Muistiinpano
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää kirjautua sisään tai vaihtaa hakemistoa.
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää vaihtaa hakemistoa.
Microsoft Fabric Data Engineering- ja Data Science -kokemukset toimivat täysin hallitussa Spark-käsittelyympäristössä. Oletuksena kaikki Spark-työt työtilassa jakavat saman poolin ja resurssien asetukset, mutta eri työkuormilla on usein erilaiset vaatimukset. Kevyt datamuunnos ei tarvitse samaa ajurimuistia kuin laajamittainen koneoppimistyö.
Fabric-ympäristöt mahdollistavat Sparkin laskentakonfiguraatioiden räätälöinnin työkuorman mukaan, joten jokainen muistikirja tai Spark-työn määrittely voi toimia oikealla ajonaikaisella versiolla, poolilla ja ajurin/suorittimen kokoilla ilman, että koko työtilan oletuksia tarvitsee muuttaa.
Määritä työtilan tason laskenta-asetukset
Työtilan ylläpitäjät hallitsevat, voivatko ympäristön kohteet ohittaa työtilan oletuslaskentakonfiguraation. Objektitason räätälöinnin estäminen estää resurssien johdonmukaisen käytön koko työtilassa. Sen mahdollistaminen antaa jäsenille ja osallistujille joustavuutta säätää laskentaa yksittäisille työkuormille.
Selaimessasi mene Fabric-työtilaan Fabric-portaalissa.
Valitse Työtilan asetukset.
Valitse Data Engineering/Science ja sitten Spark settings.
Valitse Pool-välilehti .
Laita Mukauta laskentaasetukset esineillepäälle.
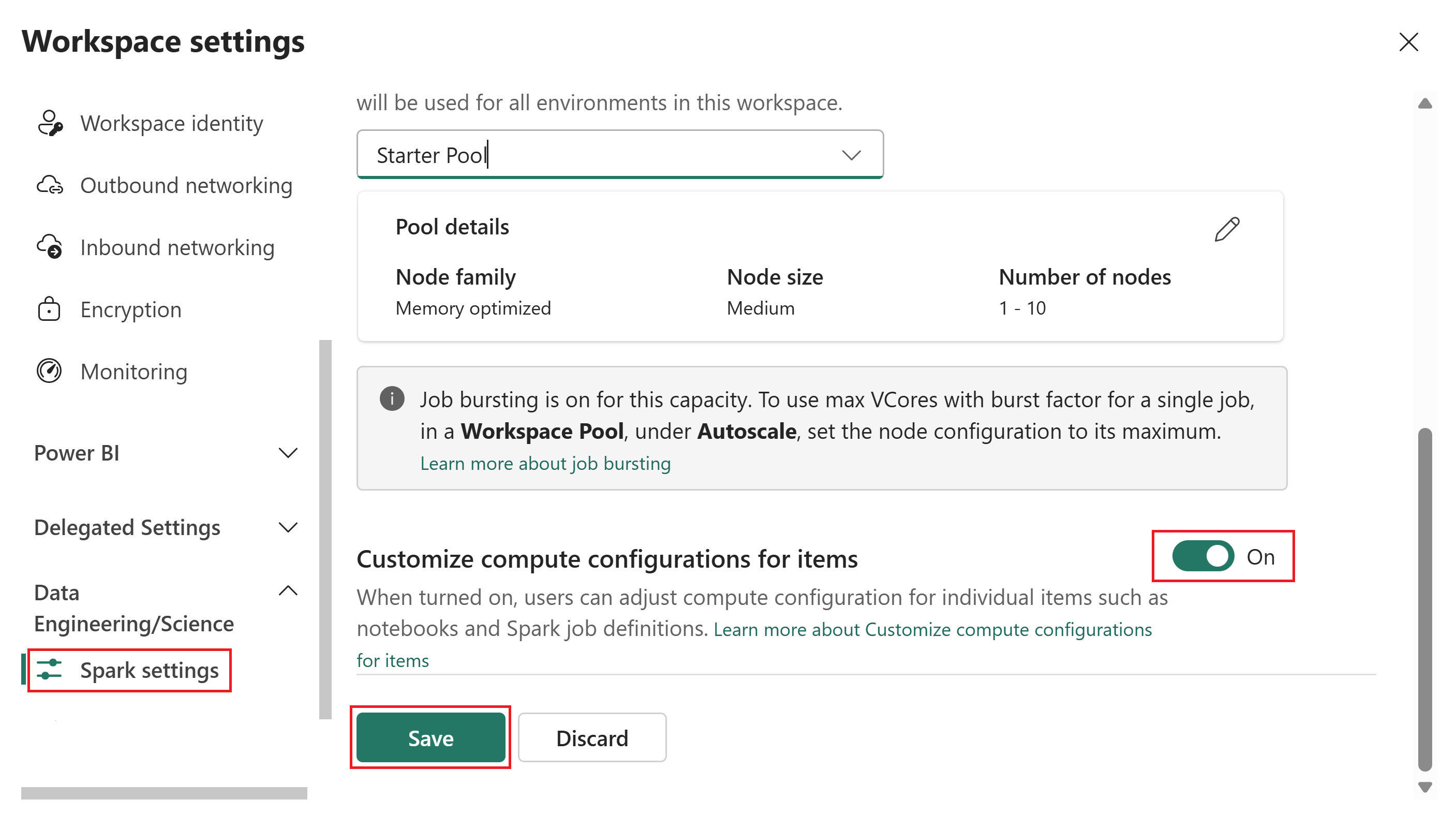
Kun tämä kytkin on päällä, jäsenet ja osallistujat voivat muuttaa istuntotason laskentakonfiguraatioita Fabric-ympäristössä. Kun se on pois päältä, ympäristökohteiden Compute-osio on poistettu käytöstä ja kaikki Spark-tehtävät käyttävät työtilan oletuspoolia.
Valitse Tallenna.

Konfiguroi laskenta ympäristössä
Kun työtilan ylläpitäjä on sallinut kohdetason mukauttamisen, voit konfiguroida laskentaasetukset ympäristön sisällä. Tähän kuuluu Spark-suoritusajan valinta, poolin valinta sekä ajurin ja toimeenpanijan resurssien virittäminen.
Valitse Sparkin suoritusaika
Avaa ympäristösi.
Home-välilehdellä valitse Runtime-pudotusvalikko ja valitse ajonaikainen versio.
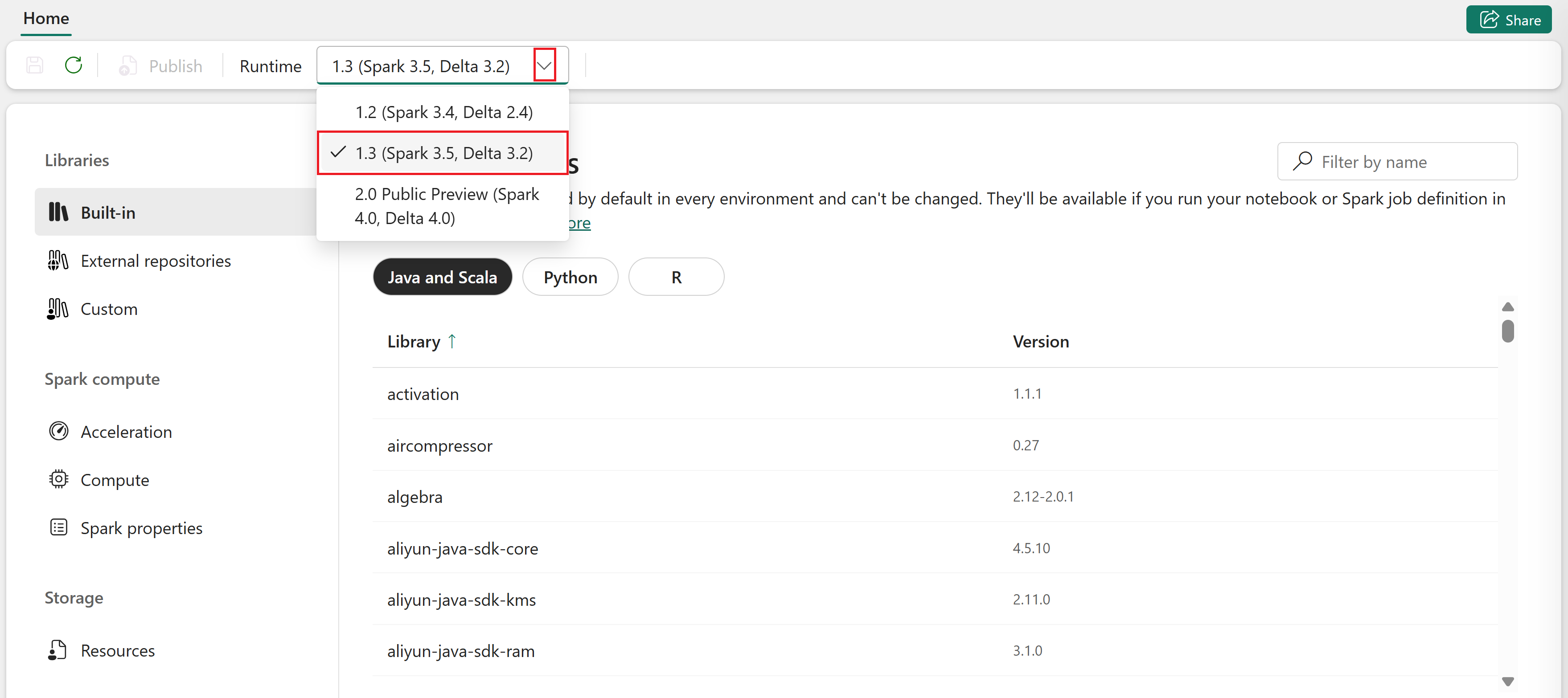

Jokaisella Spark-ajonaikalla on omat oletusasetuksensa ja valmiiksi asennetut paketit.
Tärkeää
- Ajonaikaiset muutokset eivät astu voimaan ennen kuin tallennat ja julkaiset ympäristön.
- Jos olemassa olevat kirjastot tai laskenta-asetukset eivät ole yhteensopivia valitun ajontimen kanssa, julkaisu epäonnistuu. Poista tai päivitä yhteensopimattomat asetukset ja julkaise uudelleen.
- Vaiheittaiset julkaisuohjeet löytyvät kohdasta Tallenna ja julkaise muutokset.
Valitse pooli ja säädä laskentaominaisuuksia
Avaa ympäristö ja siirry Laskenta-osioon .
Ympäristöpoolista valitse aloituspooli tai työtilan ylläpitäjän luoma mukautettu pooli.
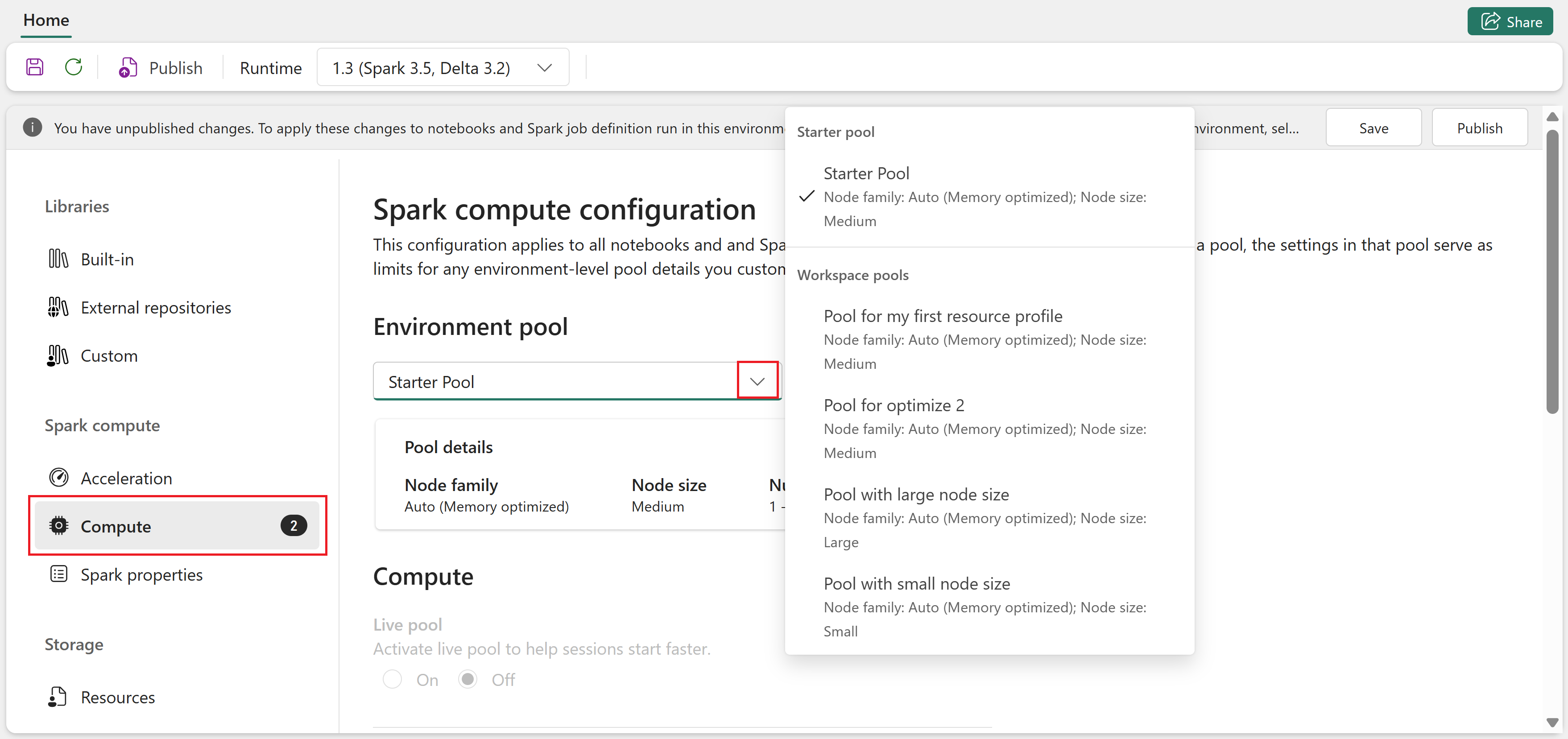
Käytä Compute-sivun pudotusvalikkoja määrittääksesi istuntotason Spark-ominaisuudet valitulle poolille. Käytettävissä olevat arvot riippuvat poolin solmun koosta.

Kiinteistöihin kuuluvat:
- Kipinäelementin ytimet – Kipinäajuimelle varattujen ytimien määrä.
- Kipinäajurimuisti – Kipinäajurille varatun muistin määrä.
- Spark executor -ytimet – Ytimien määrä, jotka on varattu kullekin executorille.
- Spark executor memory – Muistin määrä, joka on varattu kullekin executorille.


Lisätietoja käytettävissä olevista uima-altaan koosta ja resurssirajoituksista löytyy Spark-laskenta Fabricissa.
Muistio
Kipinäominaisuudet asetetaan ohjaussovellustason spark.conf.set parametrien kautta, eivätkä liity tässä kuvattuihin ympäristölaskenta-asetuksiin.