Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Gäller för: Azure Logic Apps (Förbrukning + Standard)
Ibland måste du konvertera innehåll till token, som är ord eller segment av tecken, eller dela upp ett stort dokument i mindre delar innan du kan använda det här innehållet med specifika åtgärder. Till exempel förväntar sig Azure AI-sökning eller Azure OpenAI åtgärder tokeniserade indata och kan endast hantera ett begränsat antal token.
I dessa scenarier använder du åtgärderna Dataåtgärder med namnet Parsa ett dokument och segmenttext i logikappens arbetsflöde. Dessa åtgärder omvandlar innehåll, till exempel ett PDF-dokument, EN CSV-fil, Excel fil och så vidare, till tokeniserade strängutdata och delar sedan upp strängen i bitar, baserat på antalet token. Du kan sedan referera till och använda dessa utdata med efterföljande åtgärder i arbetsflödet.
Tips
Om du vill veta mer kan du ställa Azure Copilot följande frågor:
- Vad är en token i AI?
- Vad är tokeniserade indata?
- Vad är tokeniserade strängutdata?
- Vad är parsning i AI?
- Vad är segmentering i AI?
Om du vill hitta Azure Copilot går du till verktygsfältet Azure och väljer Copilot.
Den här guiden visar hur du lägger till och konfigurerar åtgärder för att parsa dokument och segmentera text i arbetsflödet.
Kända problem och begränsningar
I Förbrukningsarbetsflöden är åtgärden Parse ett dokument endast tillgänglig i följande Azure regioner:
- Australia East
- Syd-Brasilien
- Östasien
- Östra USA
- Östra USA 2
- North Europe
- Södra centrala USA
- Sydostasien
- Centrala Sverige
- Västra USA 2
- Västra USA 3
- UK South
Dessa regioner tillhandahåller datakällanslutningar, dokumentspårning, dokumentsegmentering, stöd för Azure OpenAI-inbäddningsmodeller och inbyggt indexeringsstöd för att hämta data. Mer information finns i Automatisk indexering i AI Search med arbetsflöden i Azure Logic Apps.
Åtgärderna Parsa ett dokument och segmenttext stöder för närvarande inte värdfiler, till exempel stordator- och mellanregisterfiler som VSAM-filer (Virtual Storage Access Method). Men om du arbetar med Standard-arbetsflöden kan du använda den inbyggda åtgärden IBM-värdfil med namnet Parsa värdfilinnehåll i stället.
Förutsättningar
Ett Azure konto och en prenumeration. Om du inte har en Azure-prenumeration, registrera dig för ett kostnadsfritt Azure-konto.
Ett arbetsflöde för förbruknings- eller standardlogikappen med en befintlig utlösare eftersom åtgärderna Parsa ett dokument och segmenttext endast är tillgängliga som åtgärder. Kontrollera att åtgärden som hämtar innehållet som du vill parsa eller segment föregår dessa dataåtgärder.
Parsa ett dokument
Åtgärden Parse a document konverterar innehåll, till exempel ett PDF-dokument, CSV-fil, Excel fil och så vidare, till en tokeniserad sträng. Anta i det här exemplet att arbetsflödet börjar med utlösaren Begäran med namnet När en HTTP-begäran tas emot. Den här utlösaren väntar på att få en HTTP-begäran som skickats från en annan komponent, till exempel en Azure funktion, ett annat arbetsflöde för logikappen och så vidare. HTTP-begäran innehåller URL:en för ett nytt uppladdat dokument som är tillgängligt för arbetsflödet för att hämta och parsa. En HTTP-åtgärd följer omedelbart utlösaren och skickar en HTTP-begäran till dokumentets URL och returnerar med dokumentinnehållet från lagringsplatsen.
Om du använder andra innehållskällor, till exempel Azure Blob Storage, SharePoint, OneDrive, filsystem, FTP och så vidare, kan du kontrollera om utlösare är tillgängliga för dessa källor. Du kan också kontrollera om åtgärder är tillgängliga för att hämta innehållet för dessa källor. För mer information, se Inbyggda operationer och Hanterade anslutningar.
Öppna logikappens resurs och arbetsflöde i designern i Azure-portalen.
Under den befintliga utlösaren och åtgärderna följer du dessa allmänna steg för att lägga till åtgärden Dataåtgärder med namnet Parsa ett dokument i arbetsflödet.
I designern väljer du åtgärden Parsa ett dokument .
När åtgärdsinformationsfönstret har öppnats går du till fliken Parametrar och i egenskapen Dokumentinnehåll anger du det innehåll som ska parsas genom att följa dessa steg:
Välj i rutan Dokumentinnehåll .
Alternativen för listan med dynamiskt innehåll (blixtikonen) och uttrycksredigeraren (funktionsikonen) visas.
Om du vill välja utdata från en föregående åtgärd väljer du listan med dynamiskt innehåll.
Om du vill skapa ett uttryck som ändrar utdata från en föregående åtgärd väljer du uttrycksredigeraren.
Det här exemplet fortsätter genom att välja blixtikonen för listan med dynamiskt innehåll.
När listan med dynamiskt innehåll har öppnats väljer du de utdata som du vill använda från en föregående åtgärd.
I det här exemplet hänvisar åtgärden Parsing av ett dokument till Body-utdata från HTTP-åtgärden.
Brödtexten visas nu i rutan Dokumentinnehåll:
Under åtgärden Parsa ett dokument lägger du till de åtgärder som du vill arbeta med tokeniserade strängutdata, till exempel segmenttext, som beskrivs senare i den här guiden.
Parsa ett dokument – referens
Parameters
| Name | Värde | Datatyp | beskrivning | Gräns |
|---|---|---|---|---|
| Dokumentinnehåll | < content-to-parse> | Vilken som helst | Innehållet som ska parsas. | Ingen |
Utdata
| Name | Datatyp | beskrivning |
|---|---|---|
| Tolkad resultattext | Strängmatris | En matris med strängar. |
| Parsat resultat | Objekt | Ett objekt som innehåller hela den tolkade texten. |
Chunktext
Åtgärden Segmenttext delar upp innehållet i mindre delar för efterföljande åtgärder som enklare kan användas i det aktuella arbetsflödet. Följande steg bygger på exemplet från avsnittet Parse a document och delar upp tokensträngsutdata för användning med Azure AI-åtgärder som förväntar sig tokeniserade, små innehållssegment.
Kommentar
Föregående åtgärder som använder segmentering påverkar inte åtgärden Segmenttext och åtgärden Segmenttext påverkar inte heller efterföljande åtgärder som använder segmentering.
Öppna logikappens resurs och arbetsflöde i designern i Azure-portalen.
Under åtgärden Parsa ett dokument ska du följa dessa allmänna steg för att lägga till åtgärden Dataoperationer med namnet Segmenttext.
På designern, välj åtgärden Dela upp text.
När åtgärdsinformationsfönstret har öppnats går du till fliken Parametrar och väljer TokenSize som segmenteringsmetod för egenskapen Segmenteringsstrategi, om den inte redan har valts.
Strategi beskrivning TokenSize Dela upp det angivna innehållet baserat på antalet token. När du har valt strategin väljer du i rutan Text för att ange innehållet för segmentering.
Alternativen för listan med dynamiskt innehåll (blixtikonen) och uttrycksredigeraren (funktionsikonen) visas.
Om du vill välja utdata från en föregående åtgärd väljer du listan med dynamiskt innehåll.
Om du vill skapa ett uttryck som ändrar utdata från en föregående åtgärd väljer du uttrycksredigeraren.
Det här exemplet fortsätter genom att välja blixtikonen för listan med dynamiskt innehåll.
När listan med dynamiskt innehåll har öppnats väljer du de utdata som du vill använda från en föregående åtgärd.
I det här exemplet refererar åtgärden Chunk text till utdata från Parsat resultat från åtgärden Parsa ett dokument.
Textrutan visar nu utdata för åtgärden Parsat resultat:
Slutför konfigurationen för Segmentera text-åtgärden, baserat på din valda strategi och ditt scenario. Mer information finns i Segmenttext – referens.
När du nu lägger till andra åtgärder som förväntar dig och använder tokeniserade indata, till exempel Azure AI-åtgärder, formateras indatainnehållet för enklare förbrukning.
Segmenttext – referens
Parameters
| Name | Värde | Datatyp | beskrivning | Gränser |
|---|---|---|---|---|
| Segmenteringsstrategi | TokenSize | enum för sträng | Dela upp innehållet baserat på antalet token. Standard: TokenSize |
Inte tillämpligt |
| Text | < content-to-chunk> | Vilken som helst | Innehållet att dela upp. | Se Referensguide för gränser och konfiguration |
| KodningModel | < encoding-method> | enum för sträng | Kodningsmodellen som ska användas: - Förval: cl100k_base (gpt4, gpt-3.5-turbo, gpt-35-turbo) - r50k_base (gpt-3) - p50k_base (gpt-3) - p50k_edit (gpt-3) - cl200k_base (gpt-4o) Mer information finns i Översikt över OpenAI – Modeller. |
Inte tillämpligt |
| TokenSize | < max-tokens-per-chunk> | Integer | Det maximala antalet token per innehållssegment. Standard: Ingen |
Minimum: 1 Maximalt: 8 000 |
| PageOverlapLength | < antal överlappande tecken> | Integer | Antalet tecken från slutet av föregående segment som ska inkluderas i nästa segment. Den här inställningen hjälper dig att undvika att förlora viktig information när du delar upp innehåll i segment och bevarar kontinuitet och kontext mellan segment. Standard: 0 – Det finns inga överlappande tecken. |
Minimum: 0 |
Tips
Om du vill veta mer kan du ställa Azure Copilot följande frågor:
- Vad är PageOverlapLength i segmentering?
- Vad kodas i Azure AI?
Om du vill hitta Azure Copilot går du till verktygsfältet Azure och väljer Copilot.
Utdata
| Name | Datatyp | beskrivning |
|---|---|---|
| Segmenterat resultat Textobjekt | Strängmatris | En matris med strängar. |
| Objekt för segmenterad resultattext | String | En enda sträng i matrisen. |
| Segmenterat resultat | Objekt | Ett objekt som innehåller hela den segmenterade texten. |
Exempelarbetsflöde
I följande exempel ingår andra åtgärder som skapar ett fullständigt arbetsflödesmönster för att mata in data från valfri källa:
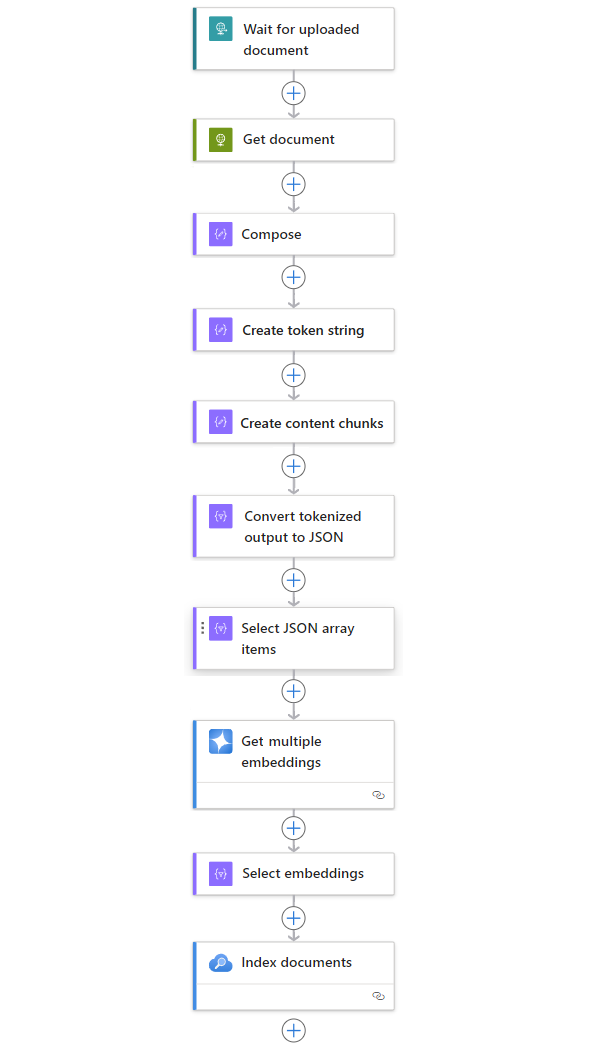
| Steg | Aktivitet | Underliggande åtgärd | beskrivning |
|---|---|---|---|
| 1 | Vänta eller sök efter nytt innehåll. | När en HTTP-begäran tas emot | En utlösare som antingen avsöker eller väntar på att nya data ska tas emot, antingen baserat på en schemalagd upprepning eller som svar på specifika händelser. En sådan händelse kan vara en ny fil som laddas upp till ett visst lagringssystem, till exempel Azure Blob Storage, SharePoint, OneDrive, filsystem, FTP och så vidare. I det här exemplet väntar åtgärden Förfrågningsutlösare på en HTTP- eller HTTPS-begäran som skickas från en annan slutpunkt. Begäran innehåller URL:en för ett nytt uppladdat dokument. |
| 2 | Hämta innehållet. | HTTP | En HTTP-åtgärd som hämtar det uppladdade dokumentet med hjälp av fil-URL:en från utlösarens utdata. |
| 3 | Skriv dokumentinformation. | Compose | En åtgärd för dataåtgärder som sammanfogar olika objekt. I det här exemplet sammanfogas nyckel/värde-information om dokumentet. |
| 4 | Skapa tokensträng. | Parsa ett dokument | En åtgärd för dataåtgärder som genererar en tokeniserad sträng med hjälp av utdata från åtgärden Skriv . |
| 5 | Skapa innehållssegment. | Chunktext | En dataåtgärd som delar upp tokensträngen i bitar, baserat på antalet token per innehållssegment. |
| 6 | Konvertera tokeniserad och segmenterad text till JSON. | Parsa JSON | En dataåtgärder-åtgärd som konverterar segmenterade utdata till en JSON-matris. |
| 7 | Välj JSON-matrisobjekt. | Välj | En åtgärd för dataåtgärder som väljer flera objekt från JSON-matrisen. |
| 8 | Generera inbäddningarna. | Hämta flera inbäddningar | En Azure OpenAI åtgärd som skapar inbäddningar för varje JSON-matrisobjekt. |
| 9 | Välj inbäddningar och annan information. | Välj | En åtgärd för dataåtgärder som väljer inbäddningar och annan dokumentinformation. |
| 10 | Indexering av data. | Indexdokument | En Azure AI-sökning åtgärd som indexerar data baserat på varje vald inbäddning. |