Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
A funcionalidade do caderno T-SQL no Microsoft Fabric permite-lhe escrever e executar código T-SQL dentro de um caderno. Você pode usar blocos de anotações T-SQL para gerenciar consultas complexas e escrever melhor documentação de marcação. Isso também permite a execução direta de T-SQL no armazém conectado ou no endpoint de análise SQL. Ao adicionar um Data Warehouse ou endpoint de análise SQL a um caderno, os programadores T-SQL podem executar consultas diretamente no endpoint conectado. Os analistas de BI também podem realizar consultas entre bases de dados para coletar insights de vários armazéns de dados e pontos finais de análise SQL.
A maioria das funcionalidades de notebook existentes estão disponíveis para notebooks T-SQL. Isso inclui gráficos de resultados de consultas, coautoria de blocos de anotações, agendamento de execuções regulares e acionamento de execução em pipelines de Integração de Dados.
Neste artigo, vai aprender a:
- Criar um bloco de anotações T-SQL
- Adicionar um endpoint de Data Warehouse ou SQL Analytics a um caderno
- Criar e executar código T-SQL em um bloco de anotações
- Use os recursos de gráficos para representar graficamente os resultados da consulta
- Guardar a consulta como vista ou tabela
- Executar consultas entre armazéns
- Ignorar a execução de código não-T-SQL
Criar um bloco de anotações T-SQL
Para começar com essa experiência, você pode criar um bloco de anotações T-SQL das seguintes maneiras:
Cria um caderno T-SQL a partir do espaço de trabalho Fabric: seleciona Novo item, depois escolhe Caderno no painel que abre.

Crie um bloco de notas T-SQL a partir de um editor de armazém existente: navegue até um armazém existente e, na barra de navegação superior, selecione Nova consulta SQLe, em seguida, Novo bloco de notas de consulta T-SQL.
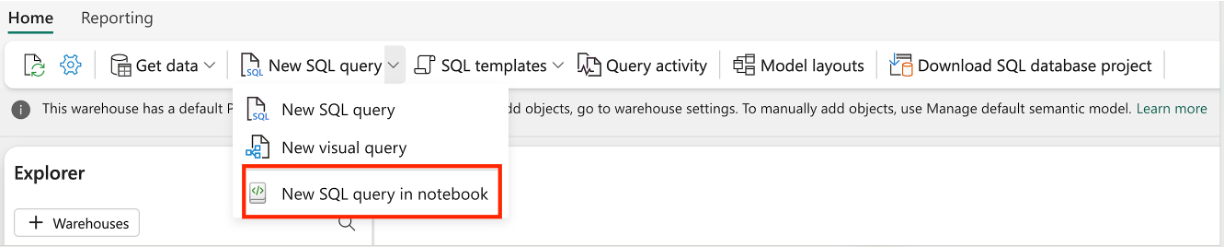


Depois que o bloco de anotações é criado, o T-SQL é definido como o idioma padrão. Você pode adicionar endpoints de data warehouse ou de análises SQL do espaço de trabalho atual ao seu notebook.
Adicione um endpoint de Data Warehouse ou SQL Analytics num caderno
Para adicionar um endpoint de análise de Data Warehouse ou SQL num caderno, no editor de cadernos, selecione o botão + Fontes de dados e selecione Warehouses. No painel data-hub, selecione o data warehouse ou o ponto de extremidade de análise SQL ao qual pretende conectar-se.

Definir um armazém principal
Você pode adicionar vários armazéns ou endpoints de análise SQL ao notebook, com um deles definido como principal. O armazém principal executa o código T-SQL. Para defini-lo, vá para o explorador de objetos, selecione ... ao lado do depósito e escolha Definir como principal.

Para qualquer comando T-SQL que ofereça suporte à nomenclatura de três partes, o depósito principal é usado como o depósito padrão se nenhum depósito for especificado.
Criar e executar código T-SQL em um bloco de anotações
Para criar e executar código T-SQL em um bloco de anotações, adicione uma nova célula e defina T-SQL como a linguagem da célula.

Você pode gerar automaticamente o código T-SQL usando o modelo de código no menu de contexto do pesquisador de objetos. Os seguintes modelos estão disponíveis para blocos de anotações T-SQL:
- Selecione os melhores 100
- Criar tabela
- Criar como selecionar
- Eliminar
- Eliminar e criar

Você pode executar uma célula de código T-SQL selecionando o botão Executar na barra de ferramentas da célula ou executar todas as células selecionando o botão Executar tudo na barra de ferramentas.
Nota
Cada célula de código é executada em uma sessão separada, portanto, as variáveis definidas em uma célula não estão disponíveis em outra célula.
Dentro da mesma célula de código, ele pode conter várias linhas de código. O usuário pode selecionar parte desses códigos e executar apenas os selecionados. Cada execução também gera uma nova sessão.

Depois que o código for executado, expanda o painel de mensagens para verificar o resumo da execução.

A guia Tabela lista os registos da selecção de resultados devolvida. Se a execução contiver vários conjuntos de resultados, pode-se alternar de um para outro utilizando o menu suspenso.

Use os recursos de gráficos para representar graficamente os resultados da consulta
Ao clicar em Inspecionar, você pode ver os gráficos que representam a qualidade dos dados e a distribuição de cada coluna

Guardar a consulta como vista ou tabela
Você pode usar o menu Salvar como tabela para salvar os resultados da consulta na tabela usando o comando CTAS . Para usar esse menu, selecione o texto da consulta na célula de código e selecione Salvar como menu de tabela .


Da mesma forma, você pode criar um modo de exibição a partir do texto de consulta selecionado usando o menu Salvar como modo de exibição na barra de comandos da célula.


Nota
Como os menus Salvar como tabela e Salvar como modo de exibição só estão disponíveis para o texto de consulta selecionado, você precisa selecionar o texto da consulta antes de usar esses menus.
Criação de Vista não oferece suporte a nomenclatura de três partes, portanto, a vista é sempre criada no armazém primário, definindo o armazém como o armazém principal.
Consulta inter-armazéns
Você pode executar a consulta entre armazéns de dados utilizando a nomenclatura de três partes. A nomenclatura de três partes consiste no nome do banco de dados, nome do esquema e nome da tabela. O nome da base de dados é o nome do armazém ou do ponto de extremidade de análise SQL, o nome do esquema é o nome do esquema, e o nome da tabela é o nome da tabela.

Ignorar a execução de código não-T-SQL
Dentro do mesmo bloco de anotações, é possível criar células de código que usam linguagens diferentes. Por exemplo, uma célula de código PySpark pode preceder uma célula de código T-SQL. Nesse caso, o usuário pode optar por ignorar a execução de qualquer código PySpark para notebook T-SQL. Essa caixa de diálogo aparece quando você executa todas as células de código clicando no botão Executar tudo na barra de ferramentas.

Monitorando a execução do notebook T-SQL
Você pode monitorar a execução de blocos de anotações T-SQL na guia T-SQL do modo de exibição Execução recente. Você pode encontrar o modo de exibição Execução recente selecionando o menu Executar dentro do bloco de anotações.

Na exibição de execução do histórico do T-SQL, você pode ver uma lista de consultas em execução, bem-sucedidas, canceladas e com falha até os últimos 30 dias.
- Use a lista suspensa para filtrar o status ou o tempo de envio.
- Use a barra de pesquisa para filtrar palavras-chave específicas no texto da consulta ou em outras colunas.
Para cada consulta, são fornecidos os seguintes detalhes:
| Nome da coluna | Descrição |
|---|---|
| ID da instrução distribuída | ID exclusivo para cada consulta |
| Texto da consulta | Texto da consulta executada (até 8.000 caracteres) |
| Tempo de envio (UTC) | Data e hora de chegada do pedido |
| Duração | Tempo necessário para a execução da consulta |
| Situação | Status da consulta (Em execução, Bem-sucedida, Falha ou Cancelada) |
| Submissor | Nome do usuário ou sistema que enviou a consulta |
| ID da sessão | ID que vincula a consulta a uma sessão de usuário específica |
| Armazém padrão | Nome do armazém que aceita a consulta submetida |
As consultas históricas podem levar até 15 minutos para aparecer na lista, dependendo da carga de trabalho simultânea que está sendo executada.
Limitações atuais
- A célula de parâmetro ainda não é suportada no notebook T-SQL. O parâmetro passado do pipeline ou do agendador não poderá ser utilizado no caderno T-SQL.
- A URL do monitor dentro da execução do pipeline ainda não é suportada no notebook T-SQL.
- O recurso de instantâneo ainda não é suportado no caderno T-SQL.
- Atualmente, a autenticação por princípios de serviço não é suportada em cadernos T-SQL.
Conteúdos relacionados
Para mais informações sobre os cadernos Fabric, consulte os seguintes artigos.
- O que é armazenamento de dados em Microsoft Fabric?
- Perguntas? Tenta perguntar à comunidade Fabric.
- Sugestões? Contribua com ideias para melhorar Fabric.