Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Bearbetning av naturligt språk omfattar tekniker som analyserar, förstår och genererar mänskligt språk från textdata. Azure tillhandahåller hanterade API-drivna tjänster och distribuerade ramverk med öppen källkod som hanterar arbetsbelastningar för bearbetning av naturligt språk som sträcker sig från attitydanalys och entitetsigenkänning till dokumentklassificering och textsammanfattning. Den här guiden hjälper dig att utvärdera och välja bland de primära bearbetningsalternativen för naturligt språk på Azure så att du kan matcha rätt teknik med dina arbetsbelastningskrav.
Anmärkning
Den här guiden fokuserar på funktioner för bearbetning av naturligt språk som är tillgängliga via Azure Language och Apache Spark med Spark NLP på Azure Databricks eller Microsoft Fabric. Det ger ingen vägledning för hur du väljer språkmodeller eller utformar Azure OpenAI-lösningar. Vissa plattformsbeskrivningar kan referera till grundläggande modell- eller talmodellintegreringar som implementeringsinformation, men den här guiden fokuserar på valet av tjänst för bearbetning av naturligt språk. Mer information finns i Välj en AI-tjänstteknik.
Förstå bearbetnings- och språkmodeller för naturligt språk
Innan du utvärderar Azure tjänster ska du förstå vad bearbetning av naturligt språk är, hur den skiljer sig från språkmodeller och vilka uppgifter den hanterar.
Skilja bearbetning av naturligt språk från språkmodeller
Det här avsnittet klargör gränsen mellan bearbetning av naturligt språk och språkmodeller och undersöker de kärnfunktioner som tekniker för bearbetning av naturligt språk möjliggör.
| Mått | Bearbetning av naturligt språk | Språkmodeller |
|---|---|---|
| Scope | Ett brett fält som omfattar olika textbearbetningstekniker, inklusive tokenisering, härstamning, entitetsigenkänning, attitydanalys och dokumentklassificering. | En delområde inom djupinlärning av naturlig språkbehandling som fokuserar på avancerad språkanalys och generering. |
| Exempel | Regelbaserade parsare, termfrekvens-inverterad dokumentfrekvens (TF-IDF) klassificerare, namngivna entitetsigenkänningar, attitydanalyserare. | GPT, BERT och liknande transformeringsbaserade modeller som genererar mänsklig, kontextmedveten text. |
| Resultat | Strukturerade signaler som etiketter, poäng, extraherade intervall och parsad syntax. | Flytande naturligt språk som genererad text, sammanfattningar, svar och slutföranden. |
| Förhållande | Den överordnade domänen. Bearbetning av naturligt språk omfattar hela spektrumet av textbearbetningsmetoder. | Ett verktyg inom bearbetning av naturligt språk. Språkmodeller förbättrar bearbetningen av naturligt språk utan att ersätta den. De hanterar bredare kognitiva uppgifter men är inte synonyma med bearbetning av naturligt språk. |
Bearbetningsfunktioner för naturligt språk
Klassificera dokument genom att märka dem som känsliga eller skräppost. Bearbetning av naturligt språk kategoriserar automatiskt dokument baserat på innehåll för att stödja arbetsflöden för efterlevnad och filtrering.
Sammanfatta text genom att identifiera entiteter i dokumentet. Bearbetning av naturligt språk extraherar viktiga entiteter för att skapa kortfattade sammanfattningar som samlar in den viktigaste informationen.
Tagga dokument med nyckelord med hjälp av identifierade entiteter. När du har identifierat entiteter kan du generera nyckelordstaggar som förenklar dokumentorganisationen. Använd dessa taggar för innehållsbaserad sökning och hämtning.
Identifiera ämnen för navigering och relaterad dokumentidentifiering. Bearbetning av naturligt språk identifierar viktiga ämnen med hjälp av extraherade entiteter, som stöder dokumentkategorisering och ämnesbaserad navigering.
Utvärdera textkänsla. Attitydanalys utvärderar den känslomässiga tonen i text och klassificerar innehållet som positivt, negativt eller neutralt.
Mata in utdata för bearbetning av naturligt språk i underordnade arbetsflöden. Resultat som extraherade entiteter, sentimentpoäng och ämnesetiketter fungerar som indata för bearbetning, sökindexering och analys.
Identifiera potentiella användningsfall
Affärsscenarier i många branscher drar nytta av lösningar för bearbetning av naturligt språk. Följande användningsfall visar hur tekniker för bearbetning av naturligt språk hanterar verkliga utmaningar, från bearbetning av ostrukturerade dokument till att möjliggöra nya program inom cybersäkerhet och tillgänglighet.
Bearbeta dokument och ostrukturerad text
Extrahera intelligens från maskinskapade dokument. Bearbetning av naturligt språk möjliggör dokumentbearbetning inom ekonomi, sjukvård, detaljhandel, myndigheter och andra sektorer. Du kan analysera digitalt skapade dokument för att extrahera strukturerad information från ostrukturerade indata. För handskrivna dokument använder du Azure Document Intelligence för att konvertera handskrivet innehåll till text innan du använder bearbetningstekniker för naturligt språk.
Använd branschagnostiska bearbetningsuppgifter för naturligt språk för textbearbetning. Med namngiven entitetsigenkänning (NER), klassificering, sammanfattning och relationsextrahering kan du automatiskt bearbeta och analysera ostrukturerat dokumentinnehåll. Dessa uppgifter fungerar mellan domäner och kräver inte branschspecifik anpassning.
Skapa domänspecifika modeller för specialiserad analys. Exempel på dessa uppgifter är riskstratifieringsmodeller för hälso- och sjukvård, ontologiklassificering för kunskapshantering och detaljhandelssammanfattningar för produkt- och kunddata. Anpassad modellträning i Azure Language och Spark NLP hjälper till att förbättra noggrannheten för dessa domänspecifika dokumentformat.
Generera automatiserade rapporter från strukturerade dataindata. Du kan syntetisera och generera omfattande textrapporter från strukturerade data. Den här funktionen hjälper sektorer som ekonomi och efterlevnad som kräver noggrann dokumentation.
Aktivera sökning, översättning och analys
Skapa kunskapsdiagram och aktivera semantisk sökning via informationshämtning. Bearbetning av naturligt språk stöder skapande av kunskapsdiagram och semantisk sökning, vilket gör att system kan tolka fråge mening i stället för att bara förlita sig på nyckelordsmatchning.
Stöd för läkemedelsidentifiering och kliniska prövningar med medicinska kunskapsgrafer. Bearbetningssystem för naturligt språk analyserar klinisk text. Medicinska kunskapsdiagram byggda från den texten stöder läkemedelsidentifieringspipelines och matchning av kliniska prövningar. Dessa grafer kopplar samman entiteter som droger, villkor och resultat för att påskynda arbetsflöden för forskning. Textanalys för hälsa i Azure Language extraherar medicinska entiteter, relationer och intyg som du kan använda för att konstruera dessa grafer.
Översätta text för konversations-AI i kundinriktade program. Textöversättning möjliggör konversations-AI i flera branscher. Du kan skapa flerspråkiga kundinriktade program som bearbetar och svarar på användarens önskade språk. Spark NLP tillhandahåller översättningsfunktioner direkt. På Azure använder du Azure Translator, som är en separat tjänst från Azure Language.
Analysera sentiment och känslomässig intelligens för varumärkesuppfattning. Attitydanalys hjälper dig att övervaka varumärkesuppfattning och analysera kundfeedback genom att visa positiva, negativa och nyanserade känslomässiga signaler från text.
Utöka bearbetning av naturligt språk till nya domäner
Skapa röstaktiverade gränssnitt för Sakernas Internet (IoT) och smarta enheter. Bearbetning av naturligt språk hanterar textutdata från taligenkänningssystem för att förstå användaravsikt och extrahera betydelse i scenarier med IoT och smarta enheter. Röstaktiverade scenarier kräver Azure Speech för tal-till-text-konvertering före bearbetning av naturligt språk.
Justera språkutdata dynamiskt med hjälp av anpassningsbara språkmodeller. Anpassningsbara språkmodeller justerar dynamiskt språkutdata så att de passar olika målgruppsförståelsenivåer, vilket stöder leverans av utbildningsinnehåll och tillgänglighet.
Identifiera nätfiske och felaktig information via textanalys för cybersäkerhet. Bearbetning av naturligt språk analyserar kommunikationsmönster och språkanvändning i realtid för att identifiera potentiella säkerhetshot i digital kommunikation. Den här analysen hjälper till att identifiera nätfiskeförsök och desinformationskampanjer.
Utvärdera Azure språk
Azure Language är en molnbaserad tjänst som tillhandahåller funktioner för bearbetning av naturligt språk för att förstå och analysera text. Du kan komma åt den via Foundry-portalen, REST-API:er och klientbibliotek för Python, C#, Java och JavaScript utan infrastruktur att hantera. För AI-agentutveckling kan du också komma åt dessa funktioner via Azure Language Model Context Protocol (MCP)-servern. Du kan komma åt den som en fjärrserver i Microsoft Foundry-verktygskatalogen eller som en lokal lokalt installerad server.
Fördefinierade funktioner
Fördefinierade funktioner kräver ingen modellträning och är redo att användas:
NER: Identifierar och kategoriserar entiteter i text i fördefinierade typer som personer, organisationer, platser och datum.
PII-identifiering: Identifierar och redigerar personligt identifierbar information (PII), inklusive känsliga personliga data och hälsodata, i text- och transkriberade konversationer.
Språkidentifiering: Identifierar språket i ett dokument över en mängd olika språk och dialekter.
Attitydanalys och åsiktsutvinning: Identifierar positiva, negativa eller neutrala sentiment i text och länkar åsikter till specifika element som produktattribut eller tjänstaspekter.
Extrahering av nyckelfraser: Utvärderar ostrukturerad text och returnerar en lista med huvudbegrepp och nyckelfraser.
Sammanfattning: Komprimerar dokument och konversationer med hjälp av extraherande eller abstrakta metoder som stöder sammanfattning av text, chatt och callcenter.
Textanalys för hälsa: Extraherar och etiketterar relevant hälsoinformation från ostrukturerad klinisk text, inklusive medicinska enheter, relationer och intyg.
Träna anpassade modeller
Du kan använda anpassningsbara funktioner för att träna modeller på dina data för att hantera domänspecifika bearbetningsuppgifter för naturligt språk:
- Anpassad namngiven entitetsigenkänning (CNER): Skapa anpassade modeller för att extrahera domänspecifika entitetskategorier från ostrukturerad text. Använd CNER när fördefinierade NER-kategorier inte täcker ditt domänförråd.
Azure LANGUAGE MCP-server och -agenter
Anmärkning
MCP-servern Azure Language och både avsiktsroutning och exakta frågesvarsagenter finns i förhandsversion. Förhandsversionsfunktioner inkluderar inte ett serviceavtal (SLA) och vi rekommenderar dem inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller har begränsade funktioner. Mer information finns i Supplemental terms of use for Microsoft Azure previews.
Azure Language tillhandahåller fördefinierade agenter och flexibla distributionsalternativ för bearbetning av arbetsbelastningar med naturligt språk för produktion:
Intenthanteringsagent: Hanterar konversationsflöden. Den förstår användarnas avsikter och vägar till korrekta svar via deterministisk, granskningsbar logik. Använd den här agenten när du behöver transparent, deterministisk konversationsroutning.
Exakt frågesvarsagent: Ger tillförlitliga ord-för-ord-svar på affärskritiska frågor samtidigt som mänsklig tillsyn och kvalitetskontroll upprätthålls. Använd den här agenten när svarsnoggrannhet och konsekvens är viktiga.
Du kan komma åt båda agenterna via foundry-verktygskatalogen. Mer information finns i Azure Language MCP-server och -agenter (förhandsversion).
MCP-servern Azure Language stöder flera distributionsalternativ:
Fjärrmolnhanterad MCP-server: Gjutningsverktygskatalogen visar en lista över den här servern. Servern ger molnhanterad åtkomst till Azure Language-funktioner och kräver ingen lokal infrastruktur.
Lokal MCP-server med egen värd: Stöder lokala eller självhanterade distributioner för krav på efterlevnad, säkerhet eller datahemvist.
Containerbaserad distribution: Följande funktioner stöder containerbaserad distribution för scenarier som kräver lokal bearbetning eller luftspända miljöer. En fullständig lista över tillgängliga containrar och deras tillgänglighetsstatus finns i stöd för Azure AI-containrar.
- Känsloanalys
- Språkidentifiering
- Extrahering av nyckelfraser
- NER
- PII-identifiering
- CNER
- Textanalys för hälsa
- Sammanfattning (förhandsversion)
Utvärdera Apache Spark med Spark NLP
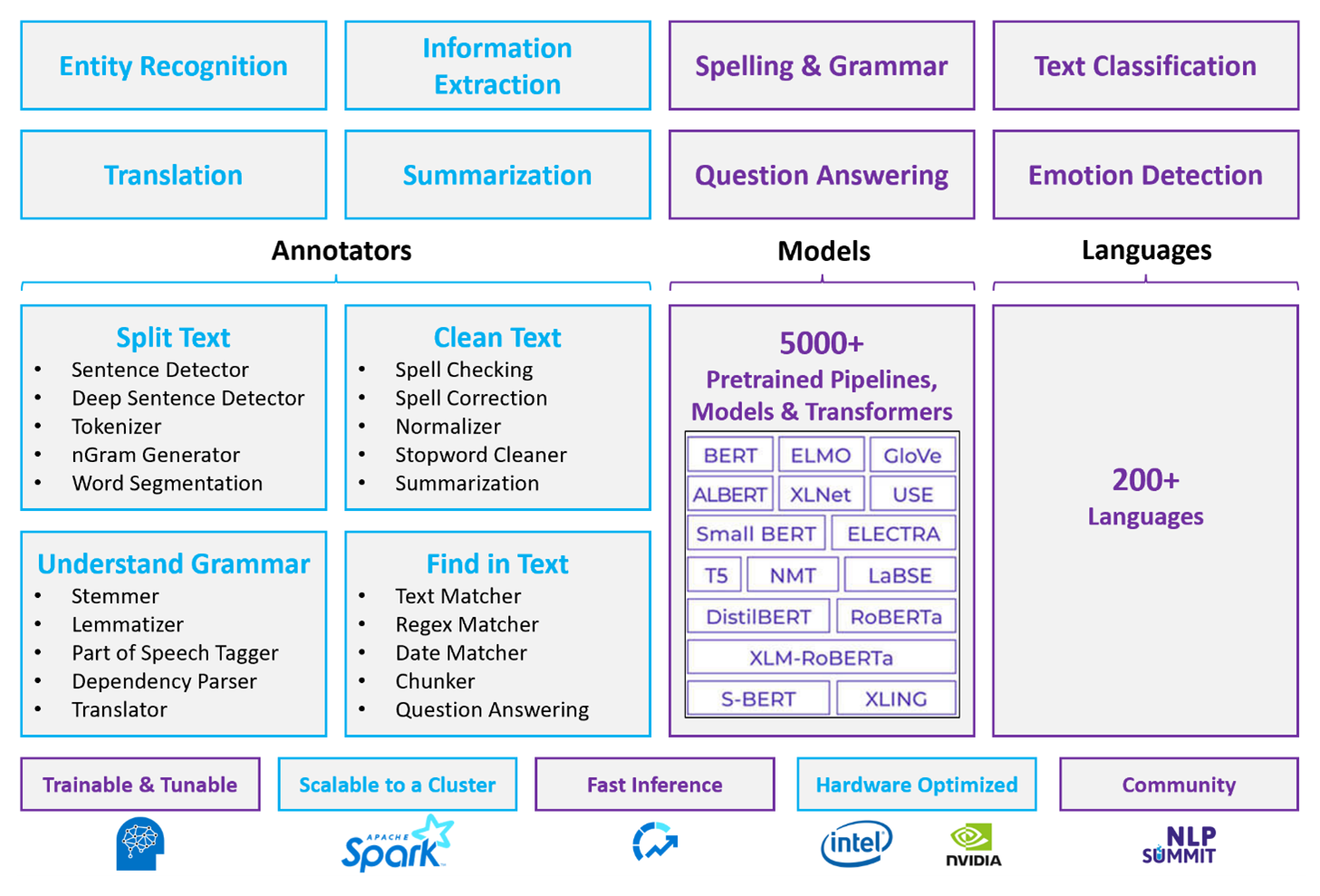
Apache Spark med Spark NLP är en distribuerad metod med öppen källkod för bearbetning av naturligt språk som fungerar i klusterskala. Spark NLP-plattformens arkitektur, prestanda och fördefinierade modellekosystem gör det till ett starkt alternativ för storskaliga, anpassningsbara bearbetningsarbetsbelastningar för naturligt språk på Azure Databricks eller Fabric.
Förstå plattform och arkitektur
Vi rekommenderar att du använder Fabric eller Azure Databricks för Apache Spark-baserade bearbetningsarbetsbelastningar för naturligt språk.
Apache Spark tillhandahåller parallell bearbetning i minnet för stordataanalys. Fabric och Azure Databricks ger dig åtkomst till Apache Spark-bearbetningsfunktioner för storskalig bearbetning av naturligt språk.
Spark NLP fungerar som en inbyggd förlängning av Spark ML på dataramar. Den här integreringen möjliggör enhetlig bearbetning av naturligt språk och maskininlärningspipelines med bättre prestanda på distribuerade kluster.
Spark NLP är ett bibliotek med öppen källkod med stöd för Python, Java och Scala. Biblioteket tillhandahåller funktioner som är jämförbara med spaCy och Natural Language Toolkit (NLTK), inklusive stavningskontroll, attitydanalys och dokumentklassificering.

Apache®, Apache Spark och flamlogotypen är antingen registrerade varumärken eller varumärken som tillhör Apache Software Foundation i United States och/eller andra länder. Inget godkännande från Apache Software Foundation underförstås av användningen av dessa märken.
Utvärdera prestanda och skalbarhet
Offentliga riktmärken visar betydande hastighetsförbättringar jämfört med andra bibliotek för bearbetning av naturligt språk. Jämfört med ramverk som spaCy och NLTK visar Spark NLP snabbare träning och slutsatsdragning i distribuerade kluster. Anpassade modeller som Spark NLP tränar når noggrannhetsnivåer som matchar de som andra ramverk för naturlig språkbehandling, vilket gör det lämpligt för produktionsmiljöer där hastighet och precision krävs.
Optimerade versioner för processorer, GPU:er och Intel Xeon-chips använder Apache Spark-kluster fullt ut. Dessa versioner möjliggör träning och slutsatsdragning för att skala effektivt mellan klusternoder.
MPNet-inbäddningar och ONNX-stöd möjliggör exakt, kontextmedveten bearbetning. MPNet producerar kompakta vektorrepresentationer som fångar semantisk betydelse, och MED ONNX-stöd kan du importera och köra optimerade modeller för slutsatsdragning.
Använda fördefinierade modeller och pipelines
Fördefinierade djupinlärningsmodeller hanterar NER, dokumentklassificering och sentimentidentifiering. Biblioteket levereras med fördefinierade djupinlärningsmodeller.
Förtränade språkmodeller stöder inbäddningar av ord, segment, mening och dokument. Biblioteket innehåller förtränade språkmodeller som stöder inbäddningsnivåer för ord, segment, mening och dokument. Dessa inbäddningar ger kompakta vektorrepresentationer som möjliggör underordnade uppgifter som likhetssökning och klassificering.
Enhetlig bearbetning av naturligt språk och maskininlärningspipelines stöder dokumentklassificering och riskförutsägelse. Integreringen med Spark ML stöder enhetlig bearbetning av naturligt språk och maskininlärningspipelines för uppgifter som dokumentklassificering och riskförutsägelse. Med den här enhetliga metoden kan du kombinera textbearbetning med traditionella maskininlärningsmodeller i en enda pipeline, vilket minskar arkitekturkomplexiteten.
Hantera vanliga utmaningar med bearbetning av naturligt språk
Både Azure Language och Apache Spark med Spark NLP står inför vanliga utmaningar inom bearbetning av naturligt språk i stor skala. Om du förstår dessa utmaningar kan du planera resurser, utforma arbetsflöden och ställa in förväntningar på precision innan du förbinder dig till något av alternativen.
Resursbearbetning
Bearbetning av text i fritt format kräver betydande beräkningsresurser och tid. Textdokument i fritt format är beräkningsmässigt dyra och tidsintensiva att analysera. Varje dokument kräver tokenisering, normalisering och modellinferens innan det ger användbara resultat.
Spark NLP-arbetsbelastningar kräver ofta GPU-beräkningsdistribution. För storskaliga Spark NLP-pipelines ger GPU-accelererade kluster på Azure Databricks eller Fabric den parallella bearbetningskraft som krävs för träning och slutsatsdragning. Optimeringar som Llama 3.x-modellkvantisering bidrar till att minska minnesavtrycket och förbättra dataflödet för dessa intensiva uppgifter.
Azure Language kräver dataflödesplanering och kvothantering. Tjänsten hanterar resurshantering, men API-anrop med stora volymer kräver noggrann dataflödesplanering. Övervaka dina begärandefrekvenser mot tjänstgränser och hastighetsgränser för att undvika begränsning och säkerställa konsekvent bearbetningsprestanda.
Dokumentstandardisering
Verkliga dokument följer sällan en konsekvent struktur. Den här inkonsekvensen skapar utmaningar för extraheringspipelines och kräver avsiktliga strategier för att upprätthålla noggrannhet mellan källor.
Inkonsekventa format: Utan ett standardiserat dokumentformat kan det vara svårt att extrahera specifika fakta från friformstext. Det kan till exempel vara en utmaning att extrahera fakturanummer och datum från olika leverantörer eftersom fältlayouter, etiketter och formatering varierar mellan olika källor.
Anpassad modellträning: När du tränar anpassade modeller i Spark NLP och Azure Language kan du anpassa dig till domänspecifika dokumentformat. När du tränar på representativa exempel på dina faktiska dokument kan du förbättra extraheringsprecisionen för fält, entiteter och mönster som fördefinierade modeller inte hanterar väl.
Datavariens och komplexiteten
Olika dokumentstrukturer och språkliga nyanser ökar komplexiteten. Verkliga textdata finns i många format, skrivstilar och språk. För att hantera dessa varianter krävs modeller som kan hantera tvetydighet, slang, förkortningar och domänspecifik terminologi samtidigt som noggrannheten bibehålls.
MPNet-inbäddningar i Spark NLP ger förbättrad kontextuell förståelse. MPNet-inbäddningar fångar kontextuella relationer mellan ord och fraser, vilket hjälper Spark NLP-pipelines att hantera nyanserad text mer effektivt. Dessa inbäddningar skapar kompakta vektorrepresentationer som bevarar semantisk betydelse i olika dokumentformat.
Anpassade modeller i Azure Language anpassas till domänspecifika textmönster. Med CNER kan du träna modeller på dina egna märkta data för att identifiera mönster som är specifika för din domän. Den här metoden förbättrar tillförlitligheten genom att lära modellen att identifiera entiteter och kategorier som fördefinierade modeller missar.
Tillämpa kriterier för nyckelval
Använd följande kriterier för att avgöra vilket Azure-alternativ för bearbetning av naturligt språk som bäst passar dina behov. Varje kriterium beskriver en arbetsbelastningsegenskaper och identifierar den tjänst som adresserar den.
Hanterade funktioner för bearbetning av naturligt språk: Använd Azure Language API:er för entitetsigenkänning, avsiktsidentifiering, ämnesidentifiering eller attitydanalys. De här funktionerna är tillgängliga som hanterade tjänster med minimal konfiguration och du behöver inte etablera eller hantera någon infrastruktur.
Fördefinierade eller förtränade modeller: Använd Azure Language om du planerar att använda fördefinierade eller förtränade modeller utan att behöva hantera infrastrukturen. Den här metoden passar små till medelstora datauppsättningar och vanliga uppgifter för bearbetning av naturligt språk där fördefinierade modeller ger tillräcklig noggrannhet. Det ger automatisk skalning, inbyggd säkerhet och prissättning för betalning per samtal utan omkostnader för klusterhantering.
Anpassad modellträning på stora textdatauppsättningar: Använd Azure Databricks eller Fabric med Spark NLP. Dessa plattformar ger den beräkningskraft och flexibilitet som du behöver för omfattande modellträning på stora textdatauppsättningar. Du kan också ladda ned modeller via Spark NLP, inklusive Llama 3.x och MPNet.
Lågnivå primitiv för naturlig språkbehandling: Använd Azure Databricks eller Fabric med Spark NLP för tokenisering, stemming, lemmatisering och TF-IDF. Du kan också använda ett bibliotek med öppen källkod som spaCy eller NLTK. Azure Language in Foundry Tools använder tokenisering internt som en del av sin modellpipeline, men de här stegen exponeras inte som fristående, kontrollerbara API:er.
Skapa pipelines för bearbetning av naturligt språk med hjälp av Spark NLP
Spark NLP följer samma utvecklingsmönster som traditionella Spark ML-modeller när du kör en pipeline för bearbetning av naturligt språk. Du hanterar tränade modeller med hjälp av MLflow för experimentspårning och produktionsdistribution.

Samla ihop kärnkomponenter för rörledningen
En Spark NLP-pipeline kedjar annotatörer i sekvens. Varje kommenterare transformerar utdata från föregående fas och bygger från råtext till semantiska vektorer.
DocumentAssembler är startpunkten för varje Spark NLP-pipeline. Använd
setCleanupModeför valfri förbearbetning av texten, som avlägsnande av HTML-taggar eller normalisering av blanksteg, innan den körs av nedströms annoterare.SentenceDetector identifierar meningsgränser i det monterade dokumentet. Den returnerar identifierade meningar antingen som en
Arrayinom en enskild rad eller som separata rader, beroende på din pipelinekonfiguration. Korrekt meningsidentifiering är viktigt eftersom många nedströmsannotatorer jobbar på meningsnivå.Tokenizer delar upp rå text i diskreta token som ord, siffror och symboler. Om standardreglerna inte räcker till för din domän lägger du till anpassade regler för att hantera specialiserade ordförråd, bindestreckade termer eller domänspecifika mönster.
Normalizer förfinar token genom att använda reguljära uttryck och ordlistetransformeringar. Den rensar text för att minska bruset före inbäddning. Du kan till exempel ta bort accenter, konvertera till gemener eller använda anpassade ordlistemappningar för att standardisera terminologin.
WordEmbeddings mappar token till semantiska vektorer för kontextuell bearbetning. Varje token representeras som en tät vektor som fångar dess betydelse i förhållande till andra token. Olösta token som inte visas i vokabulären för inbäddningar är standardmässigt nollvektorer.
Hantera modeller med MLflow
Spark NLP använder Spark MLlib-pipelines med inbyggt MLflow-stöd . Du behöver inte skriva anpassad serialisering eller integrationskod.
MLflow hanterar experimentspårning, modellversionshantering och distribution. Du kan logga pipelineparametrar, mått och artefakter under träningskörningar. MLflow spårar varje experiment, så att du kan jämföra resultat mellan iterationer och återskapa lyckade konfigurationer.
MLflow integreras direkt med Azure Databricks och Fabric. På Azure Databricks är MLflow förinstallerat och integreras tätt med arbetsytan. Fabric ger också en inbyggd MLflow-upplevelse med intern experimentspårning och automatisk loggning, så du behöver inte installera MLflow separat. Om du kör Spark NLP i en annan Apache Spark-baserad miljö kan du installera MLflow separat och konfigurera det för att spåra experiment mot en fjärrspårningsserver.
Använd MLflow Model Registry för att höja upp modeller till produktion och upprätthålla styrning. Modellregistret tillhandahåller en central lagringsplats för att hantera modellversioner i dina pipelines för bearbetning av naturligt språk. I klassiska distributioner övergår modeller genom faser som förberedande, produktion och arkivering. På Azure Databricks använder nyare distributioner Models i Unity Catalog, som ersätter fasta steg med anpassade alias och taggar för mer flexibel livscykelhantering. På Fabric tillhandahåller arbetsytan ett eget MLflow-baserat modellregister.
Kapacitetsmatris
I följande tabeller sammanfattas de viktigaste skillnaderna i funktioner mellan Spark NLP på Azure Databricks eller Fabric och Azure Language.
Allmänna funktioner
| Kapacitet | Spark NLP (Azure Databricks eller Fabric) | Azure språk |
|---|---|---|
| Förtränade modeller som en tjänst | Ja | Ja |
| REST-API | Ja | Ja |
| Programmerbarhet | Python, Scala | Se Programmeringsspråk som stöds. |
| Stöder bearbetning av stora datamängder och stora dokument | Ja | Begränsad 1 |
1.Azure Language har begränsningar för dokumentstorlek per begäran som varierar beroende på läge. Synkrona begäranden stöder upp till 5 120 tecken per dokument och asynkrona begäranden stöder upp till 125 000 tecken per dokument. Båda lägena stöder upp till 25 dokument per API-anrop. Du kan bearbeta stora datamängdsvolymer genom batchbearbetning och sidnumrering, men enskilda dokument som överskrider teckengränsen för det valda läget kräver segmentering. Mer information finns i Data och hastighetsbegränsningar för Azure Language.
Anteckningsfunktioner
| Kapacitet | Spark NLP (Azure Databricks eller Fabric) | Azure språk |
|---|---|---|
| Meningsdetektor | Ja | Nej |
| Djup meningsdetektor | Ja | Nej |
| Tokeniserare | Ja | Endast internt (visas inte som ett fristående API) |
| N-gramgenerator | Ja | Nej |
| Word segmentering | Ja | Ja |
| Röster | Ja | Nej |
| lemmatiserare | Ja | Nej |
| Del av tal-märkning | Ja | Nej |
| Beroendeparser | Ja | Nej |
| Översättning | Ja | Nej |
| Stoppordsrengöringsmedel | Ja | Nej |
| Stavningskorrigering | Ja | Nej |
| Normalisator | Ja | Ja |
| Textmatchning | Ja | Nej |
| TF-IDF | Ja | Nej |
| Matchning av reguljära uttryck | Ja | Begränsad |
| Datumjämförare | Ja | Begränsad |
| Styckdelare | Ja | Nej |
Bearbetningsfunktioner för naturligt språk på hög nivå
| Kapacitet | Spark NLP (Azure Databricks eller Fabric) | Azure språk |
|---|---|---|
| Stavningskontroll | Ja | Nej |
| Sammanfattning | Ja | Ja |
| Frågor och svar | Ja | Ja |
| Känsloanalys | Ja | Ja |
| Känsloavkänning | Ja | Begränsad 2 |
| Tokenklassificering | Ja | Begränsad 3 |
| Textklassificering | Ja | Begränsad 3 |
| Textuell representation | Ja | Nej |
| NER | Ja | Ja (förbyggd). CNER är tillgängligt via anpassade modeller. 3 |
| Språkidentifiering | Ja | Ja |
| Stöder andra språk än engelska | Ja. Se Språk som stöds av Spark NLP. | Ja. Läs Azure Språk som stöds. |
2.Azure Language stöder åsiktsutvinning, som identifierar känslor kopplade till specifika aspekter av text men inte ger dedikerad känsloidentifiering (som glädje, ilska eller sorgklassificering).
3.Tillgängligvia anpassade modeller. Du tränar CNER- eller anpassade entitetsigenkänningsmodeller på dina egna etiketterade data.
Bidragsgivare
Microsoft uppdaterar den här artikeln. Följande deltagare skrev den här artikeln.
Huvudsakliga författare:
- Ananya Ghosh Chowdhury | Huvudarkitekt för molnlösning
- Kranthi Manchikanti | Senior AI Solutions Engineer
Övriga medarbetare:
- Freddy Ayala | Molnlösningsarkitekt
- Tincy Elias | Senior Cloud Solution Architect
- Moritz Steller | Senior molnlösningsarkitekt
Om du vill se icke-offentliga LinkedIn profiler loggar du in på LinkedIn.
Nästa steg
- Introduction till AI i Azure
- Utveckla lösningar för bearbetning av naturligt språk med hjälp av Foundry Tools
Relaterade resurser
Azure Language-dokumentation:
- översikt över Azure Language
- Foundry-dokumentation
Spark NLP-dokumentation:
Azure komponenter:
Lär dig resurser: