Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här artikeln visar hur du använder NVIDIA GPU-arbetsbelastningar med Azure Red Hat OpenShift.
Förutsättningar
- OpenShift CLI
- jq, moreutils och gettext-paket
- Azure Red Hat OpenShift 4.10
Om du behöver installera ett kluster kan du läsa Självstudie: Skapa ett Azure Red Hat OpenShift 4-kluster. kluster måste vara version 4.10.x eller senare.
Anmärkning
Från och med 4.10 är det inte längre nödvändigt att konfigurera rättigheter för att använda NVIDIA-operatorn. Detta har avsevärt förenklat konfigurationen av klustret för GPU-arbetsbelastningar.
Linux:
sudo dnf install jq moreutils gettext
macOS
brew install jq moreutils gettext
Begär GPU-kvot
Alla GPU-kvoter i Azure är 0 som standard. Du måste logga in på Azure Portal och begära GPU-kvot. På grund av konkurrens om GPU-arbetare kan du behöva etablera ett kluster i en region där du faktiskt kan reservera GPU.
stöder följande GPU-arbetare:
- NC4as T4 v3
- NC6s v3
- NC8as T4 v3
- NC12s v3
- NC16as T4 v3
- NC24s v3
- NC24rs v3
- NC64as T4 v3
Följande instanser stöds också i ytterligare MachineSets:
- Standard_ND96asr_v4
- NC24ads_A100_v4
- NC48ads_A100_v4
- NC96ads_A100_v4
- ND96amsr_A100_v4
Anmärkning
När du begär kvot bör du komma ihåg att Azure är per kärna. Om du vill begära en enskild NC4as T4 v3-nod måste du begära kvot i grupper om 4. Om du vill begära en NC16as T4 v3 måste du begära en kvot på 16.
Logga in på Azure-portalen.
Ange kvoter i sökrutan och välj sedan Beräkning.
I sökrutan anger du NCAsv3_T4, markerar kryssrutan för den region som klustret finns i och väljer sedan Begär kvotökning.
Konfigurera kvot.

Logga in på klustret
Logga in på OpenShift med ett användarkonto med klusteradministratörsbehörighet. I exemplet nedan används ett konto med namnet kubadmin:
oc login <apiserver> -u kubeadmin -p <kubeadminpass>
Pull-hemlighet (villkorsstyrd)
Uppdatera pull-hemligheten så att du kan installera operatorer och ansluta till cloud.redhat.com.
Anmärkning
Hoppa över det här steget om du redan har återskapat en fullständig pull-hemlighet med cloud.redhat.com aktiverat.
Logga in på cloud.redhat.com.
Navigera till https://cloud.redhat.com/openshift/install/azure/aro-provisioned.
Välj Hämta pull-hemlighet och spara pull-hemligheten som
pull-secret.txt.Viktigt!
Återstående steg i det här avsnittet måste köras i samma arbetskatalog som
pull-secret.txt.Exportera den befintliga pull-hemligheten.
oc get secret pull-secret -n openshift-config -o json | jq -r '.data.".dockerconfigjson"' | base64 --decode > export-pull.jsonSammanfoga den nedladdade pull-hemligheten med systemhämtningshemligheten för att lägga till
cloud.redhat.com.jq -s '.[0] * .[1]' export-pull.json pull-secret.txt | tr -d "\n\r" > new-pull-secret.jsonLadda upp den nya hemliga filen.
oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=new-pull-secret.jsonDu kan behöva vänta ungefär 1 timme på att allt ska synkroniseras med cloud.redhat.com.
Ta bort hemligheter.
rm pull-secret.txt export-pull.json new-pull-secret.json
GPU-datoruppsättning
använder Kubernetes MachineSet för att skapa datoruppsättningar. I proceduren nedan beskrivs hur du exporterar den första datoruppsättningen i ett kluster och använder den som mall för att skapa en enda GPU-dator.
Visa befintliga datoruppsättningar.
För att underlätta installationen använder det här exemplet den första datoruppsättningen som den som ska klonas för att skapa en ny GPU-datoruppsättning.
MACHINESET=$(oc get machineset -n openshift-machine-api -o=jsonpath='{.items[0]}' | jq -r '[.metadata.name] | @tsv')Spara en kopia av exempeldatoruppsättningen.
oc get machineset -n openshift-machine-api $MACHINESET -o json > gpu_machineset.jsonÄndra fältet
.metadata.nametill ett nytt unikt namn.jq '.metadata.name = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.jsonSe till att
spec.replicasmatchar det önskade antalet repliker för datoruppsättningen.jq '.spec.replicas = 1' gpu_machineset.json| sponge gpu_machineset.jsonÄndra fältet
.spec.selector.matchLabels.machine.openshift.io/cluster-api-machinesetså att det matchar fältet.metadata.name.jq '.spec.selector.matchLabels."machine.openshift.io/cluster-api-machineset" = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.jsonÄndra för
.spec.template.metadata.labels.machine.openshift.io/cluster-api-machinesetatt matcha fältet.metadata.name.jq '.spec.template.metadata.labels."machine.openshift.io/cluster-api-machineset" = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.jsonspec.template.spec.providerSpec.value.vmSizeÄndra för att matcha önskad GPU-instanstyp från Azure.Den dator som används i det här exemplet är Standard_NC4as_T4_v3.
jq '.spec.template.spec.providerSpec.value.vmSize = "Standard_NC4as_T4_v3"' gpu_machineset.json | sponge gpu_machineset.jsonspec.template.spec.providerSpec.value.zoneÄndra för att matcha önskad zon från Azure.jq '.spec.template.spec.providerSpec.value.zone = "1"' gpu_machineset.json | sponge gpu_machineset.json.statusTa bort avsnittet i yaml-filen.jq 'del(.status)' gpu_machineset.json | sponge gpu_machineset.jsonVerifiera andra data i yaml-filen.
Kontrollera att rätt SKU har angetts
Beroende på vilken avbildning som används för datoruppsättningen måste båda värdena för image.sku och image.version anges i enlighet med detta. Detta är för att säkerställa om virtuella datorer av generation 1 eller 2 för Hyper-V används. Mer information finns i här.
Exempel:
Om du använder Standard_NC4as_T4_v3stöds båda versionerna. Som nämnts i Funktionsstöd. I det här fallet krävs inga ändringar.
Om du använder Standard_NC24ads_A100_v4stöds endast virtuell generation 2-dator.
I det här fallet image.sku måste värdet följa motsvarande v2 version av avbildningen som motsvarar klustrets ursprungliga image.sku. I det här exemplet blir v410-v2värdet .
Detta kan hittas med hjälp av följande kommando:
az vm image list --architecture x64 -o table --all --offer aro4 --publisher azureopenshift
Filtered output:
SKU VERSION
------- ---------------
v410-v2 410.84.20220125
aro_410 410.84.20220125
Om klustret skapades med bas-SKU-avbildningen aro_410och samma värde sparas i datoruppsättningen misslyckas det med följande fel:
failure sending request for machine myworkernode: cannot create vm: compute.VirtualMachinesClient#CreateOrUpdate: Failure sending request: StatusCode=400 -- Original Error: Code="BadRequest" Message="The selected VM size 'Standard_NC24ads_A100_v4' cannot boot Hypervisor Generation '1'.
Skapa GPU-datoruppsättning
Använd följande steg för att skapa den nya GPU-datorn. Det kan ta 10–15 minuter att etablera en ny GPU-dator. Om det här steget misslyckas loggar du in på Azure Portal och ser till att det inte finns några tillgänglighetsproblem. Det gör du genom att gå till Virtuella datorer och söka efter arbetsnamnet som du skapade tidigare för att se status för virtuella datorer.
Skapa GPU-datoruppsättningen.
oc create -f gpu_machineset.jsonDet tar några minuter att slutföra det här kommandot.
Verifiera GPU-datoruppsättningen.
Datorer bör distribueras. Du kan visa status för datoruppsättningen med följande kommandon:
oc get machineset -n openshift-machine-api oc get machine -n openshift-machine-apiNär datorerna har etablerats (vilket kan ta 5–15 minuter) visas datorerna som noder i nodlistan:
oc get nodesDu bör se en nod med namnet
nvidia-worker-southcentralus1som skapades tidigare.
Installera NVIDIA GPU-operatör
I det här avsnittet beskrivs hur du skapar nvidia-gpu-operator namnområdet, konfigurerar operatorgruppen och installerar NVIDIA GPU-operatorn.
Skapa NVIDIA-namnrymd.
cat <<EOF | oc apply -f - apiVersion: v1 kind: Namespace metadata: name: nvidia-gpu-operator EOFSkapa operatorgrupp.
cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: nvidia-gpu-operator-group namespace: nvidia-gpu-operator spec: targetNamespaces: - nvidia-gpu-operator EOFHämta den senaste NVIDIA-kanalen med följande kommando:
CHANNEL=$(oc get packagemanifest gpu-operator-certified -n openshift-marketplace -o jsonpath='{.status.defaultChannel}')
Anmärkning
Om klustret skapades utan att tillhandahålla pull-hemligheten innehåller klustret inte exempel eller operatorer från Red Hat eller från certifierade partner. Detta resulterar i följande felmeddelande:
Fel från servern (NotFound): packagemanifests.packages.operators.coreos.com "gpu-operator-certified" hittades inte.
Följ den här vägledningen om du vill lägga till din Red Hat-pullhemlighet i ett Azure Red Hat OpenShift-kluster.
Hämta det senaste NVIDIA-paketet med följande kommando:
PACKAGE=$(oc get packagemanifests/gpu-operator-certified -n openshift-marketplace -ojson | jq -r '.status.channels[] | select(.name == "'$CHANNEL'") | .currentCSV')Skapa prenumeration.
envsubst <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: gpu-operator-certified namespace: nvidia-gpu-operator spec: channel: "$CHANNEL" installPlanApproval: Automatic name: gpu-operator-certified source: certified-operators sourceNamespace: openshift-marketplace startingCSV: "$PACKAGE" EOFVänta tills operatorn har slutfört installationen.
Fortsätt inte förrän du har kontrollerat att operatören har slutfört installationen. Se också till att GPU-arbetaren är online.

Installera nodfunktionens identifieringsoperator
Operatorn för identifiering av nodfunktioner identifierar GPU:n på dina noder och etiketterar noderna på rätt sätt så att du kan rikta dem mot arbetsbelastningar.
Det här exemplet installerar NFD-operatorn i openshift-ndf namnområdet och skapar "prenumerationen" som är konfigurationen för NFD.
Officiell dokumentation för installation av nodfunktionsidentifieringsoperator.
Ställ in
Namespace.cat <<EOF | oc apply -f - apiVersion: v1 kind: Namespace metadata: name: openshift-nfd EOFSkapa
OperatorGroup.cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: generateName: openshift-nfd- name: openshift-nfd namespace: openshift-nfd EOFSkapa
Subscription.cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: nfd namespace: openshift-nfd spec: channel: "stable" installPlanApproval: Automatic name: nfd source: redhat-operators sourceNamespace: openshift-marketplace EOFVänta tills node feature discovery (Nodfunktionsidentifiering) har slutfört installationen.
Du kan logga in på OpenShift-konsolen för att visa operatorer eller bara vänta några minuter. Det går inte att vänta tills operatorn har installerats, vilket resulterar i ett fel i nästa steg.
Skapa NFD-instans.
cat <<EOF | oc apply -f - kind: NodeFeatureDiscovery apiVersion: nfd.openshift.io/v1 metadata: name: nfd-instance namespace: openshift-nfd spec: customConfig: configData: | # - name: "more.kernel.features" # matchOn: # - loadedKMod: ["example_kmod3"] # - name: "more.features.by.nodename" # value: customValue # matchOn: # - nodename: ["special-.*-node-.*"] operand: image: >- registry.redhat.io/openshift4/ose-node-feature-discovery@sha256:07658ef3df4b264b02396e67af813a52ba416b47ab6e1d2d08025a350ccd2b7b servicePort: 12000 workerConfig: configData: | core: # labelWhiteList: # noPublish: false sleepInterval: 60s # sources: [all] # klog: # addDirHeader: false # alsologtostderr: false # logBacktraceAt: # logtostderr: true # skipHeaders: false # stderrthreshold: 2 # v: 0 # vmodule: ## NOTE: the following options are not dynamically run-time ## configurable and require a nfd-worker restart to take effect ## after being changed # logDir: # logFile: # logFileMaxSize: 1800 # skipLogHeaders: false sources: # cpu: # cpuid: ## NOTE: attributeWhitelist has priority over attributeBlacklist # attributeBlacklist: # - "BMI1" # - "BMI2" # - "CLMUL" # - "CMOV" # - "CX16" # - "ERMS" # - "F16C" # - "HTT" # - "LZCNT" # - "MMX" # - "MMXEXT" # - "NX" # - "POPCNT" # - "RDRAND" # - "RDSEED" # - "RDTSCP" # - "SGX" # - "SSE" # - "SSE2" # - "SSE3" # - "SSE4.1" # - "SSE4.2" # - "SSSE3" # attributeWhitelist: # kernel: # kconfigFile: "/path/to/kconfig" # configOpts: # - "NO_HZ" # - "X86" # - "DMI" pci: deviceClassWhitelist: - "0200" - "03" - "12" deviceLabelFields: # - "class" - "vendor" # - "device" # - "subsystem_vendor" # - "subsystem_device" # usb: # deviceClassWhitelist: # - "0e" # - "ef" # - "fe" # - "ff" # deviceLabelFields: # - "class" # - "vendor" # - "device" # custom: # - name: "my.kernel.feature" # matchOn: # - loadedKMod: ["example_kmod1", "example_kmod2"] # - name: "my.pci.feature" # matchOn: # - pciId: # class: ["0200"] # vendor: ["15b3"] # device: ["1014", "1017"] # - pciId : # vendor: ["8086"] # device: ["1000", "1100"] # - name: "my.usb.feature" # matchOn: # - usbId: # class: ["ff"] # vendor: ["03e7"] # device: ["2485"] # - usbId: # class: ["fe"] # vendor: ["1a6e"] # device: ["089a"] # - name: "my.combined.feature" # matchOn: # - pciId: # vendor: ["15b3"] # device: ["1014", "1017"] # loadedKMod : ["vendor_kmod1", "vendor_kmod2"] EOFKontrollera att NFD är klart.
Statusen för den här operatorn ska visas som Tillgänglig.

Tillämpa NVIDIA-klusterkonfiguration
I det här avsnittet beskrivs hur du använder NVIDIA-klusterkonfigurationen. Läs NVIDIA-dokumentationen om hur du anpassar detta om du har egna privata lagringsplatser eller specifika inställningar. Den här processen kan ta flera minuter att slutföra.
Använd klusterkonfiguration.
cat <<EOF | oc apply -f - apiVersion: nvidia.com/v1 kind: ClusterPolicy metadata: name: gpu-cluster-policy spec: migManager: enabled: true operator: defaultRuntime: crio initContainer: {} runtimeClass: nvidia deployGFD: true dcgm: enabled: true gfd: {} dcgmExporter: config: name: '' driver: licensingConfig: nlsEnabled: false configMapName: '' certConfig: name: '' kernelModuleConfig: name: '' repoConfig: configMapName: '' virtualTopology: config: '' enabled: true use_ocp_driver_toolkit: true devicePlugin: {} mig: strategy: single validator: plugin: env: - name: WITH_WORKLOAD value: 'true' nodeStatusExporter: enabled: true daemonsets: {} toolkit: enabled: true EOFVerifiera klusterprincipen.
Logga in på OpenShift-konsolen och bläddra till operatorer. Kontrollera att du är i
nvidia-gpu-operatornamnområdet. Det borde ståState: Ready once everything is complete.
Verifiera GPU
Det kan ta lite tid för NVIDIA-operatören och NFD att helt installera och identifiera datorerna själv. Kör följande kommandon för att verifiera att allt körs som förväntat:
Kontrollera att NFD kan se dina GPU:er.
oc describe node | egrep 'Roles|pci-10de' | grep -v masterUtdata bör se ut ungefär så här:
Roles: worker feature.node.kubernetes.io/pci-10de.present=trueVerifiera nodetiketter.
Du kan se nodetiketterna genom att logga in på OpenShift-konsolen – Compute –>> Nodes –> nvidia-worker-southcentralus1-. Du bör se flera NVIDIA GPU-etiketter och pci-10de-enheten ovan.
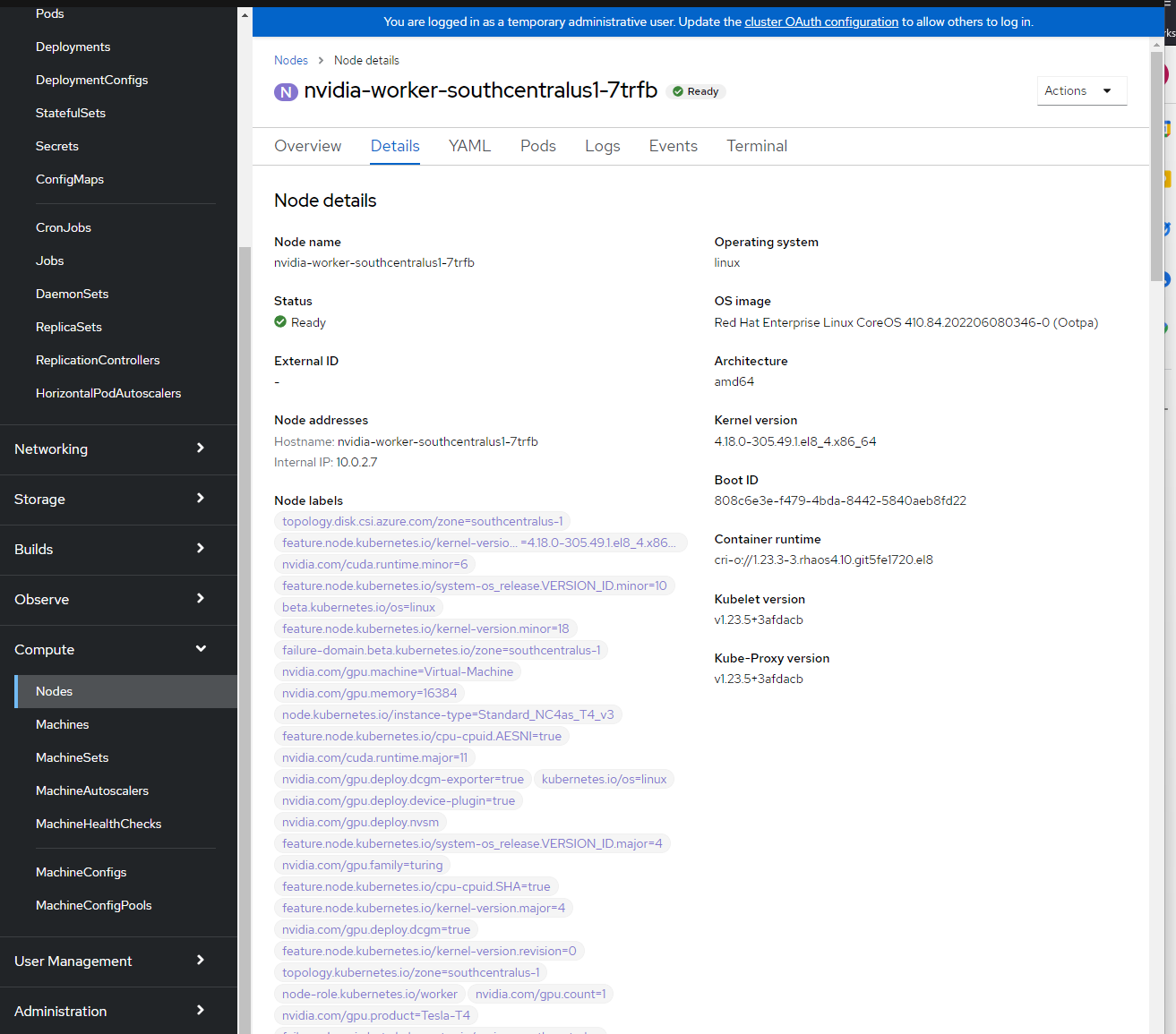
NVIDIA SMI-verktygsverifiering.
oc project nvidia-gpu-operator for i in $(oc get pod -lopenshift.driver-toolkit=true --no-headers |awk '{print $1}'); do echo $i; oc exec -it $i -- nvidia-smi ; echo -e '\n' ; doneDu bör se utdata som visar de GPU:er som är tillgängliga på värden, till exempel skärmbilden i det här exemplet. (Varierar beroende på GPU-arbetstyp)

Skapa podd för att köra en GPU-arbetsbelastning
oc project nvidia-gpu-operator cat <<EOF | oc apply -f - apiVersion: v1 kind: Pod metadata: name: cuda-vector-add spec: restartPolicy: OnFailure containers: - name: cuda-vector-add image: "quay.io/giantswarm/nvidia-gpu-demo:latest" resources: limits: nvidia.com/gpu: 1 nodeSelector: nvidia.com/gpu.present: true EOFVisa loggar.
oc logs cuda-vector-add --tail=-1
Anmärkning
Om du får ett fel Error from server (BadRequest): container "cuda-vector-add" in pod "cuda-vector-add" is waiting to start: ContainerCreatingkan du prova att köra oc delete pod cuda-vector-add och sedan köra create-instruktionen ovan igen.
Utdata bör likna följande (beroende på GPU):
[Vector addition of 5000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
Om det lyckas kan podden tas bort:
oc delete pod cuda-vector-add