Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tips
Data Factory i Microsoft Fabric är nästa generations Azure Data Factory, med en enklare arkitektur, inbyggd AI och nya funktioner. Om dataintegrering är nytt för dig börjar du med Fabric Data Factory. Befintliga ADF-arbetsbelastningar kan uppgraderas till Fabric för att få åtkomst till nya funktioner inom datavetenskap, realtidsanalys och rapportering.
Kör dina Azure Machine Learning pipelines som ett steg i dina Azure Data Factory- och Synapse Analytics-pipelines. Aktiviteten Machine Learning Execute Pipeline möjliggör scenarier för batchprediktion som att identifiera möjliga betalningsinställelser, fastställa sentiment och analysera kundbeteendemönster.
Videon nedan ger en sex minuter lång introduktion och demonstration av den här funktionen.
Skapa en maskininlärningspipelinekörning med användargränssnitt
Utför följande steg om du vill använda en Machine Learning köra pipelineaktivitet i en pipeline:
Sök efter Machine Learning i aktivitetsfältet Pipeline och dra en Machine Learning Köra pipeline-aktivitet till arbetsytan för pipeline.
Välj den nya aktiviteten Machine Learning Kör Pipeline på arbetsytan om den inte redan är markerad och Inställningar-fliken för att redigera detaljerna.
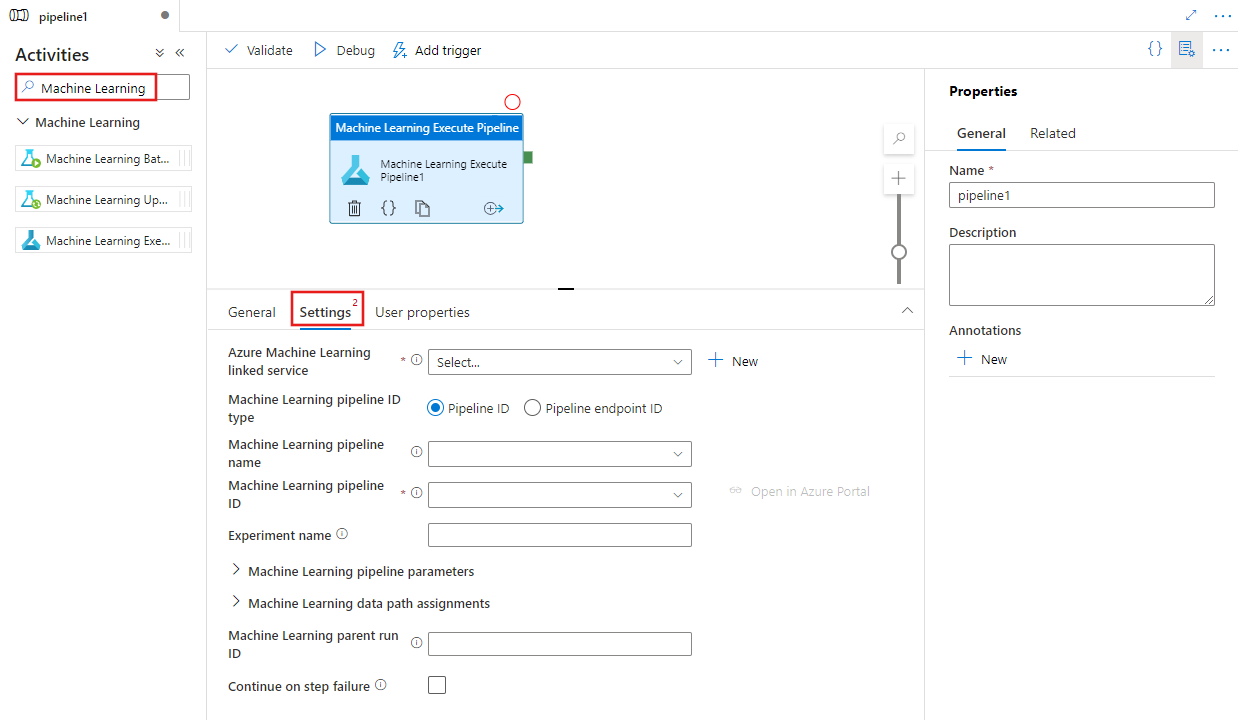
Välj en befintlig eller skapa en ny Azure Machine Learning länkad tjänst och ange information om pipelinen och experimentet samt eventuella pipelineparametrar eller datasökvägstilldelningar som krävs för pipelinen.
Syntax
{
"name": "Machine Learning Execute Pipeline",
"type": "AzureMLExecutePipeline",
"linkedServiceName": {
"referenceName": "AzureMLService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"mlPipelineId": "machine learning pipeline ID",
"experimentName": "experimentName",
"mlPipelineParameters": {
"mlParameterName": "mlParameterValue"
}
}
}
Typegenskaper
| Egenskap | beskrivning | Tillåtna värden | Obligatoriskt |
|---|---|---|---|
| namn | Namnet på aktiviteten i pipelinen | String | Ja |
| typ | Typ av aktivitet är "AzureMLExecutePipeline" | String | Ja |
| länkadTjänstNamn | Länkad tjänst till Azure Machine Learning | Referens för länkad tjänst | Ja |
| mlPipelineId | ID för den publicerade Azure Machine Learning pipelinen | Sträng (eller uttryck med "resultType" av sträng) | Ja |
| experimentName | Kör namn på historiken av experimentet för körningen av Machine Learning-pipelinen | Sträng (eller uttryck med "resultType" av sträng) | Nej |
| mlPipelineParameters | Nyckel-värdepar som ska skickas till den publicerade Azure Machine Learning pipeline-slutpunkten. Nycklar måste matcha namnen på pipeline-parametrar som definierats i den publicerade maskininlärnings-pipelinen | Objekt med nyckelvärdepar (eller uttryck med resultType-objekt) | Nej |
| mlParentRunId | Körnings-ID för överordnad Azure Machine Learning-pipeline | Sträng (eller uttryck med "resultType" av sträng) | Nej |
| dataPathAssignments | Ordlista som används för att ändra datavägar i Azure Machine Learning. Aktiverar växling av datasökvägar | Objekt med nyckelvärdepar | Nej |
| continueOnStepFailure | Huruvida man ska fortsätta exekveringen av andra steg i en Machine Learning-pipeline om ett steg misslyckas | boolean | Nej |
Kommentar
För att fylla i listruteobjekten i Machine Learning pipelinenamn och ID måste användaren ha behörighet att lista ML-pipelines. Användargränssnittet anropar AzureMLService-API:er direkt med den inloggade användarens autentiseringsuppgifter. Upptäckningstiden för objekt i listrutan skulle vara mycket längre när du använder privata slutpunkter.
Relaterat innehåll
Se följande artiklar som förklarar hur du transformerar data på andra sätt: