Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Använd anpassade Spark-pooler för att skräddarsy beräkningar för dina arbetsbelastningar i Fabric. Du kan välja nodstorlek, konfigurera autoskalningsbeteende och aktivera dynamisk körallokering.
Med anpassade pooler kan du balansera prestanda och kostnader genom att ange skalningsgränser som matchar arbetsbelastningens efterfrågan.
Anmärkning
Anpassade Spark-pooler kan uppnå cirka 5 sekunders sessionstart när de konfigureras som en anpassad livepool med en miljö som använder Fullt läge för bibliotekspublicering. Det tar ungefär tre minuter att starta anpassade Spark-pooler utan konfiguration av livepooler.
Om du redan använder startpooler är anpassade pooler ett kompletterande alternativ när du behöver mer kontroll över storleks- och skalningsbeteendet för specifika arbetsbelastningar. Använd startpooler för snabb start och standardinställningar och flytta till anpassade pooler när du behöver arbetsbelastningsspecifik beräkningsjustering. Mer information om startpooler finns i Konfigurera startpooler i Fabric.
Förutsättningar
Så här skapar du en anpassad Spark-pool:
- Du behöver administratörsrollen på arbetsytan.
- En kapacitetsadministratör måste aktivera anpassade arbetsytepooler i Spark Compute-inställningar för kapaciteten.
Mer information finns i Konfigurera och hantera datateknik och datavetenskapsinställningar för Fabric-kapaciteter.
Skapa anpassade Spark-pooler
Så här skapar eller hanterar du Spark-poolen som är associerad med din arbetsyta:
Gå till din arbetsyta och välj Inställningar för arbetsyta.

Välj alternativet Data Engineering/Science för att expandera menyn och välj sedan Spark-inställningar.

Välj Ny pool från listrutan Standardpool för arbetsyta för att skapa en ny anpassad Spark-pool. Du kan skapa flera anpassade pooler och välja någon av dem som standardpool för din arbetsyta.
På sidan Skapa ny pool anger du ett poolnamn. Välj en Nod-familj (till exempel Minnesoptimerad) och Nodstorlek baserat på arbetsbelastningskrav. Mer information om nodstorlekar finns i avsnittet Alternativ för nodstorlek nedan.
Tips/Råd
Nodstorleken bestäms av kapacitetsenheter (CU) som representerar den beräkningskapacitet som tilldelats varje nod.
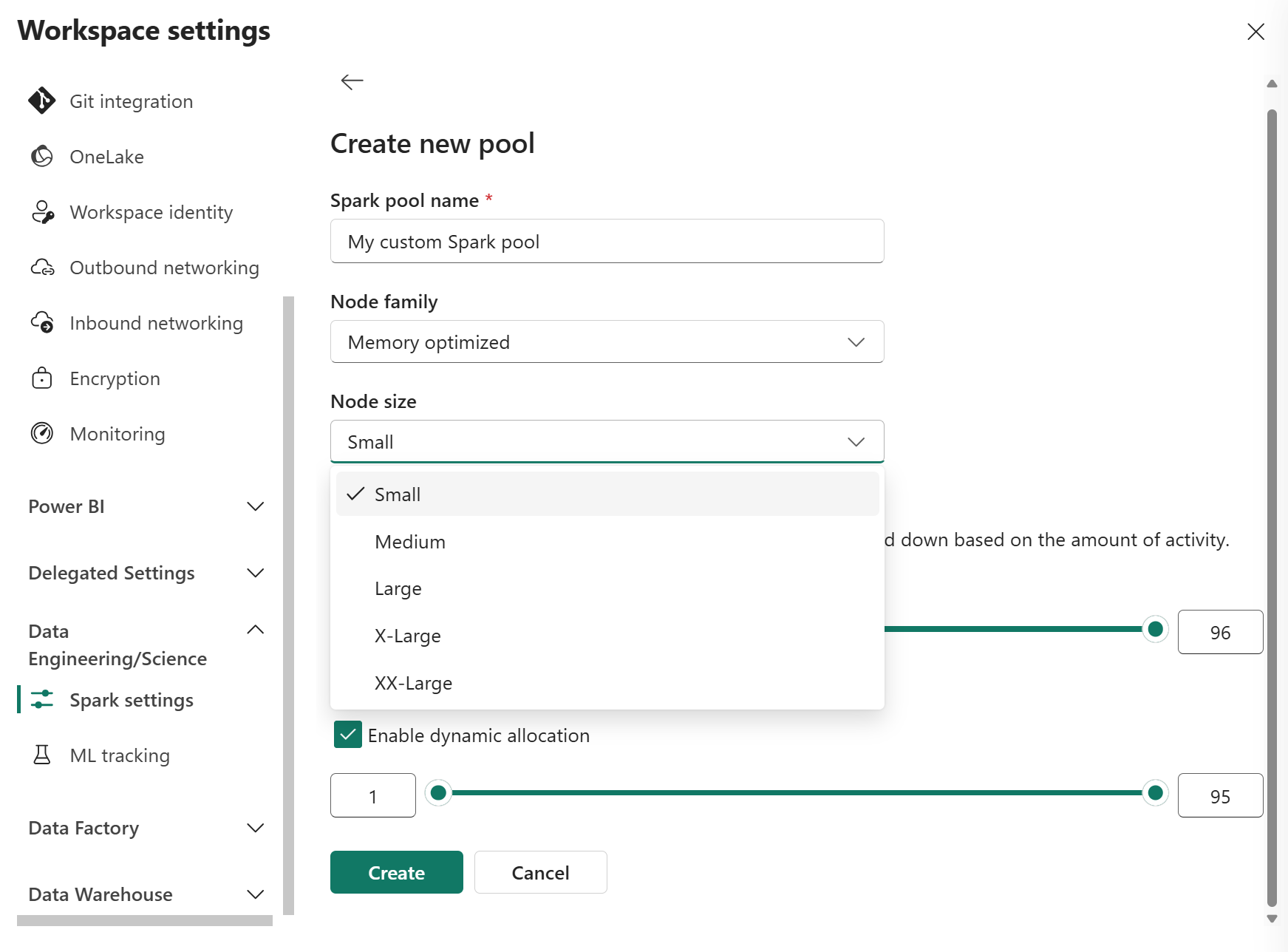
I redigeringsvyn konfigurerar du Autoskalning och Allokerar köre dynamiskt.

Använd skjutreglagen för att öka eller minska varje inställning baserat på dina arbetsbelastningsbehov.
Om autoskalning är aktiverat skalar poolen mellan de konfigurerade lägsta och högsta nodvärdena baserat på aktivitet.
Om Dynamiskt allokera utförare är aktiverat justerar Fabric utförarallokeringen baserat på arbetsbelastning inom de konfigurerade gränserna.
Välj Skapa.




Tips/Råd
När du har skapat en anpassad Spark-pool beror tidpunkten för biblioteksdistribution på publiceringsläget i den anslutna miljön. Snabbläget publiceras på cirka 5 sekunder och installerar bibliotek vid sessionsstart. Fullt läge tar 3 till 6 minuter att publicera och distribuerar bibliotek som en del av sessionens start (1 till 3 minuter). För den snabbaste upplevelsen konfigurerar du poolen som en anpassad livepool med fullständigt läge för att uppnå cirka 5 sekunders sessionsstarter.
Anpassade pooler har en standardtid för autopaus på 2 minuter efter inaktivitet. När autopaus uppnås avslutas sessionen och klustret avallokeras. Faktureringen gäller endast när beräkning används aktivt. Anpassade Spark-pooler i Microsoft Fabric stöder för närvarande en maximal nodgräns på 200, så se till att dina lägsta och högsta autoskalningsvärden förblir inom den här gränsen.
Alternativ för nodstorlek
När du konfigurerar en anpassad Spark-pool väljer du mellan följande nodstorlekar:
| Nodstorlek | vCores | Minne (Gigabyte) | Beskrivning |
|---|---|---|---|
| Liten | 4 | 32 | För lätta utvecklings- och testjobb. |
| Medel | 8 | 64 | För allmänna arbetsbelastningar och typiska operationer. |
| Stort | 16 | 128 | För minnesintensiva uppgifter eller stora databearbetningsjobb. |
| X-Large | 32 | 256 | För de mest krävande Spark-arbetsbelastningarna som behöver betydande resurser. |
| XX-Large | 64 | 512 | För de största Spark-arbetsbelastningarna som kräver högsta beräkning och minne per nod. |
Relaterat innehåll
- Läs mer i den offentliga dokumentationen för Apache Spark .
- Kom igång med administrationsinställningarna för Spark-arbetsytor i Microsoft Fabric.
- Hantera bibliotek i Fabric-miljöer