Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Belastningstestning hittar de maximala frågor per sekund (QPS) som din Databricks Apps-agent kan upprätthålla innan prestandan försämras. Den här sidan visar hur du gör följande:
- Distribuera en modellversion av agenten för att isolera infrastrukturdataflödet från LLM-svarstiden.
- Kör ett ramp-till-mättnadsbelastningstest med Locust.
- Analysera resultat med en interaktiv instrumentbräda.
Du kan följa den AI-assisterade sökvägen med hjälp av en Claude Code-färdighet eller konfigurera varje steg manuellt.
Krav
- En Azure Databricks arbetsyta med Databricks-appar aktiverade.
- En agentapp som distribueras (eller är redo att distribueras) i Databricks-appar med hjälp av OpenAI Agents SDK, LangGraph eller ett anpassat ramverk. Se Skapa en AI-agent och distribuera den i Databricks-appar.
- Databricks CLI har installerats och autentiserats. Se Installera eller uppdatera Databricks CLI.
- Python 3.10+ med
uvpakethanterare. - (För ai-assisterad väg) Claude Code har installerats.
- (För belastningstester längre än ~1 timme) Ett huvudnamn för tjänsten med M2M OAuth-autentiseringsuppgifter (
client_idochclient_secret). Se Auktorisera tjänstens huvudnamnsåtkomst till Azure Databricks med OAuth.- För korta belastningstester (mindre än ~1 timme) fungerar dina befintliga användar-OAuth-autentiseringsuppgifter
databricks auth login(U2M). För längre tester, använd M2M OAuth med en tjänstehuvudnyckel — U2M-token går ut under längre körningar och orsakar avbrott i testerna. För att skapa ett tjänsthuvudnamn krävs administratörsåtkomst för arbetsytan.
- För korta belastningstester (mindre än ~1 timme) fungerar dina befintliga användar-OAuth-autentiseringsuppgifter
AI-assisterad installation (rekommenderas)
Om du använder Claude Code automatiserar färdigheten /load-testing arbetsflödet. Den läser din agentkod, genererar ett mockobjekt, skapar skript för belastningstest och vägleder dig genom distributionen.
Tips/Råd
Be Claude Code att göra det åt dig:
Clone https://github.com/databricks/app-templates and run the /load-testing skill against the {your-template} template.
Eller följ stegen nedan.
Steg 1: Klona en agentmall
Kunskapen /load-testing ingår i lagringsplatsen databricks/app-templates , både som den bästa agent-load-testing kompetensen och försynkroniserad i varje enskild agentmall. Om du redan har ett projekt från app-templateshar du redan kunskapen.
Klona lagringsplatsen och ändra till mallkatalogen för den agent som du vill läsa in testet:
git clone https://github.com/databricks/app-templates.git
cd app-templates/{your-template}
Steg 2: Kör belastningstestfunktionen
Kör i Claude-koden:
/load-testing
Kunskapen vägleder dig interaktivt genom följande steg. Du kan hoppa över att håna för att testa din riktiga agent eller hoppa över distributionen om dina appar redan körs.
- Samla in parametrar: frågar om distributionsstatus, beräkningsstorlekar, arbetskonfigurationer och OAuth-autentiseringsuppgifter.
-
Skapa belastningstestskript: genererar
locustfile.py,run_load_test.py, ochdashboard_template.pysom skräddarsys för ditt projekt. - Skapa en mock-version av din LLM: skapar en mock-klient som är specifik för din SDK (OpenAI Agents SDK, LangGraph eller egen) som ersätter verkliga LLM-anrop med konfigurerbara fördröjningar i strömning.
- Distribuera testappar: vägleder dig genom att distribuera flera appkonfigurationer med olika beräkningsstorlekar och antal arbetare.
- Kör tester: kör belastningstestet med M2M OAuth-autentisering och ramp-till-mättnad.
- Genererar resultat: skapar en interaktiv HTML-instrumentpanel med QPS, svarstid och felmått.
Manuell konfiguration
Följ de här stegen för att konfigurera och köra belastningstester utan AI-hjälp.
Steg 1: Håna agentens LLM-anrop (valfritt)
Hoppa över det här steget om du vill ha resultat från slutpunkt till slutpunkt som innehåller verklig LLM-svarstid. Om du vill mäta dataflödet för Databricks Apps-infrastrukturen isolerat hånar du LLM så att svarstiden per begäran (vanligtvis 1–30 sekunder) inte blir flaskhalsen.
Ett mock-objekt returnerar för-programmerade svar med en konfigurerbar strömningsfördröjning, bevarar hela pipelinen för begäran/svar (SSE-strömning, verktygsanrop, SDK-körning) och byter endast ut LLM. Detta ger den maximala QPS som Databricks Apps-plattformen kan leverera och undviker kostnader för API-token för Foundation Model under belastningstester.
Den falska tidpunkten styrs av två miljövariabler:
| Variabel | Standardinställning | Description |
|---|---|---|
MOCK_CHUNK_DELAY_MS |
10 |
Fördröjning i millisekunder mellan strömmade textsegment |
MOCK_CHUNK_COUNT |
80 |
Antal textsegment per svar |
Med standardvärdena tar varje mock-svar cirka 800 ms (10 ms x 80 segment), betydligt snabbare än ett riktigt LLM-svar (3–15 sekunder). Dataflödesnummer återspeglar sedan plattformen, inte modellen.
Skapa en falsk klient som ersätter den verkliga LLM-klienten. Resten av agentkoden förblir oförändrad och metoden beror på din SDK. För OpenAI, se mock_openai_client.py referensimplementeringen i databricks/app-templates. Samma mönster anpassas till andra SDK:er.
OpenAI Agents SDK
Skapa agent_server/mock_openai_client.py – en MockAsyncOpenAI klass som implementerar chat.completions.create() med direktuppspelning. Den returnerar verktygsanropssegment direkt (simulerar LLM som bestämmer sig för att anropa ett verktyg) och textsvarssegment med konfigurerbar fördröjning från MOCK_CHUNK_DELAY_MS och MOCK_CHUNK_COUNT miljövariabler.
Växla den till din agent:
from agent_server.mock_openai_client import MockAsyncOpenAI
from agents import set_default_openai_client, set_default_openai_api
set_default_openai_client(MockAsyncOpenAI())
set_default_openai_api("chat_completions")
Resten av din agentkod (hanterare, verktyg, strömningslogik) förblir oförändrad.
LangGraph
Ersätt ChatDatabricks modellen med en mock som returnerar fördefinierade AIMessage objekt:
# Before:
# model = ChatDatabricks(endpoint="databricks-claude-sonnet-4")
# After:
from agent_server.mock_llm import MockChatModel
model = MockChatModel()
Mock ska returnera AIMessage objekt med verktygsanrop vid det första anropet och textinnehåll vid efterföljande anrop, med konfigurerbara strömfördröjningar.
Skräddarsydda agenter
Lägg in de externa API-anrop som agenten gör (LLM, vektorsökning, verktygs-API:er) med mock-implementeringar som returnerar realistiska svarsmönster med konfigurerbara fördröjningar.
Steg 2: Konfigurera belastningstestningsskript
Skapa en load-test-scripts/ katalog i projektet. Ramverket för belastningstestning består av tre skript som är ramverksagnostiska och fungerar med alla Databricks Apps-agenter.
<project-root>/
agent_server/ # Your existing agent code
load-test-scripts/ # Load testing scripts (create this)
run_load_test.py # CLI orchestrator
locustfile.py # Locust test with SSE streaming + TTFT tracking
dashboard_template.py # Interactive HTML dashboard generator
load-test-runs/ # Results (auto-created per run)
<run-name>/
dashboard.html # Interactive dashboard
test_config.json # Test parameters for reproducibility
<label>/ # Per-config Locust CSV output
Ramverket innehåller följande filer:
-
locustfile.py: Ett Locust-belastningstest som skickarPOST /invocationsbegäranden medstream: true, parsar SSE-strömmar, spårar tid till första token (TTFT) som ett anpassat mått, använder M2M OAuth-tokenutbyte med automatisk uppdatering och implementerar enStepRampShapesom rampar användare frånstep_sizetillmax_usersmedan de håller varje nivå istep_durationsekunder. -
run_load_test.py: En CLI-orkestrerare som testar varje app-URL sekventiellt med isolerade mått per konfiguration. Den hanterar OAuth-tokenuppdatering, kör en hälsokontroll och uppvärmning före varje test och sparar resultatet tillload-test-runs/<run-name>/<label>/. -
dashboard_template.py: Genererar en fristående HTML-instrumentpanel med hjälp av Chart.js med KPI-kort, stapeldiagram (QPS, svarstid, TTFT efter konfiguration), QPS-rampprogressionslinjediagram och en fullständig resultattabell. Kan köras fristående:uv run dashboard_template.py ../load-test-runs/<run-name>/.
Installera beroenden
Skripten för belastningstestning använder sina egna pyproject.toml inuti load-test-scripts/ för att undvika att förorena agentens produktionsberoenden. Skapa load-test-scripts/pyproject.toml:
[project]
name = "load-test-scripts"
version = "0.1.0"
requires-python = ">=3.10"
dependencies = [
"locust>=2.32,<2.40",
"urllib3<2.3",
"requests",
]
Note
Fäst locust till <2.40. Nyare versioner (>=2.43) har en känd RecursionError som bryter långa belastningstester.
Installera inifrån load-test-scripts/ katalogen:
cd load-test-scripts/
uv sync
Steg 3: Distribuera testappar med olika konfigurationer
Distribuera flera Databricks-appar med olika beräkningsstorlekar och antal arbetare för att hitta den optimala konfigurationen för din arbetsbelastning.
Rekommenderad testmatris
Konfigurationerna nedan fokuserar på den sweet spot som identifierats från tidigare testning. Om du vill ha bredare täckning lägger du till en konfiguration på båda sidor (till exempel medium-w1 eller large-w12), men de sex nedan räcker vanligtvis.
| Beräknad storlek | Arbetare | Föreslaget appnamn |
|---|---|---|
| Medium | 2 | <your-app>-medium-w2 |
| Medium | 3 | <your-app>-medium-w3 |
| Medium | 4 | <your-app>-medium-w4 |
| Stort | 6 | <your-app>-large-w6 |
| Stort | 8 | <your-app>-large-w8 |
| Stort | 10 | <your-app>-large-w10 |
Konfigurera beräkningsstorlek
Använd Databricks CLI för att ange beräkningsstorlek när du skapar eller uppdaterar en app:
# Create a new app with Medium compute
databricks apps create <app-name> --compute-size MEDIUM
# Update an existing app to Large compute
databricks apps update <app-name> --compute-size LARGE
Konfigurera antalet arbetare med Deklarativa Automatiseringspaket
start-server (via AgentServer.run()) accepterar en --workers flagg direkt. Skicka antalet arbetare i matrisen command med hjälp av en DAB-variabel:
variables:
app_name:
default: 'my-agent-medium-w2'
workers:
default: '2'
resources:
apps:
load_test_app:
name: ${var.app_name}
source_code_path: .
config:
command: ['uv', 'run', 'start-server', '--workers', '${var.workers}']
env:
- name: MOCK_CHUNK_DELAY_MS
value: '10'
- name: MOCK_CHUNK_COUNT
value: '80'
targets:
medium-w2:
default: true
variables:
app_name: 'my-agent-medium-w2'
workers: '2'
large-w8:
variables:
app_name: 'my-agent-large-w8'
workers: '8'
Distribuera och verifiera
Distribuera varje mål med Databricks CLI:
databricks bundle deploy --target medium-w2
databricks bundle run load_test_app --target medium-w2
Kontrollera att appar är aktiva innan du kör belastningstester:
databricks apps get <app-name> --output json | jq '{app_status, compute_status, url}'
Note
Vänta tills alla appar når ACTIVE status innan du fortsätter. Appar som fortfarande håller på att starta kan ge missvisande resultat.
Steg 4: Kör belastningstester
Konfigurera autentisering
Välj din autentisering baserat på hur länge du planerar att köra:
-
Korta tester (mindre än ~1 timme): Använd dina befintliga användarautentiseringsuppgifter från
databricks auth login. Ingen extra installation krävs. - Långa tester (mer än ~1 timme, till exempel körningar över natten): använd M2M OAuth med tjänsthuvudkonto. U2M-token upphör att gälla och bryter testet mitt i körningen. För att skapa ett huvudnamn för tjänsten krävs administratörsåtkomst för arbetsytan.
För M2M OAuth exporterar du autentiseringsuppgifterna för tjänstens huvudnamn innan du kör tester:
export DATABRICKS_HOST=https://your-workspace.cloud.databricks.com
export DATABRICKS_CLIENT_ID=<your-client-id>
export DATABRICKS_CLIENT_SECRET=<your-client-secret>
Referens för parametrar
| Parameter | Obligatoriskt | Standardinställning | Description |
|---|---|---|---|
--app-url |
Yes | — | App-URL:er som ska testas (repeterbara) |
--client-id |
För långa tester |
DATABRICKS_CLIENT_ID Env |
Klient-ID för service principal (M2M OAuth) |
--client-secret |
För långa tester |
DATABRICKS_CLIENT_SECRET Env |
Klienthemlighet för tjänstens huvudnamn (M2M OAuth) |
--label |
No | Automatiskt härledd från URL | Mänskligt läsbar etikett per app (repeterbar) |
--compute-size |
No | Identifieras automatiskt eller medium |
Tagg för beräkningsstorlek per app: medium, large (repeterbar) |
--max-users |
No | 300 |
Maximalt antal samtidiga simulerade användare |
--step-size |
No | 20 |
Användare som läggs till per rampsteg |
--step-duration |
No | 30 |
Sekunder per rampsteg |
--spawn-rate |
No | 20 |
Användargenereringshastighet (användare/sekund) |
--run-name |
No | <timestamp> |
Namn för denna körning – resultaten sparas i load-test-runs/<run-name>/ |
--dashboard |
No | Av | Generera interaktiv HTML-instrumentpanel när testerna har slutförts |
Exempelkommandon
Snabbt test med en app (kort körning – använder din databricks auth login session):
cd load-test-scripts/
uv run run_load_test.py \
--app-url https://my-app.aws.databricksapps.com \
--dashboard --run-name quick-test
Fullständig matris över de rekommenderade 6 konfigurationerna (lång sikt – skicka M2M-autentiseringsuppgifter). Skicka --compute-size flaggor i samma ordning som --app-url:
uv run run_load_test.py \
--app-url https://my-app-medium-w2.aws.databricksapps.com \
--app-url https://my-app-medium-w3.aws.databricksapps.com \
--app-url https://my-app-medium-w4.aws.databricksapps.com \
--app-url https://my-app-large-w6.aws.databricksapps.com \
--app-url https://my-app-large-w8.aws.databricksapps.com \
--app-url https://my-app-large-w10.aws.databricksapps.com \
--compute-size medium --compute-size medium --compute-size medium \
--compute-size large --compute-size large --compute-size large \
--client-id $DATABRICKS_CLIENT_ID \
--client-secret $DATABRICKS_CLIENT_SECRET \
--dashboard --run-name overnight-sweep
Flera körningar för statistisk samstämmighet:
for RUN in r1 r2 r3 r4 r5; do
uv run run_load_test.py \
--app-url https://my-app.aws.databricksapps.com \
--client-id $DATABRICKS_CLIENT_ID \
--client-secret $DATABRICKS_CLIENT_SECRET \
--max-users 1000 --step-size 20 --step-duration 10 \
--run-name my_test_${RUN} --dashboard || break
done
Vad händer under en körning
-
Hälsokontroll: verifierar att appen strömmar korrekt (tar emot
[DONE]). - Uppvärmning: skickar sekventiella begäranden för att värma upp appen.
-
Ramp-till-mättnad: ökar antalet samtidiga användare varje
step_durationsekund. - Mättnadsidentifiering: när QPS når en platå trots att du lägger till fler användare, då har du nått genomflödestak.
Uppskattad varaktighet
Varje app som testas körs via en egen ramp, så den totala körningstiden skalar med antalet konfigurationer i matrisen. Använd formeln nedan för att planera körningsfönstret.
Varaktighet per app: (max_users / step_size) * step_duration sekunder.
Med standardvärden (--max-users 300 --step-size 20 --step-duration 30):
- 15 steg x 30 sekunder = cirka 7,5 minuter per app
- För den rekommenderade 6-konfigurationsmatrisen: cirka 45 minuter per körning
Steg 5: Visa och tolka resultat
Öppna instrumentpanelen:
open load-test-runs/<run-name>/dashboard.html(Valfritt) Återskapa instrumentpanelen från befintliga data, till exempel efter att mallen har uppdaterats:
cd load-test-scripts/ uv run dashboard_template.py ../load-test-runs/<run-name>/
Kontrollpanelavsnitt
Den interaktiva instrumentpanelen innehåller:
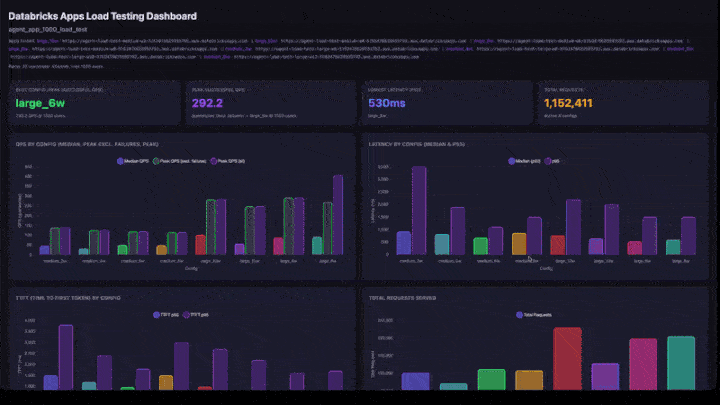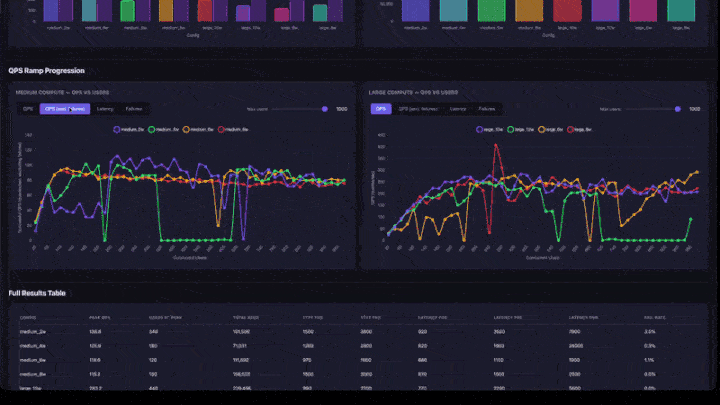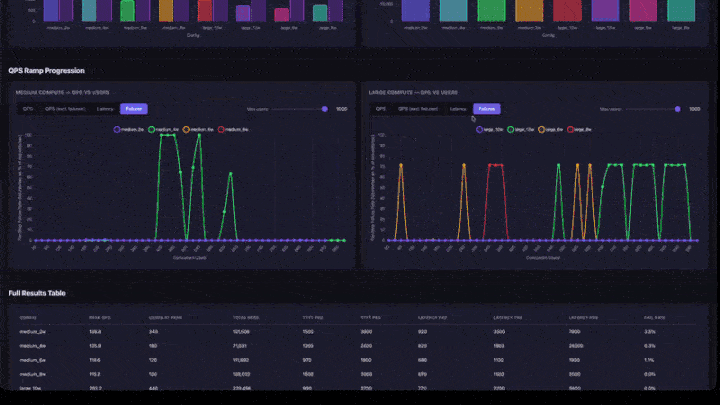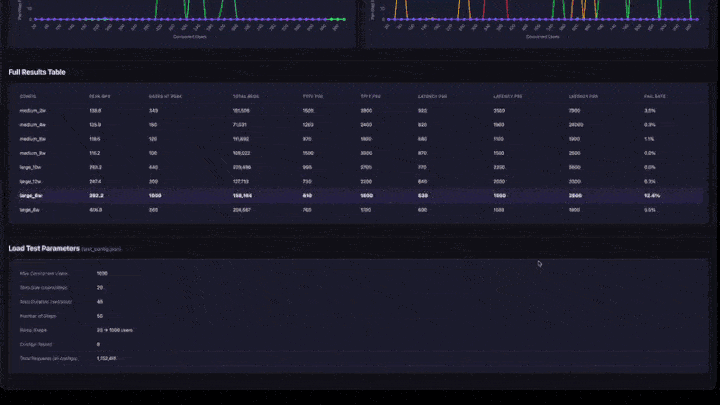
- KPI-kort: bästa konfigurationen (efter bästa lyckade QPS), övergripande QPS-topp, lägsta svarstid och totalt antal begäranden som hanteras.
- QPS efter konfiguration: grupperat stapeldiagram som visar median-QPS, topp-QPS exklusive fel och topp-QPS sida vid sida för varje konfiguration.
- Svarstid efter konfiguration: grupperade staplar som visar p50- och p95-svarstid.
- TTFT by Config: time to first token (p50 och p95).
- Totalt antal begäranden som hanteras: antal begäranden per konfiguration.
- QPS-rampprogression: linjediagram med flikar för QPS, QPS (exklusive fel), svarstid och fel. Innehåller ett skjutreglage för maximalt antal användare för att zooma in i lägre samtidighetsintervall. Diagram grupperas efter beräkningsstorlek (medelstor och stor sida vid sida).
- Fullständig resultattabell: alla konfigurationer med högsta QPS, användare med hög belastning, percentiler för svarstid och felfrekvens.
- Testparametrar: konfigurationssammanfattning för reproducerbarhet.
Så här tolkar du resultat
- Högsta QPS: den maximala QPS som uppnås vid varje rampsteg. Det här är genomströmningstaket för denna konfiguration.
- Användare med hög belastning: antalet samtidiga användare när QPS-toppen uppnåddes. Att lägga till fler användare utöver den här punkten ökar inte dataflödet.
- Felfrekvens: bör vara 0% eller mycket låg. En hög felfrekvens innebär att appen är överbelastad på den samtidighetsnivån.
- QPS-rampdiagram: leta efter var linjen planar ut. Det är mättnadspunkten: om du lägger till fler användare ökar inte dataflödet.
Felsökning
| Problem | Lösning |
|---|---|
| Autentiseringstoken har upphört att gälla mitt i testet | För tester som är längre än ~1 timme växlar du från U2M till M2M OAuth genom att skicka --client-id och --client-secret |
| Hälsokontrollen misslyckas | Kontrollera att appen är AKTIV: databricks apps get <name> --output json |
| 0 QPS eller inga resultat | Kontrollera load-test-runs/<run-name>/<label>/locust_output.log efter fel |
| Låg QPS trots högt antal användare | Appen är överbelastad. Prova fler arbetare eller större beräkning. |
| Hög felfrekvens | Appen är överbelastad. Minska --max-users eller öka processorer/datorkapacitet. |
| Instrumentpanelen visar inga rampdata | Verifiera results_stats_history.csv finns i varje resultatunderkatalog |
Nästa steg
- Testa med riktiga LLM-anrop: hoppa över mockningssteget och distribuera din faktiska agent för att mäta end-to-end-latens, inklusive LLM-svarstid.
- Justera antalet arbetare: Använd testmatrisresultatet för att hitta det optimala antalet arbetare för din beräkningsstorlek.
- Självstudie: Utvärdera och förbättra ett GenAI-program för att mäta noggrannhet, relevans och säkerhet vid sidan av dataflödet.