Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se describe cómo usar la integración de Databricks Connect en la extensión Databricks para Visual Studio Code para ejecutar y depurar archivos Python individuales (.py). Para obtener información sobre la extensión, consulte Databricks extension for Visual Studio Code.
La integración de Databricks Connect también permite ejecutar y depurar celdas del bloc de notas. Consulte Ejecutar y depurar celdas de cuadernos con Databricks Connect usando la extensión de Databricks para Visual Studio Code.
Requisitos
Para poder usar Databricks Connect desde la extensión de Databricks para Visual Studio Code, primero debe cumplir los requisitos de Databricks Connect. Estos requisitos incluyen aspectos como un área de trabajo habilitada para el catálogo de Unity, requisitos de proceso y requisitos de versión para la instalación local de Python.
Activación de un entorno virtual de Python
Active un entorno Python virtual para el proyecto de Python. Los entornos virtuales de Python ayudan a garantizar que tu proyecto esté utilizando versiones compatibles de Python y paquetes de Python (en este caso, el paquete Databricks Connect).
En el panel Configuración:
- Haga clic en el elemento rojo Activate Virtual Environment en Python Environment.
- En la Paleta de comandos, seleccione Venv o Conda.
- Seleccione las dependencias que quiere instalar, en caso de que corresponda.
Instalación de Databricks Connect
En la vista Configuration en Python Environment:
- Haga clic en el botón rojo de reproducción Instalar databricks-connect.
- Adjunte un clúster.
- Si la sección Clúster aún no está configurada en la extensión, aparece el siguiente mensaje: "Adjunte un clúster para usar Databricks Connect". Haga clic en Asociar clúster y seleccione un clúster que cumpla los requisitos de Databricks Connect.
- Si la sección Clúster está configurada, pero el clúster no es compatible con Databricks Connect, haga clic en el botón rojo Databricks Connect deshabilitado, haga clic en Asociar clúster y seleccione un clúster compatible.
- Si el paquete Databricks Connect (y sus dependencias) no están ya instalados, aparece el siguiente mensaje: "Para la depuración interactiva y la función de autocompletado, es necesario Databricks Connect". Le gustaría instalarlo en el entorno
<environment-name>". Haga clic en Instalar. - En la barra de estado de Visual Studio Code, si se muestra el botón rojo Databricks Connect deshabilitado, haga clic en él y complete las instrucciones en pantalla para activarlo.
- Una vez que aparezca el botón Databricks Connect habilitado, ya estará listo para usar Databricks Connect.
Nota:
Si usa Poetry, puede sincronizar los archivos pyproject.toml y poetry.lock con el paquete de Databricks Connect instalado (y sus dependencias) ejecutando el comando siguiente. Asegúrese de reemplazar 16.4.1 por la versión del paquete de Databricks Connect que coincida con la instalada por la extensión de Databricks para Visual Studio Code para el proyecto.
poetry add databricks-connect==16.4.1
Ejecuta o depura tu código Python
Después de habilitar Databricks Connect, ejecute o depure el archivo de Python (.py):
En el proyecto, abra el archivo Python que desea ejecutar o depurar.
Establezca los puntos de interrupción de depuración dentro del archivo Python.
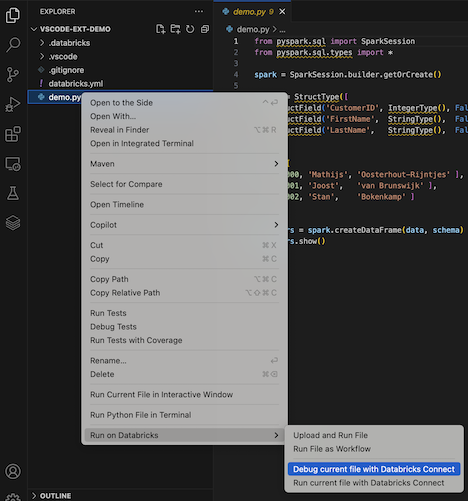
Haga clic en el icono Ejecutar en Databricks junto a la lista de pestañas del editor y, a continuación, haga clic en Depurar archivo actual con Databricks Connect.
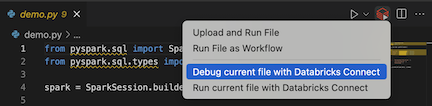
La salida aparece en el panel Consola de depuración.
También puede hacer clic con el botón derecho en el archivo
.pyy luego hacer clic en Ejecutar en Databricks>Depurar archivo actual con Databricks Connect.