Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article vous aide à résoudre les scénarios courants dans les applications Durable Functions. Recherchez votre symptôme dans la liste suivante et suivez les étapes liées pour diagnostiquer et résoudre le problème.
Symptômes courants
- L’orchestration est bloquée dans l’état d'attente
- Les orchestrations démarrent après un long délai
- L’orchestration est coincée dans l’état d’exécution
- L’orchestration prend plus de temps que prévu pour se terminer
- Erreurs de connexion sur le plan Consommation
Pour les requêtes de diagnostic KQL que vous pouvez exécuter dans Application Insights, consultez Exemples de requêtes KQL pour les diagnostics de Durable Functions.
L’orchestration est bloquée dans l’état Pending
Lorsque vous démarrez une orchestration, un message « start » est écrit dans une file d’attente interne gérée par l’extension Durable, et l’état de l’orchestration est défini sur « En attente ». Une fois qu’une instance d’application disponible récupère et traite correctement le message d’orchestration, l’état passe à « En cours d’exécution » (ou à un autre état non en attente).
Suivez ces étapes pour résoudre les problèmes liés aux instances d’orchestration qui restent bloquées indéfiniment dans l’état « En attente ».
Vérifiez les traces de Durable Task Framework à la recherche d’avertissements ou d’erreurs pour l’ID d’instance d’orchestration affectée. Utilisez la requête de trace pour les erreurs et les avertissements dans Application Insights pour rechercher des erreurs liées à votre instance.
Vérifiez les files d'attente de contrôle stockage Azure pour voir si le « message de démarrage » de l'orchestration s'y trouve toujours. Dans le portail Azure, accédez à votre compte de stockage, sélectionnez Queues et recherchez des files d’attente avec un préfixe
control. Pour plus d’informations sur le fonctionnement des files d’attente de contrôle, consultez la documentation du fournisseur stockage Azure sur le contrôle des files d’attente.Remplacez la configuration de la plateforme de votre application par 64 bits. Les orchestrations échouent parfois au démarrage, car l’application manque de mémoire. Le passage à un processus 64 bits permet à l’application d’allouer plus de mémoire totale. Cette modification s’applique uniquement aux plans App Service Basic, Standard, Premium et Elastic Premium. Les plans gratuits ou de consommation ne prennent pas en charge les processus 64 bits.
Les orchestrations démarrent après un long délai
Normalement, les orchestrations démarrent dans les quelques secondes après leur planification. Toutefois, les orchestrations peuvent prendre plus de temps pour démarrer dans certains cas. Suivez ces étapes pour résoudre les problèmes lorsque les orchestrations prennent plus de quelques secondes pour démarrer l’exécution.
Vérifiez si le délai correspond à une limitation connaissante du fournisseur de stockage Azure, comme le rééquilibrage de partition ou les intervalles d’interrogation basés sur le minuteur.
Vérifiez les traces de Durable Task Framework à la recherche d’avertissements ou d’erreurs pour l’ID d’instance d’orchestration affectée. Utilisez la requête de recherche d’erreurs et d’avertissements de trace dans Application Insights pour identifier des erreurs liées à votre instance.
L’orchestration est bloquée dans l’état Running
Si votre état d’orchestration affiche « En cours d’exécution » pendant plus longtemps que prévu ou s’il semble avoir cessé de progresser, l’orchestration attend probablement une tâche qui n’a pas été terminée. Par exemple, il peut être en attente d’un minuteur durable, d’une tâche d’activité ou d’un événement externe. Si les tâches planifiées se sont terminées avec succès, mais que l’orchestration ne progresse toujours pas, il peut y avoir un problème qui l’empêche de passer à l’étape suivante. Les orchestrations dans cet état sont souvent appelées « orchestrations bloquées ».
Procédez comme suit pour résoudre les problèmes liés aux orchestrations bloquées :
Essayez de redémarrer l’application de fonction. Cette étape peut vous aider si l’orchestration est bloquée en raison d’un bogue temporaire ou d’un blocage dans l’application ou le code d’extension.
Vérifiez les files d’attente de contrôle du compte dans stockage Azure pour voir si certaines augmentent en continu. Utilisez la requête de messagerie stockage Azure dans Application Insights pour identifier les problèmes liés à la suppression des messages d’orchestration. Si le problème affecte uniquement une file d’attente de contrôle unique, il peut indiquer un problème sur une instance d’application spécifique. Dans ce cas, augmenter ou réduire la capacité pour déplacer l’instance de machine virtuelle défectueuse pourrait améliorer la situation.
Filtrez les résultats de la requête de messagerie stockage Azure en utilisant le nom de la file d'attente comme ID de partition pour rechercher des problèmes liés à cette partition spécifique de contrôle de la file d’attente.
Consultez la documentation de contrôle de version Durable Functions. Les modifications non rétrocompatibles apportées aux instances d’orchestration en cours d'exécution peuvent entraîner des orchestrations bloquées.
L’orchestration prend plus de temps que prévu pour se terminer
Le traitement de données lourd, les erreurs internes et les ressources de calcul insuffisantes peuvent entraîner l’exécution d’orchestrations plus lentes que la normale. Procédez comme suit pour résoudre les problèmes d’orchestration qui prennent plus de temps que prévu :
Vérifiez les traces de l’infrastructure des tâches durables à la recherche d’avertissements ou d’erreurs pour l’ID de l’instance d’orchestration impactée. Utilisez la requête de trace des erreurs et des avertissements dans Application Insights pour rechercher des erreurs liées à votre instance.
Si votre application utilise le modèle in-process .NET, envisagez d’activer les sessions extendées. Les sessions étendues réduisent les charges d’historique, ce qui peut ralentir le traitement.
Vérifiez les goulots d’étranglement des performances et de l’extensibilité. Une utilisation élevée du processeur ou une grande consommation de mémoire peut entraîner des retards. Pour obtenir des instructions détaillées, consultez Performance et mise à l’échelle dans Durable Functions.
Exemples de requêtes KQL pour le diagnostic de Durable Functions
Résolvez les problèmes en écrivant des requêtes KQL personnalisées dans l’instance Azure Application Insights configurée pour votre application Azure Functions. Pour connaître les définitions de colonnes utilisées dans ces requêtes, consultez la référence de colonne.
Messagerie Stockage Azure
Lorsque vous utilisez le fournisseur d'stockage Azure par défaut, tout le comportement des 'Durable Functions' est piloté par les messages de file d’attente d'stockage Azure, et tous les états liés à une orchestration sont stockés dans le stockage de tables et le stockage d’objets blob. Lorsque vous activez le suivi Durable Task Framework, toutes les interactions stockage Azure sont journalisées dans Application Insights. Ces données sont extrêmement importantes pour le débogage des problèmes d’exécution et de performances.
À compter de la version 2.3.0 de l’extension Durable Functions, vous pouvez publier ces journaux Durable Task Framework dans votre instance Application Insights en mettant à jour votre configuration de journalisation dans le fichier host.json. Pour plus d’informations, consultez l’article sur le suivi du Durable Task Framework.
La requête suivante inspecte les interactions de stockage Azure de bout en bout pour une instance d’orchestration spécifique. Modifiez start et filtrez orchestrationInstanceID par intervalle de temps et ID d’instance.
let start = datetime(XXXX-XX-XXTXX:XX:XX); // edit this
let orchestrationInstanceID = "XXXXXXX"; //edit this
traces
| where timestamp > start and timestamp < start + 1h
| where customDimensions.Category == "DurableTask.AzureStorage"
| extend taskName = customDimensions["EventName"]
| extend eventType = customDimensions["prop__EventType"]
| extend extendedSession = customDimensions["prop__IsExtendedSession"]
| extend account = customDimensions["prop__Account"]
| extend details = customDimensions["prop__Details"]
| extend instanceId = customDimensions["prop__InstanceId"]
| extend messageId = customDimensions["prop__MessageId"]
| extend executionId = customDimensions["prop__ExecutionId"]
| extend age = customDimensions["prop__Age"]
| extend latencyMs = customDimensions["prop__LatencyMs"]
| extend dequeueCount = customDimensions["prop__DequeueCount"]
| extend partitionId = customDimensions["prop__PartitionId"]
| extend eventCount = customDimensions["prop__TotalEventCount"]
| extend taskHub = customDimensions["prop__TaskHub"]
| extend pid = customDimensions["ProcessId"]
| extend appName = cloud_RoleName
| extend newEvents = customDimensions["prop__NewEvents"]
| where instanceId == orchestrationInstanceID
| sort by timestamp asc
| project timestamp, appName, severityLevel, pid, taskName, eventType, message, details, messageId, partitionId, instanceId, executionId, age, latencyMs, dequeueCount, eventCount, newEvents, taskHub, account, extendedSession, sdkVersion
Suivre les erreurs et les avertissements
La requête suivante recherche des erreurs et des avertissements pour une instance d’orchestration donnée. Fournir une valeur pour orchestrationInstanceID.
let orchestrationInstanceID = "XXXXXX"; // edit this
let start = datetime(XXXX-XX-XXTXX:XX:XX);
traces
| where timestamp > start and timestamp < start + 1h
| extend instanceId = iif(isnull(customDimensions["prop__InstanceId"] ) , customDimensions["prop__instanceId"], customDimensions["prop__InstanceId"] )
| extend logLevel = customDimensions["LogLevel"]
| extend functionName = customDimensions["prop__functionName"]
| extend status = customDimensions["prop__status"]
| extend details = customDimensions["prop__Details"]
| extend reason = customDimensions["prop__reason"]
| where severityLevel >= 1 // to see all logs of severity level "Information" or greater.
| where instanceId == orchestrationInstanceID
| sort by timestamp asc
Journaux de file d’attente de contrôle et d’ID de partition
La requête suivante recherche toutes les activités associées à la file d'attente de contrôle de l'identifiant d'instance. Indiquez la valeur de l’instanceID dans orchestrationInstanceID et de l’heure de début de la requête en start.
let orchestrationInstanceID = "XXXXXX"; // edit this
let start = datetime(XXXX-XX-XXTXX:XX:XX); // edit this
traces // determine control queue for this orchestrator
| where timestamp > start and timestamp < start + 1h
| extend instanceId = customDimensions["prop__TargetInstanceId"]
| extend partitionId = tostring(customDimensions["prop__PartitionId"])
| where partitionId contains "control"
| where instanceId == orchestrationInstanceID
| join kind = rightsemi(
traces
| where timestamp > start and timestamp < start + 1h
| where customDimensions.Category == "DurableTask.AzureStorage"
| extend taskName = customDimensions["EventName"]
| extend eventType = customDimensions["prop__EventType"]
| extend extendedSession = customDimensions["prop__IsExtendedSession"]
| extend account = customDimensions["prop__Account"]
| extend details = customDimensions["prop__Details"]
| extend instanceId = customDimensions["prop__InstanceId"]
| extend messageId = customDimensions["prop__MessageId"]
| extend executionId = customDimensions["prop__ExecutionId"]
| extend age = customDimensions["prop__Age"]
| extend latencyMs = customDimensions["prop__LatencyMs"]
| extend dequeueCount = customDimensions["prop__DequeueCount"]
| extend partitionId = tostring(customDimensions["prop__PartitionId"])
| extend eventCount = customDimensions["prop__TotalEventCount"]
| extend taskHub = customDimensions["prop__TaskHub"]
| extend pid = customDimensions["ProcessId"]
| extend appName = cloud_RoleName
| extend newEvents = customDimensions["prop__NewEvents"]
) on partitionId
| sort by timestamp asc
| project timestamp, appName, severityLevel, pid, taskName, eventType, message, details, messageId, partitionId, instanceId, executionId, age, latencyMs, dequeueCount, eventCount, newEvents, taskHub, account, extendedSession, sdkVersion
Informations de référence sur les colonnes d'Application Insights pour les requêtes de Durable Functions
Le tableau suivant répertorie les colonnes projetées par les requêtes précédentes et leurs descriptions.
| Colonne | Description |
|---|---|
| pid | ID de processus de l’instance de l’application de fonction. Cette valeur est utile pour vérifier si le processus a été recyclé lorsqu'une orchestration était en cours. |
| nomDeTâche | Nom de l’événement en cours de journalisation. |
| eventType | Type de message, qui représente généralement le travail effectué par un orchestrateur. Pour obtenir la liste complète des valeurs possibles et de leurs descriptions, consultez EventType.cs. |
| extendedSession | Valeur booléenne indiquant si les sessions étendues sont activées. |
| compte | Compte de stockage utilisé par l’application. |
| details | Informations supplémentaires sur un événement particulier, le cas échéant. |
| instanceId | ID d’une orchestration ou d’une instance d’entité donnée. |
| l'identifiant de message | ID de stockage Azure unique pour un message de file d’attente donné. Cette valeur apparaît généralement dans les événements de trace ReceivedMessage, ProcessingMessage et DeletingMessage. Cette valeur n'est pas présente dans les événements SendingMessage, car l'ID de message est généré par stockage Azure after le message est envoyé. |
| executionId | ID d’exécution de l’orchestrateur, qui change à chaque appel de continue-as-new. |
| âge | Nombre de millisecondes depuis qu’un message a été mis en file d’attente. De grands nombres indiquent souvent des problèmes de performances. Une exception est le type de message TimerFired, qui peut avoir une valeur Age élevée en fonction de la durée du minuteur. |
| latencyMs | Nombre de millisecondes prises par une opération de stockage. |
| dequeueCount | Nombre de fois qu’un message est mis en file d’attente. Dans des circonstances normales, cette valeur est toujours 1. Si c’est plusieurs, il peut y avoir un problème. |
| partitionId | Nom de la file d’attente associée à ce journal. |
| totalEventCount | Nombre d’événements d’historique impliqués dans l’action actuelle. |
| taskHub | Nom de votre hub de tâches. |
| newEvents | Liste, séparée par des virgules, des événements d’historique en cours d’écriture dans la table de l’historique du stockage. |
Problèmes de gestion des connexions dans le plan Consommation
Les applications s’exécutant sur le plan consommation Azure Functions sont soumises aux limites de connexion. Les symptômes courants sont les suivants :
- Erreurs de connectivité intermittentes lors de l’appel de fonctions d’activité ou de services externes.
- Orchestrations qui échouent de manière sporadique sous charge.
- Erreurs d’épuisement des sockets dans les journaux.
Pour réduire l’utilisation de la connexion, utilisez HttpClientFactory ou partagez des clients statiques au lieu de créer de nouvelles HttpClient instances dans chaque appel de fonction. Pour obtenir des instructions détaillées sur le regroupement de connexions et les meilleures pratiques, consultez Gérer les connexions dans Azure Functions.
Conseils généraux
Conseil / Astuce
Avant de vous plonger dans des étapes de résolution des problèmes spécifiques, vérifiez que votre application utilise la dernière version de l’extension Durable Functions. La plupart du temps, l’utilisation de la dernière version atténue les problèmes connus déjà signalés par d’autres utilisateurs. Pour obtenir des instructions sur la mise à niveau, consultez la version de mise à niveau de l'extension Durable Functions.
L’onglet Diagnose et résoudre les problèmes dans le portail Azure peut aider à surveiller et diagnostiquer les problèmes liés à votre application et à suggérer des solutions potentielles. Pour plus d’informations, consultez les diagnostics pour les applications Fonction Azure.
Obtenir du support pour les problèmes de Durable Functions
Si vous ne pouvez pas résoudre votre problème à l'aide de ce guide, vous pouvez envoyer un ticket de support en ouvrant la section New Support request dans le panneau Support + dépannage de la page de votre application de fonction dans le portail Azure.
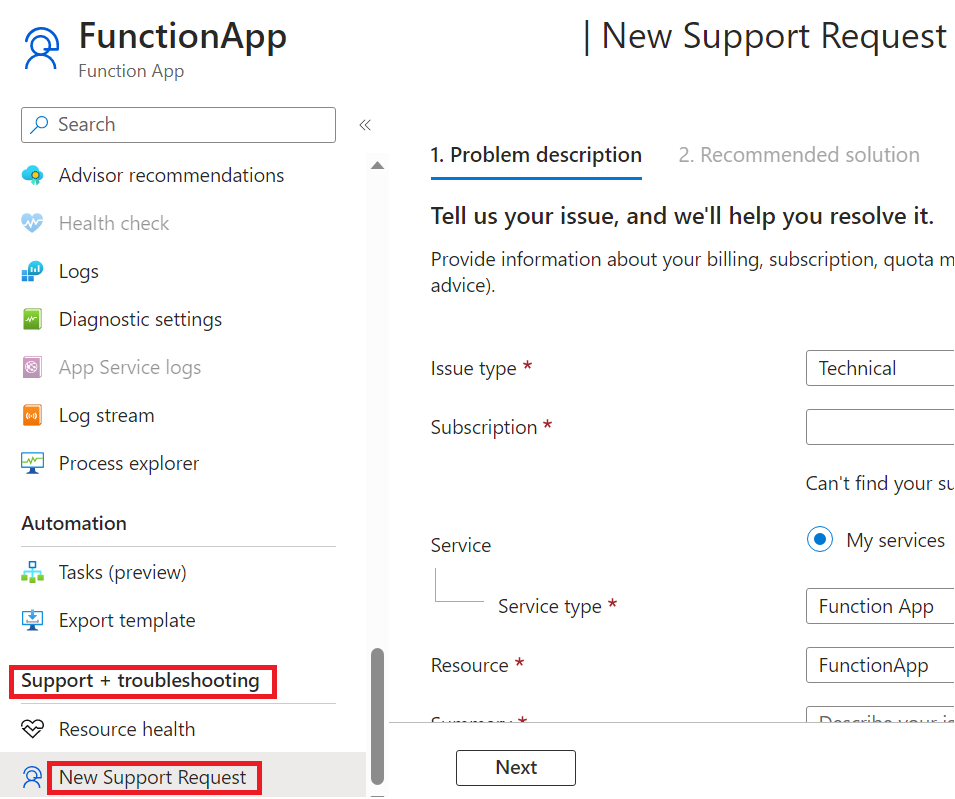
Pour les questions et le support communautaire, ouvrez un problème dans l’un des dépôts de GitHub suivants. Lorsque vous signalez un bogue, incluez des informations telles que les ID d’instance affectés, les intervalles de temps UTC montrant le problème, le nom de l’application (le cas échéant) et la région de déploiement pour accélérer les enquêtes.