Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Viktigt!
Den här funktionen finns i Beta. Arbetsyteadministratörer kan styra åtkomsten till den här funktionen från sidan Förhandsversioner . Se Hantera Azure Databricks förhandsversioner.
Mosaic AI Vector Search ger inbyggd utvärdering av hämtningskvalitet som mäter och jämför relevansen av olika sökstrategier för dina data. Du kan automatiskt generera utvärderingsfrågor från dina dokument, köra flera hämtningsstrategier och generera en detaljerad rapport.
Requirements
Ett hanterat deltasynkroniseringsvektorsökindex. Se Skapa slutpunkter och index för vektorsökning.
behörigheter
Utvärderingsjobbet och resultattavlan ärver behörigheter för Unity Catalog från vektorsökningsindexet. Alla användare som har tillgång till att göra sökningar i indexet kan starta en utvärderingskörning och visa resultatpanelen. Användaren som startar utvärderingskörningen är jobbets ägare, inte indexets ägare.
Så här fungerar kvalitetsutvärdering av vektorsökningshämtning
Utvärderingen kör en pipeline i fyra steg på dina data:
- Generera frågor: Systemet tar exempel på dokument från källtabellen och använder en LLM för att generera realistiska sökfrågor. Den genererar en blandning av frågor på naturligt språk och nyckelordsfrågor.
- Sök mellan strategier: Varje genererad fråga körs mot ditt index med hjälp av flera hämtningsstrategier, inklusive ANN, hybrid och fulltext. Varje strategi utvärderas också med och utan reranker. Den här metoden jämför strategier sida vid sida på samma frågeuppsättning. Mer information om varje hämtningsstrategi finns i Hämtningsalgoritmer.
- Poängrelevans: En LLM-domare utvärderar varje fråga och hämtade dokumentpar på en 4-poängs relevansskala.
- Beräkna mått och analysera: Systemet beräknar hämtningskvalitetsmått med konfidensintervall. Resultaten sparas så att du kan visa dem senare eller jämföra mellan utvärderingskörningar.
Starta en utvärdering av kvaliteten för hämtning
Starta processen genom att klicka på Utvärdera sökkvalitet på sidan för vektorsökningsindex. Ingen konfiguration krävs eftersom standardvärdena fylls i i förväg baserat på dina indexmetadata.
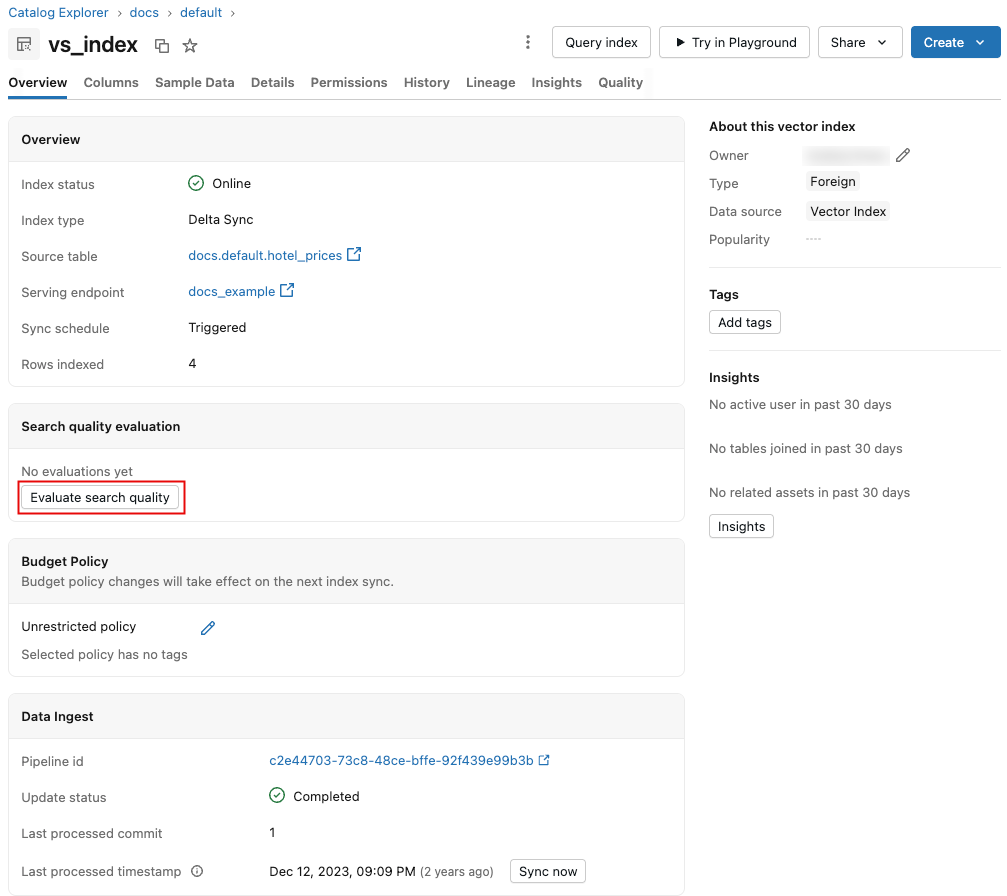
När körningen är klar klickar du på Visa resultat för att visa resultatinstrumentpanelen. En översikt över instrumentpanelen finns i Resultatinstrumentpanelen.

Om du vill initiera en ny utvärdering när som helst klickar du på Starta ny utvärdering.
Resultatdashboard
Instrumentpanelen visar resultatet av utvärderingskörningarna. Använd nedrullningsmenyn Välj körning för att välja vilken körning som ska visas.

Högst upp på instrumentpanelen finns tre sammanfattningsindikatorer: den bästa DCG@10 poäng för alla frågetyper, den rekommenderade frågetyp som uppnådde den och antalet frågor som utvärderades.
Se Varför Databricks rekommenderar DCG@10.
Under sammanfattningsindikatorerna visar instrumentpanelen ett stapeldiagram som jämför DCG@10 poäng för varje frågetyp, med och utan att använda rerankern. Bredvid stapeldiagrammet finns två tabeller som visar DCG@10 och genomsnittlig relevans för varje frågetyp, med och utan reranker.
Här följer ett linjediagram som visar hur genomsnittlig relevans ändras mellan resultatpositioner för varje frågetyp.
Instrumentpanelen visar också de frågor som har högst och lägst prestanda efter genomsnittlig relevanspoäng, en tabell som jämför bas- och rerankerprestanda för varje frågetyp, en tabell med misslyckade frågor (frågor där det översta resultatet fick 0 (irrelevant)) och ett linjediagram som visar ett valt mått över utvärderingskörningar över tid, efter frågemått.
Relevansbedömning
Utvärdering av hämtningskvalitet använder en LLM som domare för att poängsätta varje fråga och hämtat dokumentpar på en graderad relevansskala med 4 poäng.
| Poäng | Etikett | Beskrivning | Exempel |
|---|---|---|---|
| 3 | Mycket relevant | Dokumentet besvarar frågan direkt eller ger exakt den information som söks | Fråga: "Hur beräknar jag området för en rektangel?" Dokumentet förklarar längden × breddformeln |
| 2 | Relevant | Dokumentet är relaterat och ger användbar information, men kanske inte helt besvarar frågan | Fråga: "var finns routningsnumret vid en kontroll?" Dokumentet säger "skrivs ut längst ned på en check" (delvis slutfört) |
| 1 | Delvis relevant | Dokumentet nämner ämnet men ger inte användbar information för frågan | Fråga: "Hur beräknar du området för en rektangel?" I dokumentet diskuteras endast arean av rektanglar i allmänna termer |
| 0 | Inte relevant | Dokumentet är inte relaterat till frågan, eller så matchar inte dokumentspråket frågespråket | Fråga på engelska Dokumentet svarar korrekt men på franska |
Jämfört med en binär relevant/inte relevant skala samlar den graderade skalan in viktiga distinktioner. Ett dokument som till exempel svarar direkt på en fråga (poäng 3) skiljer sig meningsfullt från ett dokument som bara berör ämnet (poäng 1). Den här detaljnivån flödar igenom till måtten, särskilt DCG, vilket betonar resultat av högre kvalitet mer.
Alla mått omfattar 95% konfidensintervall som beräknas för värden per fråga, så att du kan bedöma om skillnaderna mellan strategier är statistiskt meningsfulla.
Återhämtningsmått
Längst ned på instrumentpanelen kan du visa ett valt mått över tid. Välj det mått som ska visas på den nedrullningsbara menyn Välj mått .

I det här avsnittet beskrivs tillgängliga mått.
DCG@k – rabatterad ackumulerad vinst
DCG@10 fångar både hur relevanta resultat är och var de visas i rangordningen med hjälp av den fullständiga relevansskalan 0–3. Databricks rekommenderar att du använder DCG@10 som det primära måttet för att utvärdera den övergripande hämtningskvaliteten.
- Vad den mäter: Den totala nyttan av topp-10-resultaten, viktat efter position. Resultat med högre rankning bidrar mer än resultat med lägre rankning.
- Så här fungerar det: Varje resultats relevanspoäng viktas av en logaritmisk rabatt baserat på dess position. Det första resultatet bidrar med sin fulla relevans, medan lägre rankade resultat bidrar progressivt mindre.
- Intervall: 0 till det teoretiska maxvärdet som visas i följande tabell. Högre är bättre.
Teoretiska högsta DCG-värden, om varje resultat får poängen 3:
| k | Teoretisk max-DCG |
|---|---|
| 1 | 3.00 |
| 3 | 6.39 |
| 5 | 8.85 |
| 10 | 13.63 |
| 20 | 21.12 |
För att sätta dessa tal i perspektiv: om alla 10 resultat har relevansen 2 (på en skala från 0–3) är DCG@10 13,6. I det här scenariot är en 1-poängs DCG@10 vinst en mycket betydande (+7% relativ) förbättring. Du kan se det som ungefär ett resultat på sidan som blir märkbart bättre, viktat mot toppen.
NDCG@k – Normaliserad rabatterad ackumulerad vinst
- Vad den mäter: Hur väl resultaten sorteras i förhållande till bästa möjliga ordning. NDCG normaliserar DCG genom att dividera den med den ideala DCG:n (DCG om resultaten sorterades i fallande relevansordning).
- Intervall: 0 till 1. Poängen 1,0 innebär att resultaten är i perfekt ordning.
- När du ska använda: När du vill veta om systemet rangordnar resultat korrekt, oberoende av det totala antalet relevanta dokument som är tillgängliga. Se Varför DCG@10 är det rekommenderade primära måttet för en detaljerad jämförelse.
Recall@k
- Vad den mäter: Bråkdelen av kända relevanta dokument som visas i top-k-resultaten.
- Intervall: 0 till 1. Poängen 1,0 innebär att alla kända relevanta dokument hämtades.
- När du ska använda: När fullständighet är viktigt, till exempel i RAG-program där det saknas ett relevant dokument, genererar LLM ett ofullständigt svar.
Precision@k
- Vad den mäter: Bråkdelen av top-k-resultat som är relevanta (relevanspoäng >= 2).
- Intervall: 0 till 1. Poängen 1,0 innebär att varje resultat i topp k är relevant.
- När du ska använda: När resultatkvaliteten är viktigare än fullständighet, till exempel i sökgränssnitt där irrelevanta resultat kan påverka användarnas förtroende negativt.
Genomsnittlig relevanspoäng
- Vad den mäter: Den genomsnittliga LLM-bedömda relevanspoäng för alla fråge- och resultatpar.
- Intervall: 0 till 3. Högre är bättre.
- När du ska använda: Som en ögonblicksbild av snabbkvalitet.
Relevansfördelning
-
Vad den mäter: Procentandelen resultat i varje relevanskategori:
- Mycket relevant %: Resultat med poäng 3 (direkta svar).
- Relevant+ %: Resultatpoäng 2 eller högre (användbart).
- Inte relevant %: Resultatpoäng 0 eller 1 (inte användbart).
- När du ska använda: För att förstå formen på kvalitetsfördelningen. Två strategier kan ha samma genomsnittliga poäng men mycket olika fördelningar. Ett bimodalt distributionsmönster (många treor och många nollor) kan till exempel tyda på att ett frågemönster inte hittas väl och behöver uppmärksamhet.
MRR – genomsnittlig ömsesidig rangordning
- Vad den mäter: Hur snabbt användarna hittar det första relevanta resultatet. MRR är medelvärdet av 1/rankning mellan frågor, där rangordning är positionen för det första relevanta resultatet (poäng >= 2).
- Intervall: 0 till 1. Poängen 1,0 innebär att det första resultatet alltid är relevant.
- När du ska använda: När det högsta resultatet är viktigast, till exempel i frågesvarssystem.
MAP@k – Medelgenomsnittlig precision
- Vad den mäter: Kvaliteten på rangordningen över alla relevanta resultat, inte bara den första. MAP beräknar precision vid varje relevant resultatposition och sedan medelvärden.
- Intervall: 0 till 1. Högre värden anger att relevanta dokument konsekvent rangordnas nära toppen.
- När du ska använda: När du behöver ett enda tal som samlar in övergripande rangordningskvalitet i alla relevanta dokument.
Varför DCG@10 är det rekommenderade primära måttet
DCG@10 ger den mest kompletta bilden av hämtningskvaliteten för de flesta program:
- Graderad relevans fångar nyanser: Binära mått som precision behandlar alla relevanta dokument lika. Ett dokument som perfekt svarar på frågan (poäng 3) räknas som ett som vagt nämner ämnet (poäng 1). DCG använder hela 0–3-relevansskalan, så ett resultat som poängsatts 3 bidrar betydligt mer än ett resultat som fick 1.
- Position spelar roll: Användarna tittar först på de bästa resultaten. DCG tillämpar en logaritmisk rabatt, så att resultat vid position 1 räknar mycket mer än resultaten vid position 10. Det första resultatet bidrar med sin fulla relevanspoäng, medan det tionde resultatets bidrag divideras med log₂(11) ≈ 3,46.
- Absolut nytta visar vad normaliserade metrik missar: Tänk på exemplet som visas i följande tabell. Båda resultatuppsättningarna uppnår en perfekt NDCG på 1,00 eftersom var och en har resultat i idealisk fallande ordning. Resultatuppsättning B ger dock nästan dubbelt så mycket som det totala värdet (DCG 8,02 jämfört med 4,26) eftersom varje resultat är användbart. NDCG kan inte skilja mellan "perfekt ranking av 2 bra resultat bland 3 irrelevanta" och "perfekt ranking av 5 bra resultat." DCG svarar på frågan: "Hur mycket användbar information fick användaren faktiskt?"
Mer information om DCG och NDCG finns i Rabatterad kumulativ vinst.
| Results | Position 1 | Position 2 | Position 3 | Position 4 | Position 5 | NDCG@5 | DCG@5 |
|---|---|---|---|---|---|---|---|
| Resultatuppsättning A | 3 | 2 | 0 | 0 | 0 | 1,00 | 4.26 |
| Resultatuppsättning B | 3 | 3 | 3 | 2 | 2 | 1,00 | 8.02 |
Inget enskilt mått berättar hela historien. Använd den fullständiga måttsviten för en fullständig bild och välj det mått som bäst matchar programmets kvalitetskrav.
Vanliga scenarier
I följande tabell beskrivs vanliga utvärderingsresultatmönster, vad de betyder och hur du hanterar dem:
| Mönster | Vad det innebär | Föreslagna åtgärder |
|---|---|---|
| Hybrid betydligt bättre än ANN | Frågor drar nytta av nyckelordsmatchning. | Använd hybridsökning i produktion. |
| ANN ungefär lika med hybrid | Nyckelord lägger inte till värde för dina data. | Båda strategierna fungerar. ANN är enklare. |
| Fulltext betydligt bättre än ANN | Inbäddningar kanske inte fångar din domän väl. | Överväg att finjustera inbäddningsmodellen eller använda fulltextsökning. |
| Reranker förbättrar mått avsevärt | Cross-encoder ger ett meningsfullt kvalitetslyft. | Aktivera reranker om svarstidsbudgeten tillåter det. |
| Breda konfidensintervall | Det finns inte tillräckligt med frågor för tillförlitlig jämförelse. | Öka antalet utvärderingsfrågor. |
| Alla strategier får låga poäng | Problem med datakvalitet eller relevans. | I kvalitetsguiden för hämtning av vektorsökning finns en stegvis guide för att förbättra hämtningskvaliteten. |