valeur du paramètre d’application MyTaskHub . Le fichier suivant local.settings.json montre comment définir le paramètre MyTaskHub en samplehubname :
{
"IsEncrypted": false,
"Values": {
"MyTaskHub" : "samplehubname"
}
}
Note
Lorsque vous utilisez des emplacements de déploiement, il est recommandé de configurer le nom du hub de tâches à l’aide des paramètres d’application. Si vous souhaitez vous assurer qu’un emplacement particulier utilise toujours un hub de tâches particulier, utilisez les paramètres d’application « slot-sticky ».
Outre host.json, les noms de hub de tâches peuvent également être configurés dans les métadonnées de liaison du client d’orchestration. Cette configuration est utile lorsque vous devez accéder aux orchestrations ou entités qui vivent dans une application de fonction distincte. Le code suivant montre comment écrire une fonction qui utilise la liaison cliente d’orchestration pour travailler avec un hub de tâches configuré en tant que paramètre d’application :
[FunctionName("HttpStart")]
public static async Task<HttpResponseMessage> Run(
[HttpTrigger(AuthorizationLevel.Function, methods: "post", Route = "orchestrators/{functionName}")] HttpRequestMessage req,
[DurableClient(TaskHub = "%MyTaskHub%")] IDurableOrchestrationClient starter,
string functionName,
ILogger log)
{
// Function input comes from the request content.
object eventData = await req.Content.ReadAsAsync<object>();
string instanceId = await starter.StartNewAsync(functionName, eventData);
log.LogInformation($"Started orchestration with ID = '{instanceId}'.");
return starter.CreateCheckStatusResponse(req, instanceId);
}
Note
L’exemple précédent concerne Durable Functions 2.x. Pour Durable Functions 1.x, utilisez DurableOrchestrationContext au lieu de IDurableOrchestrationContext. Pour plus d’informations sur les différences entre les versions, consultez l’article Durable Functions versions.
Note
La configuration des noms de hub de tâches dans les métadonnées de liaison de client n’est nécessaire que lorsque vous utilisez une application de fonction pour accéder aux orchestrations et entités d’une autre application de fonction. Si les fonctions clientes sont définies dans la même application de fonction que les orchestrations et les entités, évitez de spécifier les noms du hub de tâches dans les métadonnées de liaison. Par défaut, toutes les liaisons clientes obtiennent leurs métadonnées de hub de tâches à partir des paramètres host.json .
S’il n’est pas spécifié, un nom de hub de tâches par défaut est utilisé comme indiqué dans le tableau suivant :
| Version d’extension durable | Nom du hub de tâches par défaut |
|---|---|
| 2.x | Lors du déploiement dans Azure, le nom du hub de tâches est dérivé du nom de l’application function. Lors de l’exécution en dehors de Azure, le nom du hub de tâches par défaut est TestHubName. |
| 1.x | Le nom du hub de tâches par défaut pour tous les environnements est DurableFunctionsHub. |
Pour plus d’informations sur les différences entre les versions d’extension, consultez l’article Durable Functions versions.
Utiliser plusieurs applications avec des hubs de tâches distincts
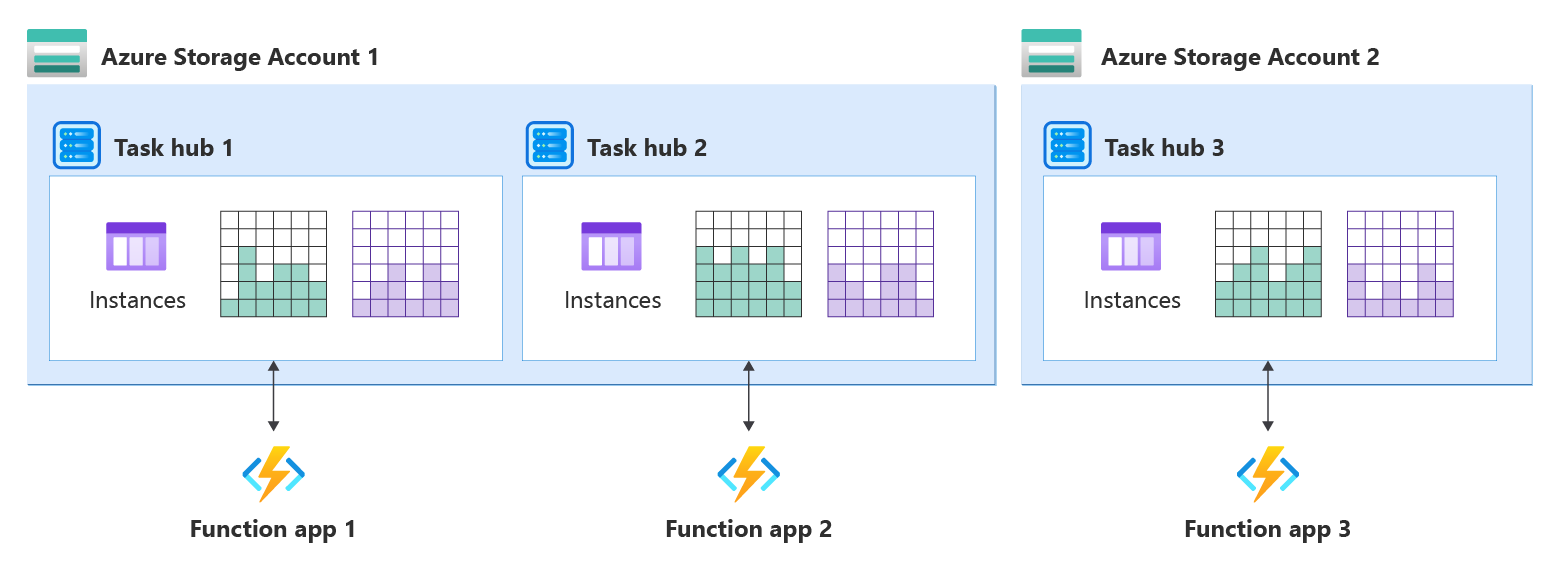
Chaque application qui partage un back-end doit se connecter à son propre hub de tâches pour éviter les conflits. Si plusieurs applications utilisent le même hub de tâches, elles se concurrencent pour les messages, ce qui peut entraîner un comportement non défini, y compris des orchestrations bloquées de manière inattendue. Un serveur principal unique peut contenir plusieurs hubs de tâches ; configurez chaque application avec sa propre application.
Cette exigence s’applique à tous les back-ends de stockage. Pour les fournisseurs de stockage BYO (Stockage Azure, Netherite, MSSQL), configurez chaque application de fonction avec un nom distinct du hub de tâches. Cette exigence s’applique également aux emplacements intermédiaires : configurez chaque emplacement intermédiaire avec un nom de hub de tâches unique.
Important
Par défaut, le nom de l’application est utilisé comme nom du hub de tâches, ce qui garantit que le partage accidentel ne se produit pas. Si vous configurez explicitement les noms du hub de tâches dans host.json, vérifiez que les noms sont uniques. La seule exception est si vous déployez des copies de la même application dans plusieurs régions pour la récupération d’urgence. Dans ce cas, utilisez le même hub de tâches pour les copies.
Le diagramme suivant illustre un hub de tâches par application de fonction dans des comptes de Azure Storage partagés et dédiés.
Gestion durable du hub de tâches du planificateur de tâches
Cette section explique comment créer et gérer des hubs de tâches lors de l’utilisation du serveur principal du planificateur de tâches durable. Créez explicitement les ressources du planificateur et du hub de tâches avant que votre application ne les utilise.
Créer un planificateur et un hub de tâches
Créez un planificateur et un hub de tâches à l’aide du portail Azure, Azure CLI, Azure Resource Manager (ARM) ou Bicep.
Dans le portail Azure, recherchez Durable Task Scheduler et sélectionnez-le dans les résultats.
Sélectionnez Créer pour ouvrir le volet de création du planificateur.
Renseignez les champs sous l’onglet Informations de base , y compris le groupe de ressources, le nom du planificateur, la région et la référence SKU. Sélectionnez Vérifier + créer.
Une fois la validation réussie, sélectionnez Créer. Le déploiement prend jusqu’à 15 minutes.
Une fois le planificateur créé, accédez à la ressource du planificateur. Dans la page Vue d’ensemble , créez un hub de tâches.
Important
La 0.0.0.0/0 liste d’autorisations IP autorise l’accès à partir de n’importe quelle adresse IP. Pour les déploiements de production, limitez-le uniquement aux plages d’adresses IP requises.
Les exemples précédents utilisent la référence SKU dédiée. Le planificateur de tâches durables propose également une référence de consommation. Pour plus d’informations sur la gestion des ressources du Planificateur de Tâches Durables, consultez Développer avec le Planificateur de Tâches Durables.
Configurer l’authentification basée sur l’identité
Durable Task Scheduler prend uniquement en charge l’authentification d’identité managée. Il ne prend pas en charge les chaînes de connexion avec des clés de stockage. Attribuez le rôle de contrôle d’accès en fonction du rôle (RBAC) approprié à une identité managée et configurez votre application pour utiliser cette identité.
Les rôles suivants sont disponibles :
| Rôle | Description |
|---|---|
| Contributeur de données pour les tâches durables | Accès complet aux données. Ensemble supérieur de tous les autres rôles. |
| Travail de tâche durable | Interagissez avec le planificateur pour le traitement des orchestrations, des activités et des entités. |
| Lecteur de données pour les tâches durables | Accès en lecture seule aux données d’orchestration et d’entité. |
Note
La plupart des applications nécessitent le rôle Contributeur aux données des tâches durables.
Utilisez les identités managées affectées par l’utilisateur si possible, car elles ne sont pas liées au cycle de vie de l’application et vous pouvez les réutiliser une fois l’application supprimée.
Accédez à la ressource du planificateur ou du hub de tâches dans le portail Azure.
Sélectionnez Contrôle d’accès (IAM) à partir du menu de gauche.
Sélectionnez Ajouter>Ajouter une attribution de rôle.
Recherchez et sélectionnez Contributeur de données de tâche durable. Cliquez sur Suivant.
Pour Attribuer l’accès à, sélectionnez Identité managée. Sélectionnez + Sélectionner des membres.
Sélectionnez Identité managée affectée par l’utilisateur, choisissez l’identité, puis sélectionnez Sélectionner.
Sélectionnez Vérifier + affecter pour terminer.
Accédez à votre application de fonction, puis sélectionnez Paramètres>Identité. Sélectionnez l’onglet Utilisateur affecté , puis ajoutez l’identité.
Après avoir affecté l’identité, ajoutez les variables d’environnement suivantes à votre application :
| Variable | Valeur |
|---|---|
TASKHUB_NAME |
Nom de votre hub de tâches. |
DURABLE_TASK_SCHEDULER_CONNECTION_STRING |
Endpoint={scheduler endpoint};Authentication=ManagedIdentity;ClientID={client id} |
Note
Si vous utilisez une identité managée affectée par le système, omettez le segment ClientID du connection string : Endpoint={scheduler endpoint};Authentication=ManagedIdentity.
Pour des détails complets sur la configuration de l’identité, consultez Configurer l’identité managée pour Durable Task Scheduler.
Gestion du hub de tâches du fournisseur de stockage BYO
Cette section traite de la création et de la suppression du hub de tâches et de l’inspection du contenu du hub de tâches. Il s’applique aux fournisseurs de stockage BYO (bring-your-own) : Azure Storage, Netherite et MSSQL.
Créer et supprimer des hubs de tâches
Un hub de tâches vide avec toutes les ressources requises est automatiquement créé dans le stockage lorsqu’une application de fonction démarre pour la première fois.
Si vous utilisez le fournisseur Azure Storage, aucune configuration supplémentaire n’est requise. Sinon, suivez les instructions de configuration des fournisseurs de stockage pour vous assurer que le fournisseur de stockage peut configurer et accéder correctement aux ressources de stockage requises pour le hub de tâches.
Note
Le hub de tâches n’est pas automatiquement supprimé lorsque vous arrêtez ou supprimez l’application de fonction. Pour supprimer ces données, supprimez manuellement le hub de tâches, son contenu ou le compte de stockage contenant.
Conseil / Astuce
Dans un scénario de développement, vous devrez peut-être redémarrer à partir d’un état propre souvent. Pour ce faire rapidement, modifiez simplement le nom du hub de tâches configuré. Cette modification force la création d’un hub de tâches vide lorsque vous redémarrez l’application. Les anciennes données ne sont pas supprimées dans ce cas.
Inspecter le contenu du hub de tâches
Il existe plusieurs façons courantes d’inspecter le contenu d’un hub de tâches :
- Dans une application de fonction, l’objet client fournit des méthodes pour interroger le magasin d’instances. Pour en savoir plus sur les types de requêtes pris en charge, consultez l’article Gestion des instances .
- De même, l’API HTTP propose des requêtes REST pour interroger l’état des orchestrations et des entités. Pour plus d’informations, consultez la référence de l’API HTTP .
- L’outil Durable Functions Monitor peut inspecter les hubs de tâches et offre différentes options pour l’affichage visuel.
Pour certains fournisseurs de stockage, vous pouvez également inspecter le hub de tâches en accédant directement au stockage sous-jacent :
- Si vous utilisez le fournisseur Azure Storage, les états d’instance sont stockés dans la table Instance Table et la table History Table, que vous pouvez inspecter à l’aide d’outils comme Azure Storage Explorer.
- Si vous utilisez le fournisseur de stockage MSSQL, utilisez des requêtes et des outils SQL pour inspecter le contenu du hub de tâches dans la base de données.
Éléments de travail
Les messages d’activité et les messages d’instance dans le hub de tâches représentent le travail que l’application doit traiter. Pendant que l’application est en cours d’exécution, elle extrait en continu des éléments de travail à partir du hub de tâches. Chaque élément de travail traite un ou plusieurs messages. Il existe deux types d’éléments de travail :
- Éléments de travail liés à l'activité : exécutez une fonction d'activité pour traiter un message relatif à l'activité.
- Éléments de travail Orchestrator : exécutez une fonction d’orchestrateur ou d’entité pour traiter un ou plusieurs messages d’instance.
Les travailleurs peuvent traiter plusieurs éléments de travail en même temps, sous réserve des limites de concurrence configurées par travailleur.
Pour plus d’informations sur les contrôles de concurrence, consultez Performance et mise à l’échelle.
Une fois qu’un worker a terminé un élément de travail, il valide les effets dans le hub de tâches. Ces effets varient selon le type de fonction exécuté :
- Une fonction d’activité terminée crée un message d’instance contenant le résultat, adressé à l’instance d’orchestrateur parent.
- Une fonction d’orchestrateur terminée met à jour l’état et l’historique de l’orchestration, et peut créer de nouveaux messages.
- Une fonction d’entité terminée met à jour l’état de l’entité et peut également créer des messages d’instance.
Pour les orchestrations, chaque élément de travail représente un épisode de l’exécution de cette orchestration. Un épisode correspond à un cycle complet de l'orchestrateur, traitant les résultats disponibles, puis s'interrompant jusqu'à l'arrivée du prochain résultat. Par exemple, un épisode démarre lorsque l’orchestration commence, lorsqu’une activité se termine et retourne un résultat, ou lorsqu’un événement externe arrive. L'épisode se termine lorsque l'orchestrateur achève ses opérations ou atteint un point où il doit attendre de nouveaux messages.
Exemple d’exécution
Considérez une orchestration Fan-out-Fan-in qui démarre deux activités en parallèle et attend que les deux se terminent :
[FunctionName("Example")]
public static async Task Run([OrchestrationTrigger] IDurableOrchestrationContext context)
{
Task t1 = context.CallActivityAsync<int>("MyActivity", 1);
Task t2 = context.CallActivityAsync<int>("MyActivity", 2);
await Task.WhenAll(t1, t2);
}
using Microsoft.DurableTask;
public class Example : TaskOrchestrator<object?, object?>
{
public override async Task<object?> RunAsync(TaskOrchestrationContext context, object? input)
{
Task t1 = context.CallActivityAsync("MyActivity", 1);
Task t2 = context.CallActivityAsync("MyActivity", 2);
await Task.WhenAll(t1, t2);
return null;
}
}
Une fois cette orchestration lancée par un client, l’application la traite comme une séquence d’éléments de travail. Chaque élément de travail terminé met à jour l’état du hub de tâches lors de sa validation. Ces étapes sont les suivantes :
Un client demande de démarrer une nouvelle orchestration avec l’ID d’instance « 123 ». Une fois que le client a terminé cette requête, le hub de tâches contient un espace réservé pour l’état d’orchestration et un message d’instance :

L'étiquette
ExecutionStartedest l'un des nombreux types d'événements history qui identifient les différents types de messages et d'événements participant à l'historique d'une orchestration.Un opérateur exécute un élément de travail d’orchestrateur pour traiter le
ExecutionStartedmessage. Il appelle la fonction d’orchestrateur qui commence à exécuter le code d’orchestration. Ce code planifie deux activités, puis cesse de s’exécuter lorsqu’il attend les résultats.
L’état d’exécution est maintenant
Running, et l’historique enregistre ce premier épisode : l’orchestrateur a démarré, l’exécution démarrée, deux tâches ont été planifiées et l’orchestrateur a terminé l’épisode.Un opérateur exécute un élément de travail lié à une activité pour traiter l'un des
TaskScheduledmessages. Elle appelle la fonction d’activité avec l’entrée « 2 ». Une fois la fonction d’activité terminée, elle crée unTaskCompletedmessage contenant le résultat.
Un opérateur exécute un élément de travail d’orchestrateur pour traiter le
TaskCompletedmessage. Si l’orchestration est toujours mise en cache en mémoire, elle peut simplement reprendre l’exécution. Sinon, le worker relit d’abord l’historique pour récupérer l’état actuel de l’orchestration. Ensuite, il poursuit l’orchestration, fournissant le résultat de l’activité. Après avoir reçu ce résultat, l'orchestration attend toujours le résultat de l'autre activité, elle s'arrête donc à nouveau.
L’historique enregistre le deuxième épisode : la tâche s’est terminée et l’orchestrateur a suspendu à nouveau.
Un worker exécute un élément de travail d’activité pour traiter le message
TaskScheduledrestant. Il appelle la fonction d’activité avec l’entrée « 1 ».
Un travailleur exécute un autre élément de travail d’orchestrateur pour traiter le
TaskCompletedmessage. Après avoir reçu ce deuxième résultat, l’orchestration se termine.
L’état d’exécution est maintenant
Completed, et l’historique enregistre le troisième et dernier épisode : la deuxième tâche est terminée et l’exécution terminée.
Note
La planification affichée n’est pas la seule possible. Par exemple, si la deuxième activité se termine précédemment, les deux TaskCompleted messages peuvent être traités par un seul élément de travail, ce qui entraîne seulement deux épisodes au lieu de trois.
Représentation dans le stockage
Chaque fournisseur de stockage utilise une organisation interne différente pour représenter les hubs de tâches dans le stockage. Comprendre cette organisation, bien qu’elle n’est pas nécessaire, peut vous aider lors de la résolution des problèmes ou de la tentative de performances, d’extensibilité ou de cibles de coût.
Les kits SDK Durable Task utilisent le planificateur de tâches durables comme back-end, qui gère l’état du hub de tâches en interne.
Fournisseur planificateur de tâches durables
Le Durable Task Scheduler est un fournisseur backend entièrement géré qui stocke l’état de tous les hubs de tâches en interne. Contrairement aux fournisseurs de stockage BYO (bring-your-own), vous n’avez pas besoin de configurer ou de gérer une infrastructure de stockage sous-jacente. Chaque ressource du planificateur (Microsoft.DurableTask/schedulers) possède des ressources de calcul et de mémoire dédiées, et peut contenir un ou plusieurs hubs de tâches (Microsoft.DurableTask/schedulers/taskHubs).
Étant donné que durable Task Scheduler gère le stockage en interne, vous ne pouvez pas inspecter directement les données sous-jacentes. Utilisez plutôt le tableau de bord Du planificateur de tâches durables pour surveiller et interroger des instances d’orchestration.
Pour plus d’informations sur les options du fournisseur de stockage BYO et leur comparaison, consultez les fournisseurs de stockage Durable Functions.
fournisseur de stockage Azure
Le fournisseur Azure Storage représente le hub de tâches dans le stockage à l’aide des composants suivants :
- Deux tables Azure stockent les états d’instance.
- Une file d’attente Azure stocke les messages d’activité.
- Une ou plusieurs files d’attente Azure stockent les messages d’instance. Chacune de ces dénommées files d’attente de contrôle représente une partition affectée à un sous-ensemble de tous les messages d’instance, en fonction du hachage de l’ID d’instance.
- Quelques conteneurs de blob supplémentaires utilisés pour les blobs de bail ou les messages volumineux.
Par exemple, un hub de tâches nommé xyz avec PartitionCount = 4 contient les files d’attente et les tables suivantes :

Les sections suivantes décrivent ces composants et leurs rôles plus en détail.
Pour plus d’informations sur la façon dont les hubs de tâches sont représentés par le fournisseur Azure Storage, consultez la documentation Azure Storage fournisseur.
Fournisseur de stockage Netherite (chemin de mise hors service)
Netherite partitionne tous les états du hub de tâches en un nombre spécifié de partitions. Dans le stockage, ces ressources stockent les données :
- Un conteneur d’objets blob Azure Storage qui contient tous les objets blob, regroupés par partition.
- Une table Azure qui contient des métriques publiées sur les partitions.
- Espace de noms Azure Event Hubs pour la remise de messages entre les partitions.
Par exemple, un hub de tâches nommé mytaskhub avec PartitionCount = 32 est représenté dans le stockage comme suit :

Note
L'état du hub de tâches est stocké dans le conteneur de blobs x-storage. La DurableTaskPartitions table et l’espace de noms Event Hubs contiennent des données redondantes : si leur contenu est perdu, ils peuvent être récupérés automatiquement. Par conséquent, vous n'avez pas besoin de configurer l'espace de noms Azure Event Hubs pour conserver les messages au-delà de l'heure d'expiration par défaut.
Netherite utilise un mécanisme d’approvisionnement en événements, basé sur un journal et des points de contrôle, pour représenter l’état actuel d’une partition. Les blobs de blocs et les blobs de pages stockent les données. Vous ne pouvez pas lire ce format directement à partir du stockage. L’application de fonction doit donc être en cours d’exécution lorsque vous interrogez le magasin d’instances.
Pour plus d’informations sur les hubs de tâches pour le fournisseur de stockage Netherite, consultez les informations du hub de tâches pour le fournisseur de stockage Netherite.
Fournisseur de stockage MSSQL
Toutes les données du hub de tâches sont stockées dans une base de données relationnelle unique, à l’aide de ces tables :
- Les tables
dt.Instancesetdt.Historystockent les états d’instance. - La
dt.NewEventstable stocke les messages d’instance. - La
dt.NewTaskstable stocke les messages d’activité.

Pour permettre à plusieurs hubs de tâches de coexister indépendamment dans la même base de données, chaque table inclut une TaskHub colonne dans le cadre de sa clé primaire. Contrairement aux deux autres fournisseurs, le fournisseur MSSQL n’a pas de partitions.
Pour plus d’informations sur les hubs de tâches pour le fournisseur de stockage MSSQL, consultez les informations du hub de tâches pour le fournisseur de stockage Microsoft SQL (MSSQL).