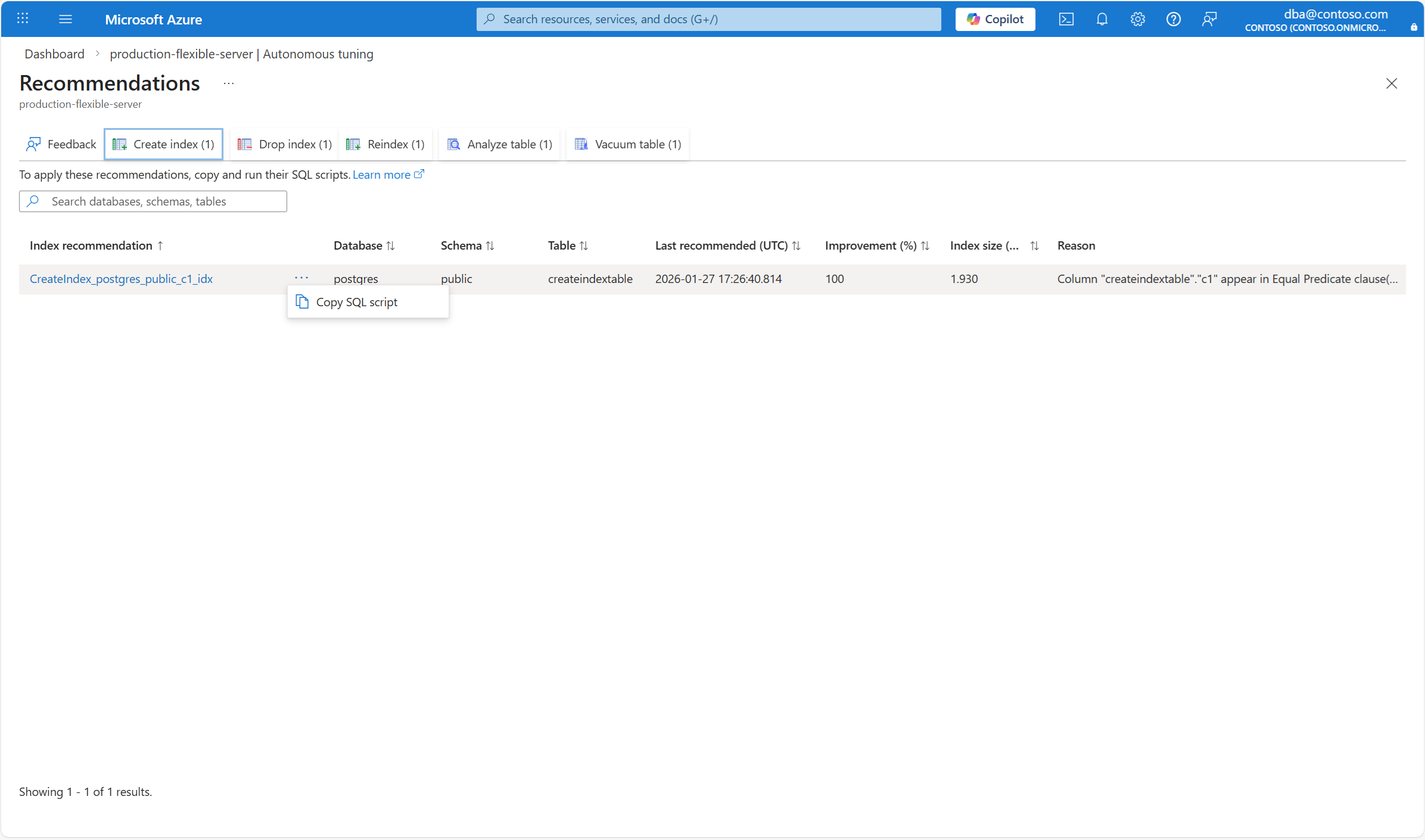
Pode listar recomendações de índice produzidas por tuning autónomo num servidor existente através do comando az postgres flexible-server autonomous-tuning list-index-recommendations.
Para listar todas as recomendações CREATE INDEX, use este comando:
az postgres flexible-server autonomous-tuning list-index-recommendations \
--resource-group <resource_group> \
--server-name <server> \
--recommendation-type createindex
O comando devolve toda a informação sobre as recomendações CREATE INDEX produzidas pela sintonia autónoma, mostrando algo semelhante ao seguinte resultado:
[
{
"analyzedWorkload": {
"endTime": "2026-01-27T14:40:18.788628+00:00",
"queryCount": 18,
"startTime": "2026-01-27T13:40:22.544654+00:00"
},
"currentState": "Active",
"details": {
"databaseName": "<database>",
"includedColumns": [
""
],
"indexColumns": [
"\"<tabe>\".\"<column>\""
],
"indexName": "<index>",
"indexType": "BTREE",
"schema": "<schema>",
"table": "<table>"
},
"estimatedImpact": [
{
"absoluteValue": 1.9296875,
"dimensionName": "IndexSize",
"queryId": null,
"unit": "MB"
},
{
"absoluteValue": 99.98674047373842,
"dimensionName": "QueryCostImprovement",
"queryId": -2000193826232128395,
"unit": "Percentage"
}
],
"id": "/subscriptions/<subscription_id>/resourceGroups/<resource_group>/providers/Microsoft.DBforPostgreSQL/flexibleServers/<server>/tuningOptions/index/recommendations/<recommendation_id>",
"implementationDetails": {
"method": "SQL",
"script": "CREATE INDEX CONCURRENTLY \"<index>\" ON \"<schema>\".\"<table>\"(\"<column>\");"
},
"improvedQueryIds": [
-2000193826232128395
],
"initialRecommendedTime": "2026-01-27T14:40:19.707617+00:00",
"kind": "",
"lastRecommendedTime": "2026-01-27T14:40:19.707617+00:00",
"name": "CreateIndex_<database>_<schema>_<index>",
"recommendationReason": "Column \"<table>\".\"<column>\" appear in Equal Predicate clause(s) in query -2000193826232128395;",
"recommendationType": "CreateIndex",
"resourceGroup": "<resource_group>",
"systemData": null,
"timesRecommended": 1,
"type": "Microsoft.DBforPostgreSQL/flexibleServers/tuningOptions/index"
},
{
.
.
.
}
]
Para listar todas as recomendações DROP INDEX, use este comando:
az postgres flexible-server autonomous-tuning list-index-recommendations \
--resource-group <resource_group> \
--server-name <server> \
--recommendation-type dropindex
O comando devolve toda a informação sobre as recomendações do DROP INDEX produzidas pela sintonia autónoma, mostrando algo semelhante ao seguinte resultado:
[
{
"analyzedWorkload": {
"endTime": "2026-01-27T19:02:47.522193+00:00",
"queryCount": 0,
"startTime": "2026-01-27T19:02:47.522193+00:00"
},
"currentState": "Active",
"details": {
"databaseName": "<database>",
"includedColumns": [
""
],
"indexColumns": [
"<column>"
],
"indexName": "<index>",
"indexType": "BTREE",
"schema": "<schema>",
"table": "<table>"
},
"estimatedImpact": [
{
"absoluteValue": 31.0,
"dimensionName": "Benefit",
"queryId": null,
"unit": "Percentage"
},
{
"absoluteValue": 0.0078125,
"dimensionName": "IndexSize",
"queryId": null,
"unit": "MB"
}
],
"id": "/subscriptions/<subscription_id>/resourceGroups/<resource_group>/providers/Microsoft.DBforPostgreSQL/flexibleServers/<server>/tuningOptions/index/recommendations/recommendations/<recommendation_id>",
"implementationDetails": {
"method": "SQL",
"script": "DROP INDEX CONCURRENTLY \"public\".\"idx_dropindextable_c2\";"
},
"improvedQueryIds": null,
"initialRecommendedTime": "2026-01-27T19:02:47.556792+00:00",
"kind": "",
"lastRecommendedTime": "2026-01-27T19:02:47.556792+00:00",
"name": "DropIndex_<database>_<schema>_<index>",
"recommendationReason": "Duplicate of \"<index>\". The equivalent index \"<index>\" has a smaller oid compared to \"<index>\".",
"recommendationType": "DropIndex",
"resourceGroup": "<resource_group>",
"systemData": null,
"timesRecommended": 5,
"type": "Microsoft.DBforPostgreSQL/flexibleServers/tuningOptions/index"
},
{
.
.
.
}
]
Para listar todas as recomendações do REINDEX, use este comando:
az postgres flexible-server autonomous-tuning list-index-recommendations \
--resource-group <resource_group> \
--server-name <server> \
--recommendation-type reindex
O comando devolve toda a informação sobre as recomendações REINDEX produzidas pela sintonia autónoma, mostrando algo semelhante ao seguinte resultado:
[
{
"analyzedWorkload": {
"endTime": "2026-01-27T19:02:47.522193+00:00",
"queryCount": 0,
"startTime": "2026-01-27T19:02:47.522193+00:00"
},
"currentState": "Active",
"details": {
"databaseName": "<database>",
"includedColumns": [
""
],
"indexColumns": [
"<column>"
],
"indexName": "<index>",
"indexType": "BTREE",
"schema": "<schema>",
"table": "<table>"
},
"estimatedImpact": [
{
"absoluteValue": 41.0,
"dimensionName": "Benefit",
"queryId": null,
"unit": "Percentage"
},
{
"absoluteValue": 0.0,
"dimensionName": "IndexSize",
"queryId": null,
"unit": "MB"
}
],
"id": "/subscriptions/<subscription_id>/resourceGroups/<resource_group>/providers/Microsoft.DBforPostgreSQL/flexibleServers/<server>/tuningOptions/index/recommendations/recommendations/<recommendation_id>",
"implementationDetails": {
"method": "SQL",
"script": "REINDEX INDEX CONCURRENTLY \"<schema>\".\"<schema>\";"
},
"improvedQueryIds": null,
"initialRecommendedTime": "2026-01-27T15:26:37.647505+00:00",
"kind": "",
"lastRecommendedTime": "2026-01-27T19:26:43.297535+00:00",
"name": "ReIndex_<database>_<schema>_<index>",
"recommendationReason": "The index is invalid and the recommended recovery method is to reindex.",
"recommendationType": "ReIndex",
"resourceGroup": "<resource_group>",
"systemData": null,
"timesRecommended": 5,
"type": "Microsoft.DBforPostgreSQL/flexibleServers/tuningOptions/index"
},
{
.
.
.
}
]
Para listar todas as recomendações do ANALYZE, use este comando:
az postgres flexible-server autonomous-tuning list-table-recommendations \
--resource-group <resource_group> \
--server-name <server> \
--recommendation-type analyzetable
O comando devolve toda a informação sobre as recomendações ANALYZE produzidas pela afinação autónoma, mostrando algo semelhante aos seguintes resultados:
[
{
"analyzedWorkload": {
"endTime": "2026-01-27T19:02:47.522193+00:00",
"queryCount": 0,
"startTime": "2026-01-27T19:02:47.522193+00:00"
},
"currentState": null,
"details": {
"databaseName": "<database>",
"includedColumns": null,
"indexColumns": null,
"indexName": null,
"indexType": null,
"schema": "<schema>",
"table": "<table>"
},
"estimatedImpact": null,
"id": "/subscriptions/<subscription_id>/resourceGroups/<resource_group>/providers/Microsoft.DBforPostgreSQL/flexibleServers/<server>/tuningOptions/index/recommendations/recommendations/<recommendation_id>",
"implementationDetails": {
"method": "SQL",
"script": "ANALYZE \"<schema>\".\"<table>\";"
},
"improvedQueryIds": [
1574410013562407420
],
"initialRecommendedTime": "2026-01-27T17:26:40.825994+00:00",
"kind": "",
"lastRecommendedTime": "2026-01-27T17:26:40.825994+00:00",
"name": "Analyze_<database>_<schema>_<table>",
"recommendationReason": "Table \"<schema>\".\"<table>\" has not been analyzed but is being used by queries: \"1574410013562407420\".",
"recommendationType": "Analyze",
"resourceGroup": "<resource_group>",
"systemData": null,
"timesRecommended": 1,
"type": "Microsoft.DBforPostgreSQL/flexibleServers/tuningOptions/table"
},
{
.
.
.
}
]
Para listar todas as recomendações do VACUUM, use este comando:
az postgres flexible-server autonomous-tuning list-table-recommendations \
--resource-group <resource_group> \
--server-name <server> \
--recommendation-type vacuumtable
O comando devolve todas as informações sobre as recomendações VACUUM produzidas pela sintonia autónoma, mostrando algo semelhante ao seguinte resultado.
[
{
"analyzedWorkload": {
"endTime": "2026-01-27T17:26:40.102894+00:00",
"queryCount": 5,
"startTime": "2026-01-27T16:26:40.102895+00:00"
},
"currentState": null,
"details": {
"databaseName": "<database>",
"includedColumns": null,
"indexColumns": null,
"indexName": null,
"indexType": null,
"schema": "<schema>",
"table": "<table>"
},
"estimatedImpact": null,
"id": "/subscriptions/<subscription_id>/resourceGroups/<resource_group>/providers/Microsoft.DBforPostgreSQL/flexibleServers/<server>/tuningOptions/table/recommendations/<recommendation_id>",
"implementationDetails": {
"method": "SQL",
"script": "VACUUM \"<schema>\".\"<table>\";"
},
"improvedQueryIds": [
-2306335776078168728
],
"initialRecommendedTime": "2026-01-27T17:26:40.823239+00:00",
"kind": "",
"lastRecommendedTime": "2026-01-27T17:26:40.823239+00:00",
"name": "Vacuum_<database>_<schema>_<table>",
"recommendationReason": "Table \"<schema>\".\"<table>\" should be vacuumed. It has an estimated size of <table_size>GB and a bloat percentage of <bloat_percentage>% (bloat size represents <bloat_size>GB).",
"recommendationType": "Vacuum",
"resourceGroup": "<resource_group>",
"systemData": null,
"timesRecommended": 1,
"type": "Microsoft.DBforPostgreSQL/flexibleServers/tuningOptions/table"
},
{
.
.
.
}
]
Usando qualquer ferramenta de cliente PostgreSQL de sua preferência:
Conecte-se ao azure_sys banco de dados disponível em seu servidor com qualquer função que tenha permissão para se conectar à instância. Os membros da função public podem ler a partir destas vistas.
Execute consultas na sessions vista para recuperar os detalhes sobre sessões de recomendação.
Execute consultas na vista recommendations para recuperar as recomendações produzidas pela otimização autónoma para CREATE INDEX, DROP INDEX e REINDEX.
Views
As visualizações na base de dados azure_sys fornecem uma forma conveniente de aceder e recuperar recomendações geradas por sintonização autónoma. Especificamente, as intelligentperformance.sessions vistas e intelligentperformance.recommendations contêm informações detalhadas sobre as recomendações CREATE INDEX, DROP INDEX, REINDEX, ANALYZE e VACUUM. Estas vistas revelam detalhes como o identificador da sessão, nome da base de dados, tipo de sessão, horários de início e fim da sessão de afinação, tipo de recomendação, razão pela qual a recomendação foi produzida e outros detalhes relevantes. Os utilizadores podem consultar estas visualizações para aceder e analisar facilmente as recomendações produzidas pela otimização autónoma.
A sessions visualização expõe todos os detalhes de todas as sessões de otimização de índices.
| nome da coluna |
tipo de dados |
Description |
| identificador_de_sessão |
Identificador Único Universal (UUID) |
Identificador universalmente único atribuído a cada nova sessão de afinação iniciada. |
| nome_da_base_de_dados |
Varchar(64) |
Nome do banco de dados em cujo contexto a sessão de ajuste de índice foi executada. |
| session_type (tipo_de_sessão) |
desempenhointeligente.tiposderecomendação |
Indica os tipos de recomendações que esta sessão de ajuste de índice pode produzir. Os valores possíveis são: CreateIndex, DropIndex, Table. Sessões do CreateIndex tipo podem produzir recomendações do CreateIndex tipo. Sessões de tipos DropIndex podem produzir recomendações de tipos DropIndex ou ReIndex. Sessões de tipos Table podem produzir recomendações de tipos Analyze ou Vacuum. |
| tipo_de_execução |
inteligentperformance.tipo_de_execução_recomendação |
Indica a forma como esta sessão foi iniciada. Os valores possíveis são: Scheduled. As sessões executadas automaticamente de acordo com o valor de index_tuning.analysis_interval, são definidas para Scheduled. |
| state |
desempenhointeligente.estado_de_recomendacao |
Indica o estado atual da sessão. Os valores possíveis são: Error, Success, InProgress. As sessões cuja execução falhou são definidas como Error. As sessões que concluíram sua execução corretamente, quer tenham gerado recomendações ou não, são definidas como Success. As sessões que ainda estão em execução são definidas como InProgress. |
| hora_de_início |
carimbo de data/hora sem fuso horário |
Carimbo de data/hora no qual a sessão de ajuste que produziu essa recomendação foi iniciada. |
| tempo_de_paragem |
carimbo de data/hora sem fuso horário |
Carimbo de data/hora no qual a sessão de ajuste que produziu essa recomendação foi iniciada. NULL se a sessão estiver em andamento ou tiver sido abortada devido a alguma falha. |
| contagem_de_recomendações |
número inteiro |
Número total de recomendações produzidas nesta sessão. |
A vista recommendations expõe todos os detalhes de todas as recomendações geradas em qualquer sessão de afinação cujos dados ainda estiverem disponíveis nas tabelas subjacentes.
| nome da coluna |
tipo de dados |
Description |
| id_recomendação |
número inteiro |
Número que identifica exclusivamente uma recomendação em todo o servidor. |
| estado_atual |
desempenhointeligente.recomendação_estado_atual |
Indica o estado atual da recomendação produzida. Os valores possíveis são: Active, Detected. |
| último_ID_de_sessão_conhecida |
Identificador Único Universal (UUID) |
A cada sessão de ajuste de índice é atribuído um Identificador Global Exclusivo. O valor desta coluna representa o da sessão que mais recentemente produziu esta recomendação. |
| último_tipo_de_sessão_conhecido |
desempenhointeligente.tiposderecomendação |
Tipo da sessão de recomendação onde a recomendação foi recomendada pela última vez. Os valores possíveis são: CreateIndex, DropIndex, ReIndex. |
| nome_da_base_de_dados |
Varchar(64) |
Nome da base de dados em cujo contexto foi produzida a recomendação. |
| tipo_de_recomendação |
desempenhointeligente.tiposderecomendação |
Indica o tipo de recomendação produzida. Os valores possíveis são: CreateIndex, DropIndex, ReIndex, AnalyzeTable, VacuumTable. |
| tempo_inicial_recomendado |
carimbo de data/hora sem fuso horário |
Carimbo de data/hora no qual a sessão de ajuste que produziu essa recomendação foi iniciada. |
| último_tempo_recomendado |
carimbo de data/hora sem fuso horário |
Carimbo de data/hora no qual a sessão de ajuste que produziu essa recomendação foi iniciada. |
| vezes_recomendadas |
número inteiro |
Carimbo de data/hora no qual a sessão de ajuste que produziu essa recomendação foi iniciada. |
| razão |
enviar SMS |
Razões que justificam a elaboração desta recomendação. |
| contexto_recomendação |
Json |
Contém a lista de identificadores de consulta para as consultas afetadas pela recomendação, o tipo de índice recomendado, o nome do esquema e o nome da tabela na qual o índice está sendo recomendado, as colunas de índice, o nome do índice e o tamanho estimado em bytes do índice recomendado. |
Razões para as recomendações do CREATE INDEX
Quando a afinação autónoma recomenda a criação de um índice, acrescenta pelo menos uma das seguintes razões:
| Reason |
Column <column> appear in Join On clause(s) in query <queryId> |
Column <column> appear in Equal Predicate clause(s) in query <queryId> |
Column <column> appear in Non-Equal Predicate clause(s) in query <queryId> |
Column <column> appear in Group By clause(s) in query <queryId> |
Column <column> appear in Order By clause(s) in query <queryId> |
Razões para as recomendações REINDEX
Quando a sintonia autónoma identifica quaisquer índices marcados como inválidos, propõe-se reindexá-los pela seguinte razão:
The index is invalid and the recommended recovery method is to reindex.
Para saber mais sobre por que e quando os índices são marcados como inválidos, consulte o REINDEX na documentação oficial do PostgreSQL.
Razões para as recomendações do DROP INDEX
Quando a sintonia autónoma deteta um índice que não está utilizado, pelo menos, durante o número de dias definidos em index_tuning.unused_min_period, propõe-se eliminá-lo pela seguinte razão:
The index is unused in the past <days_unused> days.
Quando a sintonia autónoma deteta índices duplicados, um dos duplicados sobrevive e propõe eliminar o restante. O motivo fornecido tem sempre o seguinte texto inicial:
Duplicate of <surviving_duplicate>.
Seguido por outro texto que explica a razão pela qual cada duplicado é escolhido para eliminar:
| Reason |
The equivalent index "<surviving_duplicate>" is a Primary key, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" is a unique index, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" is a constraint, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" is a valid index, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" has been chosen as replica identity, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" was used to cluster the table, while "<droppable_duplicate>" was not. |
The equivalent index "<surviving_duplicate>" has a smaller estimated size compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has more tuples compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has more index scans compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has been fetched more times compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has been read more times compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has a shorter length compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has a smaller oid compared to "<droppable_duplicate>". |
Se o índice não só for removível devido a duplicação, mas também não for utilizado durante, pelo menos, o número de dias definido em index_tuning.unused_min_period, o seguinte texto é anexado ao motivo:
Also, the index is unused in the past <days_unused> days.
Razões para as recomendações da ANALYZE
Quando a afinação autónoma deteta uma tabela referenciada numa das consultas estudadas e determina que a tabela nunca foi analisada, propõe executar o ANALYZE na tabela com a seguinte razão:
Table "<schema>"."<table>" has not been analyzed but is being used by queries: "<queryId-1>, ..., <queryId-n>"
Quando a afinação autónoma deteta uma tabela referenciada numa das consultas estudadas e determina que a tabela foi alguma vez analisada mas atualmente não possui estatísticas (quando o servidor falha antes de as estatísticas serem persistidas), propõe executar o ANALYZE na tabela com a seguinte razão:
Table "<schema>"."<table>" lacks statistics, has more than <liveRows> rows, and is used by queries: "<queryId-1>, ..., <queryId-n>"
Razões para as recomendações do VACUUM
Quando o ajuste autónomo deteta uma tabela referenciada numa das consultas estudadas e determina que a tabela está inchada e autovacuum_enabled não está definida para off ao nível do servidor, propõe executar VACUUM na tabela com a seguinte razão base:
Table "<schema>"."<table>" should be vacuumed. It has an estimated size of <estimatedSize>GB and a bloat percentage of <bloatPercentage>% (bloat size represents <bloatSize>GB).
Se o autovácuo estiver ativado ao nível do servidor e da mesa, o seguinte texto é acrescentado à razão base:
Autovacuum is enabled at both the server and table level, but appears to be falling behind.
Se o autovácuo estiver desativado ao nível da tabela, o seguinte texto é acrescentado ao motivo base:
Autovacuum is disabled at the table level.