Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Nota:
Este artículo describe Databricks Connect para Databricks Runtime 13.3 LTS y versiones posteriores.
Databricks Connect es una biblioteca cliente para Databricks Runtime que permite conectarse a la computación de Azure Databricks desde IDEs como Visual Studio Code, PyCharm e IntelliJ IDEA, cuadernos y cualquier aplicación personalizada, para habilitar experiencias interactivas de usuario nuevas basadas en su Azure Databricks Lakehouse.
Databricks Connect está disponible para los siguientes idiomas:
¿Qué puedo hacer con Databricks Connect?
Con Databricks Connect, puedes escribir código utilizando las API de Spark y ejecutarlo de forma remota en el proceso de Azure Databricks en vez de en la sesión local de Spark.
Desarrolle y depure de forma interactiva desde cualquier IDE. Databricks Connect permite a los desarrolladores desarrollar y depurar su código en el proceso de Databricks mediante la funcionalidad nativa de ejecución y depuración de cualquier IDE. La extensión Databricks Visual Studio Code usa Databricks Connect para proporcionar una depuración integrada del código de usuario en Databricks.
Cree aplicaciones de datos interactivas. Al igual que un controlador JDBC, la biblioteca de Databricks Connect se puede incrustar en cualquier aplicación para interactuar con Databricks. Databricks Connect proporciona la expresividad completa de Python a través de PySpark, lo que elimina el desajuste de impedancia del lenguaje SQL y le permite ejecutar todas las transformaciones de datos con Spark en la computación escalable sin servidor de Databricks.
¿Cómo funciona?
Databricks Connect se basa en Spark Connect de código abierto, que tiene una arquitectura de servidor cliente desacoplada para Apache Spark que permite la conectividad remota a clústeres de Spark mediante la API DataFrame. El protocolo subyacente utiliza planes lógicos sin resolver de Spark y Apache Arrow sobre gRPC. La API de cliente está diseñada para ser delgada, de modo que se pueda incrustar en todas partes: en servidores de aplicaciones, IDE, cuadernos y lenguajes de programación.
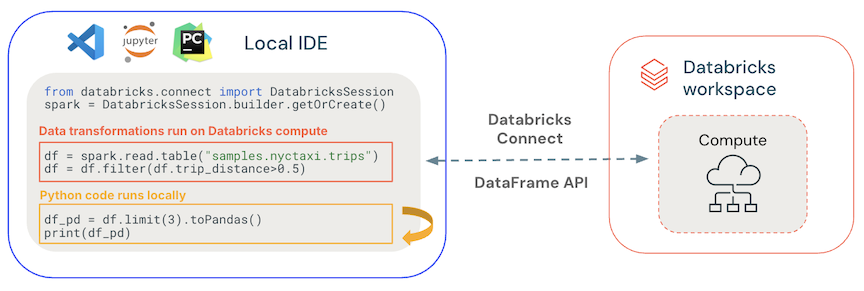
- El código general se ejecuta localmente: el código Python y el código Scala se ejecutan en el lado del cliente, lo que permite la depuración interactiva. Todo el código se ejecuta localmente, mientras que todo el código de Spark continúa ejecutándose en el clúster remoto.
-
Las APIs de DataFrame se ejecutan en los recursos de computación de Databricks. Todas las transformaciones de datos se convierten en planes de Spark y se ejecutan en la capacidad de cómputo de Databricks mediante la sesión remota de Spark. Se materializan en el cliente local cuando se usan comandos como
collect(),show(),toPandas(). -
El código UDF se ejecuta en el proceso de Databricks: las UDF definidas localmente se serializan y transmiten al clúster donde se ejecuta. Las API que ejecutan código de usuario en Databricks incluyen: UDF,
foreach,foreachBatchytransformWithState. - Para la administración de dependencias:
- Instale las dependencias de la aplicación en el equipo local. Se ejecutan localmente y deben instalarse como parte del proyecto, como parte del entorno virtual de Python.
- Instale las dependencias de UDF en Databricks. Consulte Administración de dependencias de UDF.
¿Cómo están relacionados Databricks Connect y Spark Connect?
Spark Connect es un protocolo basado en gRPC de código abierto dentro de Apache Spark que permite la ejecución remota de cargas de trabajo de Spark mediante la API DataFrame.
Para Databricks Runtime 13.3 LTS y versiones posteriores, Databricks Connect es una extensión de Spark Connect con adiciones y modificaciones para admitir el trabajo con los modos de proceso de Databricks y el Catálogo de Unity.
Pasos siguientes
Consulte los siguientes tutoriales para empezar a desarrollar rápidamente soluciones de Databricks Connect:
- Databricks Connect para Python tutorial de cómputo clásico
- Tutorial de computación sin servidor de Databricks Connect para Python
- Tutorial de cómputo clásico para Scala con Databricks Connect
- Tutorial de proceso sin servidor de Databricks Connect para Scala
- Tutorial de Databricks Connect para R
Para ver aplicaciones de ejemplo que usan Databricks Connect, consulte el repositorio de ejemplos GitHub, que incluye los ejemplos siguientes: