Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Este artigo descreve o destino do Azure Log Analytics para o Fabric Apache Spark Diagnostic Emitter utilizando a API de Ingestão de Logs.
O Fabric Apache Spark Diagnostic Emitter fornece um modelo de configuração comum para diagnósticos do Spark entre destinos. Para Azure Log Analytics, a API de Ingestão de Logs é o modelo de ingestão recomendado.
Este artigo mostra como configurar propriedades dos emissores, encaminhar logs do Apache Spark, registos de eventos e métricas para o Log Analytics, e consultar os dados ingeridos para monitorização e resolução de problemas.
Para a arquitetura e a seleção de destinos no Fabric Apache Spark Diagnostic Emitter, consulte a visão geral do Fabric Apache Spark Diagnostic Emitter.
Migrar a partir da API do Data Collector
Se estiver a usar atualmente a API HTTP Data Collector, migre para a API de Ingestão de Logs para alinhar com os padrões atuais de ingestão do Azure Monitor.
Principais alterações no novo modelo:
- As definições de esquemas são explícitas através das Regras de Recolha de Dados (DCRs), que oferecem validação de esquemas previsível e resultados de consulta mais consistentes do que a abordagem mais antiga de payload livre.
- A ingestão é encaminhada através de Data Collection Endpoints (DCEs) e mapeamentos DCR, que fornecem um caminho de ingestão mais controlado do que a publicação direta no endpoint da API Data Collector.
- A autenticação suporta tanto opções de segredo de cliente principal de serviço como baseadas em certificado.
- O tipo emissor muda de
AzureLogAnalyticsparaAzureLogIngestion.
A migração inclui tipicamente a criação de recursos DCR e DCE, a atualização das propriedades do Spark do ambiente Fabric e a validação da ingestão de dados em tabelas personalizadas de Log Analytics.
Visão geral da API de Ingestão de Registos
Para diagnósticos do Apache Spark no Microsoft Fabric, a API de Ingestão de Logs fornece um modelo estruturado de ingestão para autenticação, definição de esquema, encaminhamento e entrega de tabelas no Azure Log Analytics.
Componentes principais
| Componente | Purpose |
|---|---|
| Credenciais de registo na aplicação | Fornece a identidade da aplicação Microsoft Entra usada para autenticar solicitações da API de Ingestão de Log com um segredo de cliente ou certificado. |
| Tabela Log Analytics | Fornece a tabela personalizada alvo onde os diagnósticos Spark ingeridos são armazenados para consulta e monitorização. |
| Regra de Recolha de Dados (DCR) | Define fluxos de entrada, mapeamento de esquemas e transformações opcionais para ingestão. |
| Ponto de Extremidade de Coleta de Dados (DCE) | Fornece o URI do endpoint de ingestão (dceUri) usado pelos clientes para enviar dados através de encaminhamento baseado em DCR. |
Apenas DCRs criados pelo utilizador configurados para a API de Ingestão de Logs podem ser usados para ingestão programática.
Configuração passo a passo
Passo 1. Prepare o espaço de trabalho Log Analytics
É necessário um espaço de trabalho de Log Analytics para receber diagnósticos do Spark. É a unidade básica de armazenamento e consulta para Azure Monitor Logs.
Se não tiveres um, cria um espaço de trabalho Log Analytics no portal Azure.
Importante
Ao completar os passos seguintes, crie os recursos Data Collection Endpoint (DCE) e Data Collection Rule (DCR) na mesma região do espaço de trabalho Log Analytics.
Passo 2. Criar um Endpoint de Recolha de Dados (DCE)
Crie um Ponto de Coleta de Dados (DCE) no portal Azure. O DCE fornece o URI do endpoint que você configura nas propriedades do Spark para a API de Ingestão de Logs. A região do DCE deve ser a mesma que a região do seu espaço de trabalho Log Analytics.
No portal Azure, vá para Monitor no painel de navegação à esquerda.
Em Definições, selecione endpoints de recolha de dados e depois selecione Criar.
Crie o endpoint, depois anote o nome DCE (por exemplo,
DCEdemo).

Passo 3. Preparar um esquema JSON de exemplo
Ao criar tabelas de registo personalizadas, deve configurar uma Regra de Recolha de Dados (DCR). Com base nas definições de fluxo de dados especificadas no DCR, o sistema gera automaticamente o esquema de tabela correspondente no seu espaço de trabalho Log Analytics.
As seguintes amostras de esquemas JSON pré-definidas correspondem a um tipo de dado específico. Descarrega o exemplo que se adequa ao teu cenário e carrega-o quando criares a tabela personalizada associada e o DCR.
- Registos de eventos Spark - Exemplo de esquema JSON para tabela de eventos
- Registos de driver e executor Spark - Exemplo de esquema JSON em tabela de logs
- Métricas Spark - Exemplo de esquema JSON de tabela métrica
- Metadados da plataforma - Tabela de metadados da plataforma Amostra de esquema JSON
Aqui está um exemplo de esquema em JSON de uma tabela de registos para os logs do driver e do executor do Spark no Azure Log Analytics. Use este esquema como referência ao criar as suas tabelas personalizadas e DCRs para a ingestão de logs.
[
{
"applicationId_s": "<APPLICATION_ID>",
"applicationName_s": "<NOTEBOOK_NAME>",
"artifactId_g": "<ARTIFACT_GUID>",
"artifactType_s": "SynapseNotebook",
"capacityId_g": "<CAPACITY_GUID>",
"Category": "Log",
"executorId_s": "driver",
"executorMax_s": 9,
"executorMin_s": 1,
"ExtraFields": {
"Category": "Log",
"JobId": "1"
},
"fabricEnvId_g": "<FABRIC_ENV_GUID>",
"fabricLivyId_g": "<FABRIC_LIVY_GUID>",
"fabricTenantId_g": "<FABRIC_TENANT_GUID>",
"fabricWorkspaceId_g": "<FABRIC_WORKSPACE_GUID>",
"isHighConcurrencyEnabled_s": false,
"Level": "INFO",
"logger_name_s": "org.apache.spark.scheduler.dynalloc.ExecutorMonitor",
"Message": "Executor 1 is removed.",
"thread_name_s": "spark-listener-group-executorManagement",
"TimeGenerated": "<TIME_GENERATED>",
"userId_g": "<USER_ID>"
}
]
Passo 4. Criar tabela personalizada (Ingesta Direta)
Crie uma tabela personalizada no seu espaço de trabalho Log Analytics com a opção Log Ingestion API e carregue a amostra do esquema JSON para o DCR associado. Este passo é necessário para configurar o destino para o diagnóstico do Spark e garantir que os dados ingeridos cumprem o esquema esperado. A região do espaço de trabalho Log Analytics, DCE e DCR deve ser a mesma para garantir uma ingestão de dados bem-sucedida.
No portal Azure, abra o seu espaço de trabalho Log Analytics (por exemplo, loganalyticsworkspacedemo).
Selecionar Tabelas>Criar>novo registo personalizado (Ingesta Direta).
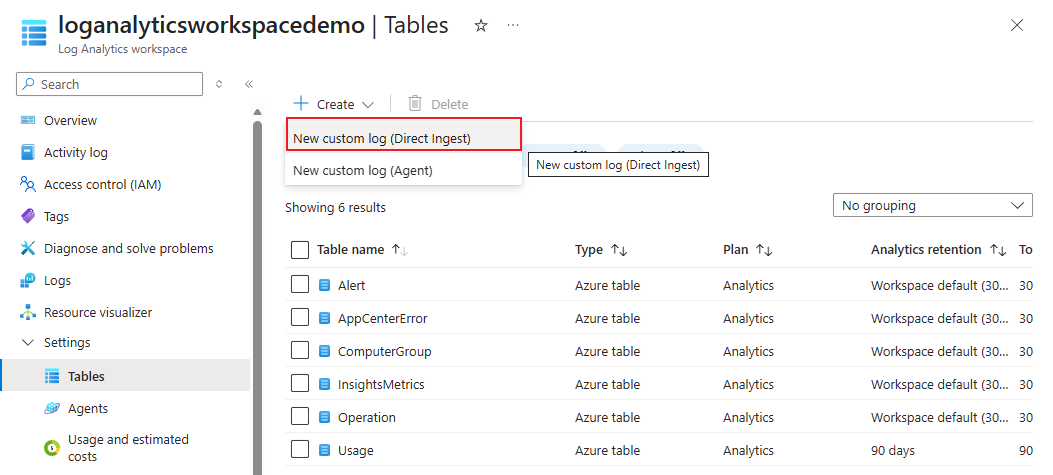
Introduza as definições da tabela:
- Nome da tabela: Por exemplo, SparkLogTest (o sufixo "_CL" é adicionado automaticamente).
- Esquema de Tabela: Análise
- Regra de Recolha de Dados: Crie um novo DCR (por exemplo, SparkLogTestrule).
- Endpoint de Recolha de Dados: Selecione o DCE no passo Criar um Endpoint de Recolha de Dados (DCE) (por exemplo, DCEdemo).

Selecione Avançar.
Em Esquema e Transformação, carregue o exemplo de esquema JSON. Não precisas de configurar a transformação DCR porque o esquema está totalmente estabilizado do lado do cliente.


Passo 5. Preparar o principal de serviço para autenticação
Registe uma aplicação em Microsoft Entra ID.

Regista o TenantId, ClientId, e ClientSecret (se usares autenticação de secreto do cliente). Usas estes valores na configuração do Spark no Passo 6.
Conceda à aplicação a função Publicador de Métricas de Monitorização no recurso DCR de cada tabela. Para os passos de atribuição de funções, consulte Atribuir Azure funções usando o portal Azure.



Passo 6. Configurar propriedades do Spark
Para configurar o Spark, crie um ambiente no Fabric e escolha uma das seguintes opções de autenticação. Use apenas uma opção para um determinado emissor.
Um ambiente dentro do Fabric armazena definições e bibliotecas do Spark que os notebooks e as definições de tarefas do Spark usam em tempo de execução. Para os passos para criar um, veja Criar, configurar e usar um ambiente em Fabric.
- Escolhe a Opção 1 se quiseres uma configuração mais simples usando um cliente secreto.
- Escolha Opção 2 se a sua organização exigir autenticação baseada em certificados e gestão centralizada de certificados em Azure Key Vault.
Em ambas as opções, pode selecionar Adicionar a partir de .yml no ambiente para importar um .yml ficheiro de configuração.
Opção 1: Configurar com o principal de serviço e o segredo do cliente
Use esta opção para uma configuração rápida com credenciais de principal de serviço e um segredo do cliente.
Crie um ambiente no Fabric.
Adicione as seguintes propriedades do Spark com os valores apropriados ao ambiente, ou selecione Adicionar a partir de .yml na barra de ferramentas para importar um
.ymlficheiro de configuração.spark.synapse.diagnostic.emitters: <EMITTER_NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.type: AzureLogIngestion spark.synapse.diagnostic.emitter.<EMITTER_NAME>.categories: DriverLog,ExecutorLog,EventLog,Metrics spark.synapse.diagnostic.emitter.<EMITTER_NAME>.dceUri: https://<DCE_NAME>.<REGION>.ingest.monitor.azure.com spark.synapse.diagnostic.emitter.<EMITTER_NAME>.logDcr: <LOG_DCR_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.logStream: <LOG_STREAM_NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.eventDcr: <EVENT_DCR_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.eventStream: <EVENT_STREAM_NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metricDcr: <METRIC_DCR_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metricStream: <METRIC_STREAM_NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metaDcr: <META_DCR_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metaStream: <META_STREAM_NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.secret: <SP_CLIENT_SECRET> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.tenantId: <SP_TENANT_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.clientId: <SP_CLIENT_ID> spark.fabric.pools.skipStarterPools: 'true'Guardar e publicar as alterações.
Opção 2: Configurar com autenticação do certificado da entidade de serviço
Use esta opção quando a sua organização exigir autenticação baseada em certificados.
Antes de começar, certifique-se de que o seu principal de serviço seja criado com um certificado. Para mais informações, consulte Criar um principal de serviço contendo um certificado usando Azure CLI.
Crie um ambiente no Fabric.
Adicione as seguintes propriedades do Spark com os valores apropriados ao ambiente, ou selecione Adicionar a partir de .yml na barra de ferramentas para importar um
.ymlficheiro de configuração.spark.synapse.diagnostic.emitters: <EMITTER_NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.type: AzureLogIngestion spark.synapse.diagnostic.emitter.<EMITTER_NAME>.categories: DriverLog,ExecutorLog,EventLog,Metrics spark.synapse.diagnostic.emitter.<EMITTER_NAME>.dceUri: https://<DCE_NAME>.<REGION>.ingest.monitor.azure.com spark.synapse.diagnostic.emitter.<EMITTER_NAME>.logDcr: <LOG_DCR_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.logStream: <LOG_STREAM_NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.eventDcr: <EVENT_DCR_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.eventStream: <EVENT_STREAM_NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metricDcr: <METRIC_DCR_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metricStream: <METRIC_STREAM_NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metaDcr: <META_DCR_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metaStream: <META_STREAM_NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.certificate.keyVault.certificateName: <SP_CERT-NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.certificate.keyVault: https://<KEYVAULT_NAME>.vault.azure.net/ spark.synapse.diagnostic.emitter.<EMITTER_NAME>.tenantId: <SP_TENANT_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.clientId: <SP_CLIENT_ID> spark.fabric.pools.skipStarterPools: 'true'Salve e publique as alterações.
Passo 7. Anexe o ambiente a notebooks ou definições de tarefas do Spark, ou defina-o como o padrão do workspace
Use uma das seguintes abordagens, consoante o seu âmbito:
- Anexe o ambiente a cadernos específicos ou definições de funções Spark quando quiser um lançamento direcionado, testes ou controlo por item.
- Defina o ambiente como o padrão do workspace quando quiser que as definições de diagnóstico do Spark sejam aplicadas consistentes em todo o workspace.
Para anexar o ambiente a cadernos ou definições de funções no Spark:
- Navegue até à definição do seu caderno ou da função Spark no Fabric.
- Selecione o menu Ambiente na guia Página Inicial e selecione o ambiente configurado.
- A configuração será aplicada após o início de uma sessão do Spark.
Para definir o ambiente de trabalho como padrão:
- Navegue até às definições do espaço de trabalho no Fabric.
- Encontre as definições do Spark nas definições do espaço de trabalho (Definições do espaço de trabalho>Engenharia de Dados/Ciência>Definições do Spark).
- Selecione a guia Ambiente e escolha o ambiente com propriedades de faísca de diagnóstico configuradas e selecione Salvar.
Passo 8. Executa cargas de trabalho Spark e verifica registos e métricas
Usa o ambiente que criaste e anexaste na secção anterior, depois executa cargas de trabalho do Spark e verifica a ingestão no Log Analytics.
- Execute cargas de trabalho Spark usando o ambiente configurado na secção anterior. Pode usar um dos seguintes métodos:
- Faz um caderno no Fabric.
- Submeter uma tarefa Spark em lote através de uma definição de tarefa Spark.
- Execute as atividades do Spark num pipeline.
- Abra o espaço de trabalho de destino do Log Analytics e verifique se os logs e métricas estão a ser ingeridos para a carga de trabalho em execução.
- Para validar a ingestão e inspecionar registos, use os exemplos Kusto em Executar consultas de dados com Kusto.
Escrever registos personalizados de aplicações
Use logs de aplicações personalizados quando quiser eventos ao nível do negócio ou específicos de uma aplicação, além do diagnóstico da plataforma. Estes registos são emitidos através do mesmo pipeline de diagnóstico e aparecem no Log Analytics juntamente com os registos do Spark, registos de eventos e métricas.
Use o Apache Log4j no seu código Spark para emitir mensagens de registo personalizadas. Os exemplos seguintes mostram um padrão mínimo para Scala e PySpark.
Exemplo de Scala (linguagem de programação):
%%spark
val logger = org.apache.log4j.LogManager.getLogger("com.contoso.LoggerExample")
logger.info("info message")
logger.warn("warn message")
logger.error("error message")
//log exception
try {
1/0
} catch {
case e:Exception =>logger.warn("Exception", e)
}
// run job for task level metrics
val data = sc.parallelize(Seq(1,2,3,4)).toDF().count()
Exemplo do PySpark:
%%pyspark
logger = sc._jvm.org.apache.log4j.LogManager.getLogger("com.contoso.PythonLoggerExample")
logger.info("info message")
logger.warn("warn message")
logger.error("error message")
Consultar dados com Kusto
Use consultas Kusto para validar que a ingestão está a funcionar e para investigar o comportamento de execução do Spark. Substitua valores provisórios como {FabricWorkspaceId}, {ArtifactId}, e {LivyId} por valores da sua própria execução.
Comece com consultas de eventos e registos para confirmar a chegada dos dados, depois use consultas métricas para análise de desempenho.
Para consultar eventos do Apache Spark:
SparkEventTest_CL
| where fabricWorkspaceId_g == "{FabricWorkspaceId}" and artifactId_g == "{ArtifactId}" and fabricLivyId_g == "{LivyId}"
| order by TimeGenerated desc
| limit 100
Para consultar o driver do aplicativo Spark e os logs do executor:
SparkLogTest_CL
| where fabricWorkspaceId_g == "{FabricWorkspaceId}" and artifactId_g == "{ArtifactId}" and fabricLivyId_g == "{LivyId}"
| order by TimeGenerated desc
| limit 100
Para consultar métricas do Apache Spark:
SparkMetricsTest_CL
| where fabricWorkspaceId_g == "{FabricWorkspaceId}" and artifactId_g == "{ArtifactId}" and fabricLivyId_g == "{LivyId}"
| where name_s endswith "jvm.total.used"
| summarize max(value_d) by bin(TimeGenerated, 30s), executorId_s
| order by TimeGenerated asc
Para consultar metadados da plataforma:
SparkMetadataTest_CL
| where fabricWorkspaceId_g == "{FabricWorkspaceId}" and artifactId_g == "{ArtifactId}" and fabricLivyId_g == "{LivyId}"
| order by TimeGenerated desc
| limit 100
Espaços de trabalho Fabric com rede virtual gerida
Fabric suporta proteção contra exfiltração de dados para espaços de trabalho. Com a proteção contra exfiltração, os registos e métricas não podem ser enviados diretamente para os endpoints de destino. Neste cenário, podes criar endpoints privados geridos correspondentes para diferentes endpoints de destino.
Configurações disponíveis do Apache Spark
A tabela seguinte lista as configurações do Spark para enviar logs e métricas ao Azure Log Analytics utilizando a API de Ingestão de Logs.
Importante
Para Azure Log Analytics, defina spark.synapse.diagnostic.emitter.<EMITTER_NAME>.type para AzureLogIngestion.
AzureLogAnalytics é o tipo de API HTTP Data Collector legado. Para orientações legadas, veja Monitorizar aplicações Apache Spark com Azure Log Analytics.
| Configuração | Descrição |
|---|---|
spark.synapse.diagnostic.emitters |
Os nomes de destino separados por vírgulas dos elementos emissores de diagnóstico. Por exemplo, MyDest1,MyDest2. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.type |
Tipo de destino incorporado. Para ativar Azure Log Analytics via API de Ingestão de Log, defina este valor para AzureLogIngestion. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.categories |
As categorias selecionadas de log, separadas por vírgula. Os valores disponíveis incluem DriverLog, ExecutorLog, EventLog, Metrics. Se não estiver definido, o valor padrão são todas as categorias. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.dceUri |
O URI Data Collection Endpoint (DCE) é usado para a ingestão de dados ao encaminhar dados através de Regras de Recolha de Dados (DCRs). |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.logDcr |
O ID de recurso da Regra de Recolha de Dados (DCR) é usado para encaminhar os registos do Spark para o destino. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.logStream |
O nome do fluxo definido na Regra de Recolha de Dados (DCR) para registos Spark. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.eventDcr |
O ID de recurso da Regra de Recolha de Dados (DCR) é usado para encaminhar os registos de eventos do Spark. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.eventStream |
O nome do fluxo definido na Regra de Recolha de Dados (DCR) para registos de eventos do Spark. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metricDcr |
O ID de recurso da Regra de Recolha de Dados (DCR) é usado para encaminhar métricas do Spark. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metricStream |
O nome do fluxo definido na Regra de Recolha de Dados (DCR) para métricas do Spark. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metaDcr |
O ID de recurso da Regra de Recolha de Dados (DCR) é usado para encaminhar metadados do Spark. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metaStream |
O nome do fluxo definido na Regra de Recolha de Dados (DCR) para metadados do Spark. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.certificate.keyVault.certificateName |
O nome do certificado armazenado no Azure Key Vault, usado para autenticação. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.certificate.keyVault |
O Azure Key Vault URI que armazena o certificado de autenticação. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.tenantId |
O ID do locatário do Microsoft Entra usado para autenticação. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.clientId |
O ID do cliente (aplicação) registado no Microsoft Entra ID. |
spark.fabric.pools.skipStarterPools |
Esta propriedade Spark é usada para forçar uma sessão sob demanda do Spark. Defina o valor para true quando usar o pool predefinido, para fazer com que as bibliotecas registem logs e métricas. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.secret |
O segredo do cliente associado à aplicação Microsoft Entra ID (Azure AD), usado em conjunto com o ID do inquilino e o ID do cliente para autenticar o emissor ao enviar dados de diagnóstico. Esta configuração é mutuamente exclusiva com a autenticação baseada em certificados — configure o segredo do cliente ou o certificado, mas não ambos. |
Conteúdo relacionado
- Criar a definição de tarefa do Apache Spark
- Criar, configurar e usar um ambiente em Microsoft Fabric
- Desenvolver, executar e gerir Microsoft Fabric notebooks
- Monitorar aplicativos Spark
- Recolha diagnósticos do Apache Spark usando Azure Event Hubs
- Recolha diagnósticos do Apache Spark usando Azure Storage Conta