Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Med minne kan AI-agenter komma ihåg information från tidigare i konversationen eller från tidigare konversationer. På så sätt kan agenter tillhandahålla sammanhangsmedvetna svar och skapa anpassade upplevelser över tid. Använd Databricks Lakebase, en fullständigt hanterad Postgres OLTP-databas, för att hantera konversationstillstånd och historik.
Kravspecifikation
- Aktivera Databricks-appar på din arbetsyta. Se Konfigurera din Databricks Apps-arbetsyta och utvecklingsmiljö.
- En Lakebase-instans finns i Skapa och hantera en databasinstans.
Kortsiktigt jämfört med långtidsminne
Kortsiktigt minne fångar kontext i en enda konversationssession medan långtidsminnet extraherar och lagrar viktig information i flera konversationer. Du kan skapa din agent med någon av eller båda typerna av minne.
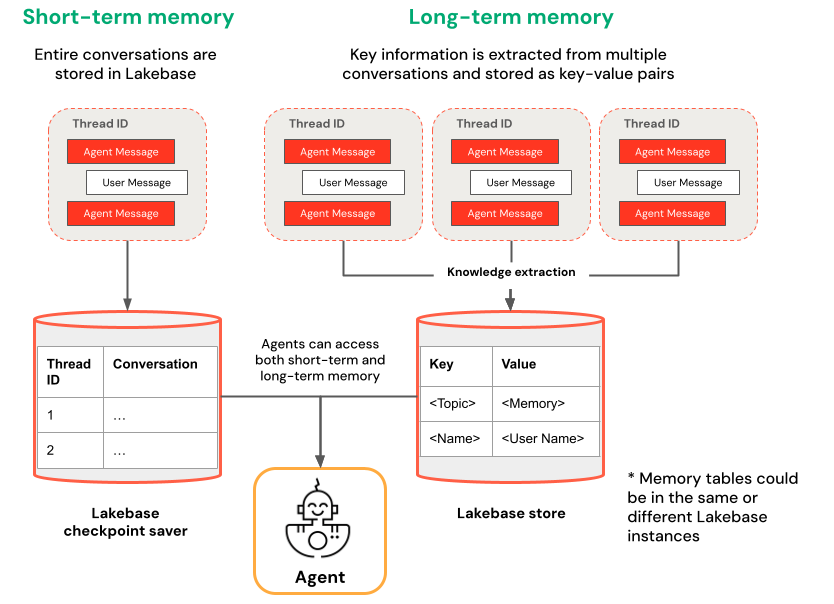
| Kortsiktigt minne | Långtidsminne |
|---|---|
| Fånga kontext i en enda konversationssession med tråd-ID och kontrollpunkter Underhålla kontext för uppföljningsfrågor inom en session |
Extrahera och lagra viktiga insikter automatiskt över flera sessioner Anpassa interaktioner baserat på tidigare inställningar Skapa en kunskapsbas om användare som förbättrar svar över tid |
Get started
Om du vill skapa en agent med minne i Databricks-appar klonar du en fördefinierad appmall och följer utvecklingsarbetsflödet som beskrivs i Skapa en AI-agent och distribuera den i Appar. Följande mallar visar hur du lägger till kortsiktigt och långsiktigt minne till agenter med hjälp av populära ramverk.
LangGraph
Klona mallen agent-langgraph-advanced för att skapa en LangGraph-agent med både kortsiktigt och långsiktigt minne. Mallen använder LangGraphs inbyggda kontrollpunkter med Lakebase för hantering av varaktigt tillstånd, inklusive trådbaserad konversationskontext och beständiga användarinsikter mellan sessioner.
git clone https://github.com/databricks/app-templates.git
cd app-templates/agent-langgraph-advanced
OpenAI Agents SDK
Klona mallen agent-openai-advanced för att skapa en agent med hjälp av OpenAI Agents SDK med kortsiktigt minne. Mallen använder Lakebase för att hantera varaktigt tillstånd, vilket möjliggör tillståndsmedvetna dialoger över flera turer, med automatisk hantering av konversationshistorik.
git clone https://github.com/databricks/app-templates.git
cd app-templates/agent-openai-advanced
Bakgrundsprocesser för långkörande agenter
Databricks Apps tillämpar en TIDSGRÄNS för HTTP-anslutning på cirka 300 sekunder. Med bakgrundskörning kan agentuppgifter som överskrider den här gränsen fortsätta att köras när anslutningen har stängts. klienten hämtar resultat från en separat slutpunkt eller återansluter för att återuppta direktuppspelningen.
De avancerade mallarna – agent-langgraph-advanced och agent-openai-advanced – utökar basmallarna med kortsiktigt minne och långvarig bakgrundskörning via LongRunningAgentServer från databricks-ai-bridge, vilket ger:
-
Bakgrundsläge: Ange
background=truei begärandetexten att returnera ett svars-ID omedelbart och köra agenten asynkront. -
Hämta slutpunkt: Skicka
GET /responses/{id}för att hämta slutresultatet eller för att öppna en direktuppspelningsanslutning till en pågående körning. -
Återupptagningsbar direktuppspelning: Varje server-skickad händelse innehåller en
sequence_number. Om anslutningen avbryts återansluter du tillstarting_after=Nför att återuppta från nästa händelse. - TASK_TIMEOUT_SECONDS Miljövariabel som begränsar varaktigheten för bakgrundsaktiviteter. Detta är oberoende av tidsgränsen för 120-sekunders Databricks Apps HTTP-anslutning, som endast gäller för en enda HTTP-begäran. (standard: 1 timme)
Den avancerade mallen README visar exempel på begäranden för fem klientlägen:
- Invoke: En standard-POST-förfrågan som inte strömmas.
- Stream: En standarduppspelningspost.
-
Bakgrund och sedan sondering: Gör en POST med
background=true, och sedan sonderaGET /responses/{id}tills det är klart. -
Bakgrundsströmning, återuppta strömning: POST med
background=trueochstream=true; om anslutningen avbryts återansluter du tillGET /responses/{id}medstream=true. -
Bakgrundsströmning, fortsätt via polling: Samma kickoff; om anslutningen avbryts, så kan du poll:a
GET /responses/{id}för att få slutresultatet.
Distribuera och fråga din agent
När du har konfigurerat din agent med minne följer du stegen i Skapa en AI-agent och distribuerar den i Appar för att köra din agent lokalt, utvärdera den och distribuera den till Databricks Apps.