Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
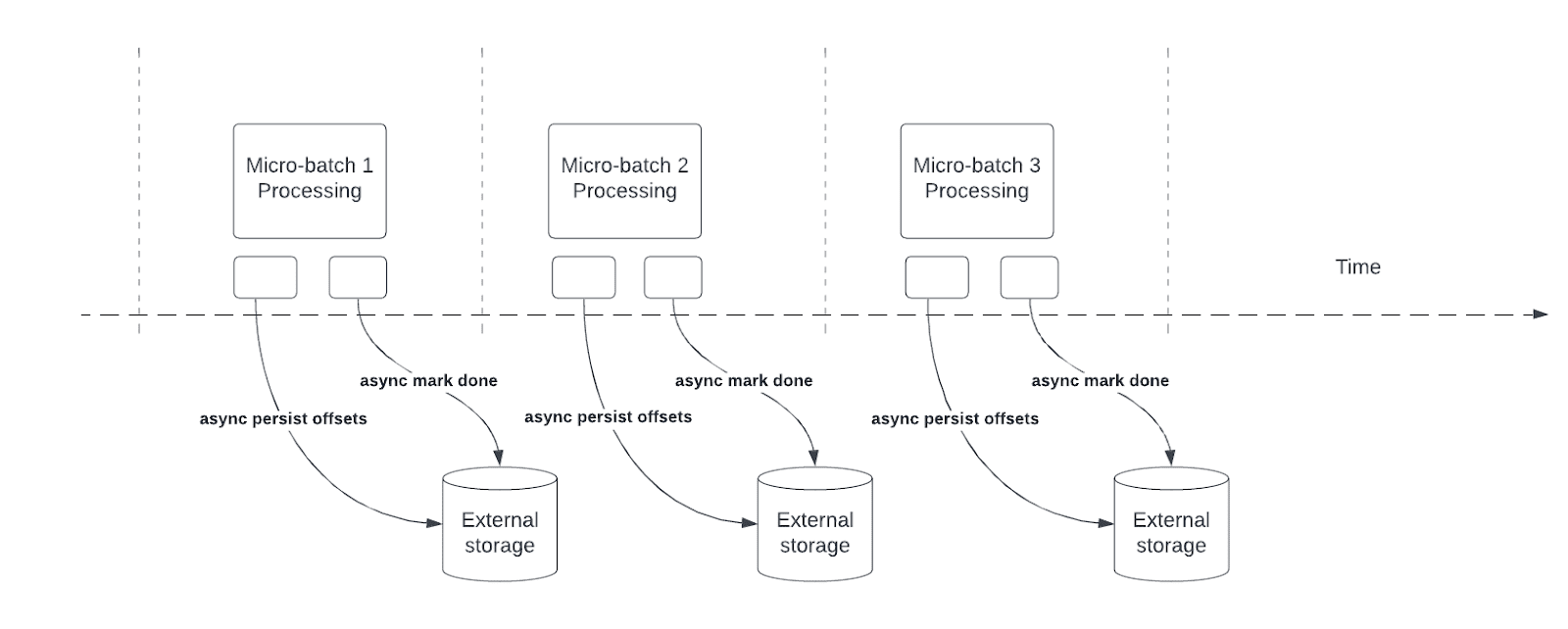
Asynkron förloppsspårning minskar svarstiden för pipelines för strukturerad direktuppspelning genom att göra det möjligt för frågor att asynkront uppdatera kontrollpunktsförloppet och bearbeta data i varje mikrobatch.
Vid frågebearbetningen bevarar och hanterar Structured Streaming offsets för att mäta frågans framsteg i offsetLog och commitLog i varje mikro-batch. Utan asynkron förloppsspårning påverkar förskjutningshanteringsåtgärder direkt bearbetningens svarstid eftersom databearbetningen inte kan fortsätta förrän de har slutförts.
Not
Asynkron förloppsspårning är inte kompatibel med Trigger.once eller Trigger.availableNow utlösare. Om aktiverat, Structured Streaming-frågeställningar med Trigger.once eller Trigger.availableNow misslyckas.
Konfigurationsalternativ
| Alternativ | Förvalt | Beskrivning |
|---|---|---|
asyncProgressTrackingEnabled |
false |
Om du vill aktivera asynkron förloppsspårning. |
asyncProgressTrackingCheckpointIntervalMs |
1000 |
Intervallet i millisekunder mellan skrivningar för förskjutningar och slutförande commiteringar. |
Aktivera asynkron förloppsspårning
Om du vill aktivera asynkron förloppsspårning anger du asyncProgressTrackingEnabled till true:
Python
stream = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
)
query = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
)
Scala
val stream = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
Förbättra dataflödet med kontrollpunktsfrekvens
Standardfrekvensen för kontrollpunkter för 1000 millisekunder har bra dataflöde för de flesta frågor. När offsethanteringsåtgärder sker snabbare än vad asynkron förloppsspårning kan bearbeta dem, uppstår en eftersläpning av offsethanteringsåtgärder. För att förhindra att eftersläpningen växer ytterligare kan asynkron förloppsspårning blockera eller sakta ner databearbetningen, vilket potentiellt kan urholka de förväntade svarstidsfördelarna.
I det här scenariot rekommenderar Databricks att du ökar kontrollpunktsintervallet:
Python
query = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "5000")
.start()
)
Scala
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "5000")
.start()
Not
Tiden för återhämtning från fel ökar med intervalltiden för uppsamlingspunkter. Vid fel måste en pipeline bearbeta alla data igen sedan den tidigare lyckade kontrollpunkten. Innan du gör den här ändringen i produktionen bör du överväga kompromissen mellan lägre svarstid under regelbunden bearbetning jämfört med återställningstiden i händelse av fel.
Inaktivera asynkron förloppsspårning
När asynkron förloppsspårning är aktiverat garanterar strömmen inte kontrollpunktsförlopp för varje batch. Du måste skapa en kontrollpunkt för framsteg innan du kan inaktivera den här funktionen.
Om du vill inaktivera följer du dessa steg:
Bearbeta minst två mikrobatch med
asyncProgressTrackingEnabledinställt påtrueochasyncProgressTrackingCheckpointIntervalMsinställt på0:Python
query = (stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "true") .option("asyncProgressTrackingCheckpointIntervalMs", "0") .start() )Scala
val query = stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "true") .option("asyncProgressTrackingCheckpointIntervalMs", "0") .start()Stoppa frågan:
Python
query.stop()Scala
query.stop()Inaktivera asynkron förloppsspårning och starta om frågan:
Python
query = (stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "false") .start() )Scala
val query = stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "false") .start()
Om du inaktiverar asynkron förloppsspårning utan att följa stegen ovan kan följande fel uppstå:
java.lang.IllegalStateException: batch x doesn't exist
I drivrutinsloggarna kan följande fel visas:
The offset log for batch x doesn't exist, which is required to restart the query from the latest batch x from the offset log. Please ensure there are two subsequent offset logs available for the latest batch via manually deleting the offset file(s). Please also ensure the latest batch for commit log is equal or one batch earlier than the latest batch for offset log.
Limitations
- För Kafka-mottagare stöder asynkron förloppsspårning endast tillståndslösa pipelines.
- Asynkron förloppsspårning garanterar inte bearbetning exakt en gång från slutpunkt till slutpunkt eftersom förskjutningsintervall för en batch kan ändras vid fel. Vissa mottagare, till exempel Kafka, ger aldrig exakt-en-gång-garantier.