Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Dieser Artikel bietet praktische Anleitungen für die Planung von Kapazität und Compute für Spark-Workloads in Microsoft Fabric, die Entwicklung, Migration und Produktionsszenarien abdecken.
Richtlinien für die Dimensionierung
Dieser Abschnitt enthält praktische Anleitungen zum Skalieren und Konfigurieren von Spark-Workloads in Microsoft Fabric. Es umfasst Szenarien wie neue Entwicklung, Migration von Synapse und Kapazitätsoptimierung für den Produktionseinsatz.
Szenario: Sie sind neu bei Fabric und benötigen Anleitungen zur Kapazitätsplanung.
Beginnen Sie mit der Testkapazität: Wenn Sie noch nicht mit Fabric vertraut sind, beginnen Sie mit der Testkapazität. Es bietet entweder eine F4-Kapazität (4 Kapazitätseinheiten) oder eine F64-Kapazität (64 Kapazitätseinheiten) mit einem Durchsatz für 60 Tage an. Dieses Setup eignet sich ideal zum Entwickeln und Testen von Spark-Workloads. Um Ihre erforderliche Kapazität zu schätzen, wechseln Sie zu Planen der Kapazitätsgröße und dem Microsoft Fabric SKU-Schätzer (Vorschau).
Auswählen des Starterpools im Vergleich zum benutzerdefinierten Pool:
Starterpools: In der Regel möchten Sie Startpools für Ihre Spark-Workloads verwenden. Microsoft Fabric stellt diese Pools vorab bereit, um schnelle Sitzungsstartzeiten sicherzustellen. Sie eignen sich ideal für Entwicklungsumgebungen, in denen Sie keine benutzerdefinierten Bibliotheken, verwalteten privaten Endpunkt (MPE) oder private Verknüpfungen (PRIVATE Link, PL) benötigen. Starterpools können die Produktivität der Entwickler erheblich verbessern.
Benutzerdefinierte Pools: Verwenden Sie benutzerdefinierte Pools, wenn Sie verwaltete private Endpunkte (MANAGED Private Endpoint, MPE) oder private Verknüpfung (PRIVATE Link, PL) aktivieren.
Weitere Informationen zu Start- und benutzerdefinierten Pools finden Sie in der Apache Spark Compute for Data Engineering and Data Science-Dokumentation.
Profilieren von Spark-Notizbüchern:
Um Spark-Anwendungen in Fabric zu überwachen, können Sie Folgendes verwenden:
Spark History Server: Zur detaillierten Analyse einzelner Anwendungsdetails sowie granularerer Stufenebene, Aufgabenebene, Verteilungen, logischer und physischer Plan.
Benutzeroberfläche für die Ressourcennutzung: Um die Ausführungsauslastung und die Anzahl der Executoren zu analysieren, die nach jeder Phase nach oben oder unten skaliert wurden.
Überwachungs-Benutzeroberfläche: 30-Tage-Metriken der Notebook/Spark Job Definition (SJD)/Pipeline-Ausführungsdetails auf hohem Niveau, wie Ausführungszeit, Status, Übermittlung von usw. Die Überwachungs-Benutzeroberfläche ist hervorragend für die inter-App Sichtbarkeit geeignet.
Diagnose-Emittererweiterung: So senden Sie Protokolle an Ziele wie Azure-Protokollanalysen, Azure-Speicher und Azure-Ereignishubs aus. Dies eignet sich hervorragend für eine langfristige Trendanalyse.
Beginnen Sie im Allgemeinen mit der Profilerstellung Ihrer Anwendung mit Starterpools (mittlere Spark Pools (8 vCores und 64 GB Arbeitsspeicher)). Beginnen Sie mit mindestens einem Knoten, und beobachten Sie die Ausführungszeit.
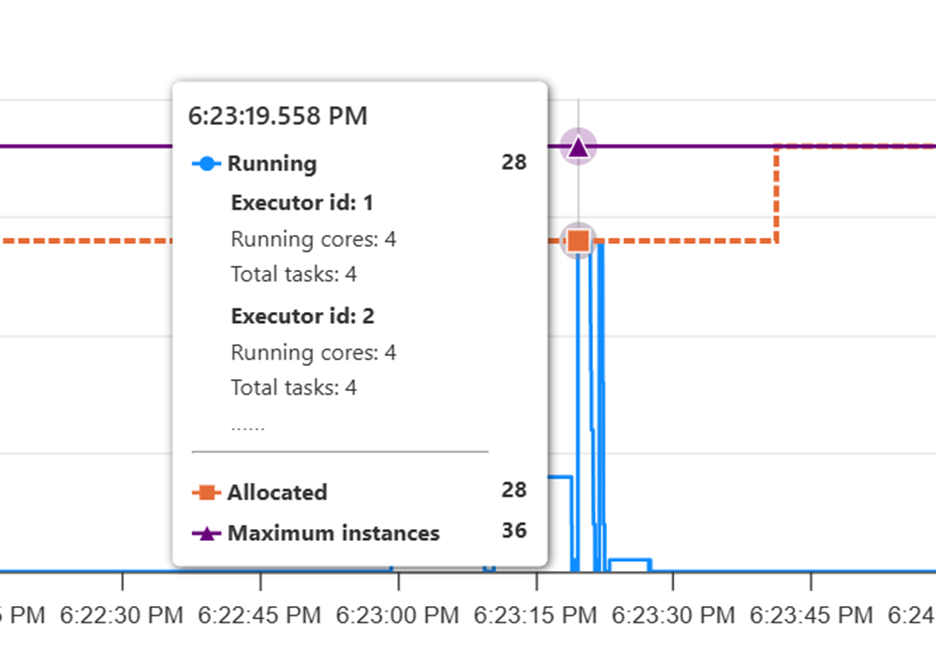
Um die Ressourcennutzung zu beobachten, navigieren Sie zur Spark-Ressourcennutzung-Oberfläche. Wenn die zugeordneten Instanzen in der Benutzeroberfläche für die Ressourcennutzung weniger als die maximalen Instanzen in der Stufe mit der höchsten Anzahl von Aufgaben sind, reduzieren Sie die maximale Knotenanzahl im Spark Auto Scaling, um sie an die zugeordneten Instanzen anzupassen.

Wenn sich die maximalen und zugewiesenen Instanzen überschneiden, sollten Sie die maximale Anzahl der Knoten erhöhen, um Parallelität und Leistung zu verbessern.


Behandlung von Datenverzerrung:
- Wenn Sie Datenverzerrung feststellen, könnte es möglicherweise nicht helfen, einfach mehr Ressourcen hinzuzufügen. Beheben Sie Schiefe mithilfe von Techniken wie der Umpartitionierung, wenn ungleiche Datenverteilung die Schiefe verursacht.
- Im Artikel zur Entwicklung und Überwachung dieser Serie finden Sie Anleitungen zum Identifizieren und Behandeln von Ungleichgewichten.
Auswertung der Auslastung: Verwenden Sie die Kapazitätsmetriken-App, um die Auslastung auszuwerten und die optimale Kapazitätsgröße für Ihre Workloads zu schätzen. Weitere Details finden Sie in der Dokumentation zur Überwachung des Apache Spark-Kapazitätsverbrauchs. Nachdem Sie die Auslastung der Testkapazität analysiert haben, wählen Sie die passende Pay-as-you-go-Kapazität für Ihre PoCs aus und wechseln dann zu einer Kapazität, die von einer Reservierung (RI) oder einem automatisch skalierten Abrechnungsmodell unterstützt wird. RI ist eine einjährige Verpflichtung. Eine Bezahle-nach-Nutzung-Kapazität kann jederzeit storniert werden. RI bietet ca. 40% Rabatt gegenüber pay-as-you-go Kapazität.
Szenario: Ausführen von Spark-Arbeitslasten auf Pay-as-you-go-Kapazität. Welches ist das optimale Kapazitätsmodell, das man wählen sollte?
Wenn Sie Spark-Workloads auf einer kostenpflichtigen Kapazität ausführen, sollten Sie die Umstellung auf die automatische Skalierung in Betracht ziehen. Autoscale bietet die gleiche vertragliche Flexibilität wie pay-as-you-go, aber mit dem Vorteil, das Risiko der Drosselung zu beseitigen. Aufträge werden jedoch in die Warteschlange gestellt, wenn nicht genügend Ressourcen vorhanden sind und die Kosten niedriger sind.
Sie könnten auch ein Hybridmodell mit einer Reservierung für stabile Workloads und Autoscale für variablere Workloads in Betracht ziehen. Reservierungen bieten die beste Kostenleistung, solange die Kapazitäten gut genutzt bleiben (mehr als 75% im Durchschnitt für die Laufzeit des Vertrags).
Im Allgemeinen gibt es nicht viele Gründe, warum Sie pay-as-you-go über die zuvor erläuterten Optionen bevorzugen:
Sie verfügen bereits über eine nach Bedarf Kapazität, die nicht-Spark-Arbeitslasten ausführen und mehr Kapazität haben, um Ihre Spark-Aufträge auszuführen. Die marginalen Kosten für das Hinzufügen eines weiteren Auftrags zu einer Kapazität betragen null (obwohl Sie bei zu vielen eine Drosselung verursachen könnten). Auch hier sollten Sie die Reservierung für ein Jahr zu einem reduzierten Preis in Betracht ziehen, wenn möglich.
Sie haben ein kurzfristiges PoC- oder Entwicklungsprojekt, bei dem die Kostenprognose wichtiger ist als die Kosteneffizienz – mit einer festen Kapazität, für die Sie jeden Monat einen festgelegten Betrag zahlen. Wenn Sie die Kapazität überschreiten, werden Ihnen keine zusätzlichen Gebühren berechnet, stattdessen werden Sie gedrosselt. Bei Autoscale werden Ihnen die Kosten für Ihre Nutzung berechnet, was zu Kostenüberschreitungen führen kann, wenn fehlerhafter Code in Ihrer Entwicklungsumgebung ausgeführt wird. Für ein Entwicklungsprojekt mit einem eng verwalteten Budget kann dies ein lohnenswerter Kompromiss sein.
So optimieren Sie die Ressourcennutzung weiter:
Sie können mehrere Spark-Notizbücher in einer einzigen Spark-Sitzung mit hoher Parallelität ausführen, um die Ressourcennutzung zu optimieren.
Aktivieren Sie die Native Execution Engine (NEE), um die Leistung erheblich zu steigern.
Szenario: Sie migrieren Workloads von Synapse zu Fabric.
Wenn Sie Workloads von Synapse zu Fabric migrieren, fragen Sie sich möglicherweise, welche Änderungen geändert werden, was gleich bleibt und ob Sie die vorhandene Synapse-Größenanpassung wiederverwenden können.
Migration und Optimierung:
Verwenden Sie das Synapse-zu-Fabric-Migrationsprogramm, um Ihre Workloads zu verschieben.
Aktivieren Sie die Automatische Abrechnung für Spark. Wenn die Umgebung und das Lakehouse identisch sind, führen Sie die Notizbücher oder Pipelines im Modus für hohe Parallelität (ein Feature, das in Synapse nicht verfügbar ist) aus, um eine bessere Leistung zu erzielen.
Profilieren Sie die Notebooks mit der Native Execution Engine (NEE), um die Leistung Ihrer Workloads zu optimieren.
Allgemeine Richtlinien für die Rechnerkonfiguration:
| Szenario | Guidance |
|---|---|
| Transformieren von schweren Aufträgen mit Shuffles & Joins | Verwenden größerer Knoten (16 bis 64 Kerne) |
| Plötzlich auftretende oder unvorhersehbare Aufgaben | Verwenden Sie Spark Autoscale + Dynamic Allocate, damit der Cluster nach Bedarf vergrößert/verkleinert werden kann. Funktioniert gut, wenn Aufträge in der Größe variieren. |
| Viele kleine parallele Aufträge (z. B. Streaming oder Batch-Microjobs) | Verwenden Sie kleine oder mittlere Knoten. Konfigurieren Sie eine minimale Anzahl von Knoten, um Verzögerungen beim Kaltstart zu vermeiden. Für kleinere Aufträge können Sie sie mithilfe von notebookutils.notebook.runMultiple() koordinieren, wodurch mehrere Notizbücher parallel ausgeführt werden können. |
| Kleine seriell verarbeitete Aufträge oder Entwicklungsarbeiten | Verwenden Sie kleine oder mittlere Knoten im Einzelknotenmodus (Treiber und Executor teilt 1 VM). |
| Große Aufträge mit bekannter Partitionierung | Größen Sie das Cluster manuell vor: Wählen Sie die minimale Knotengröße und Anzahl basierend auf dem Datenvolumen und den Shuffle-Phasen. |
| ML oder verteiltes Training | Verwenden Sie viele mittlere/große Knoten, um Parallelität zu maximieren und Compute gleichmäßig zu verteilen. |
| Um nur Python-Code auszuführen | Verwenden des Python-Kernels |