Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Atualmente a ver:![]() versão do portal Foundry (clássica) - Trocar para a versão do novo portal Foundry
versão do portal Foundry (clássica) - Trocar para a versão do novo portal Foundry
Aprenda a afinar modelos no Microsoft Foundry para os seus conjuntos de dados e casos de uso. O ajuste fino permite:
- Resultados de melhor qualidade do que o que se pode obter só com engenharia rápida.
- A capacidade de treinar com mais exemplos do que aqueles que cabem no limite de contexto de solicitação de um modelo.
- Poupança de tokens devido a prompts mais curtos.
- Pedidos de menor latência, especialmente quando usas modelos mais pequenos.
Em contraste com a aprendizagem com poucos exemplos, o ajuste fino melhora o modelo ao treinar com mais exemplos do que os que cabem num prompt. Como os pesos adaptam-se à sua tarefa, inclui menos exemplos ou instruções. Incluir menos reduz os tokens por chamada e potencialmente reduz o custo e a latência.
Usamos adaptação de baixo nível (LoRA) para ajustar modelos de forma a reduzir a sua complexidade sem afetar significativamente o seu desempenho. Este método funciona aproximando a matriz original de alta classificação com uma de ordem inferior. Afinar um subconjunto mais pequeno de parâmetros importantes durante a fase de treino supervisionado torna o modelo mais gerível e eficiente. Para os utilizadores, também torna o treino mais rápido e acessível do que outras técnicas.
Neste artigo, aprende como:
- Escolha conjuntos de dados e formatos apropriados para ajustes finos.
- Desencadear um trabalho de ajuste fino, monitorizar o estado e obter resultados.
- Implemente e avalie um modelo afinado.
- Limpe os seus recursos quando já não precisar deles.
Existem duas experiências únicas de ajuste fino no portal Microsoft Foundry:
- Hub ou vista de projeto: Suporta afinamento de modelos de múltiplos fornecedores, como Azure OpenAI, Meta Llama e Microsoft Phi.
Visão centrada no Azure OpenAI : Suporta apenas o ajuste fino dos modelos Azure OpenAI, mas suporta funcionalidades adicionais como a integração de visualização prévia doWeights & Biases (W&B) . Se está apenas a afinar modelos Azure OpenAI, recomendamos esta experiência.
Importante
Os itens marcados (pré-visualização) neste artigo encontram-se atualmente em pré-visualização pública. Esta pré-visualização é fornecida sem um acordo de nível de serviço, e não a recomendamos para cargas de trabalho em produção. Certas funcionalidades podem não ser suportadas ou podem ter capacidades limitadas. Para mais informações, consulte Termos de Utilização Suplementares para Microsoft Azure Pré-visualizações.
Pré-requisitos
- Leia o guia sobre quando usar a afinação do Azure OpenAI.
- Precisas de uma subscrição do Azure. Crie um gratuitamente.
- Precisas de um recurso Azure OpenAI localizado numa região que suporte o ajuste fino do modelo Azure OpenAI. Para a lista de modelos disponíveis por região e funcionalidades suportadas, consulte a tabela de resumo de modelos e a disponibilidade por região. Para mais informações, consulte Crie um recurso e implemente um modelo com Azure OpenAI.
- O ajuste fino requer o papel de Proprietário da IA Azure. Embora os Utilizadores de IA do Azure possam treinar (ajustar finamente) modelos, apenas os Proprietários de IA podem implementá-los.
- Se ainda não tiver acesso para ver quotas e implementar modelos no portal Foundry, precisa de mais permissões.
Modelos suportados
Para verificar quais as regiões que atualmente suportam ajuste fino, consulte o artigo sobre modelos.
Ou pode afinar finamente um modelo previamente ajustado, formatado como base-model.ft-{jobid}.
Revise o fluxo de trabalho do portal Foundry
Reserve um momento para rever o fluxo de trabalho de ajuste fino para usar o portal Foundry:
- Prepare os dados de treino e validação.
- Use a caixa de diálogo Criar um modelo finamente ajustado no portal Foundry para treinar o seu modelo personalizado.
- Escolha um método de treino.
- Escolhe um modelo base.
- Escolha o seu tipo de treino.
- Escolha os seus dados de treino.
- Opcionalmente, escolha os seus dados de validação.
- Opcionalmente, configure os parâmetros da tarefa para o seu trabalho de afinação.
- Opcionalmente, ative a implementação automática do modelo personalizado resultante.
- Revise as suas escolhas e treine o seu novo modelo personalizado.
- Verifique a situação do seu modelo personalizado ajustado.
- Implemente o seu modelo personalizado para uso.
- Usa o teu modelo personalizado.
- Opcionalmente, analisa o teu modelo personalizado quanto ao desempenho e ao ajuste.
Prepare os seus dados de treino e validação
Os seus conjuntos de dados de treino e validação consistem em exemplos de entrada e saída de como deseja que o modelo execute.
Os dados de treino e validação que utiliza devem ser formatados como um documento de Linhas JSON (JSONL). Deve também ser formatado no formato conversacional que a API de Conversas Completas utiliza.
Para além do formato JSONL, os ficheiros de dados de treino e validação devem ser codificados em UTF-8 e incluir uma marca de ordem de bytes (BOM). Cada ficheiro deve ter menos de 512 MB.
De um modo geral, recomendamos que utilize as instruções e prompts que achou que funcionaram melhor em todos os exemplos de treino. Esta abordagem ajuda-o a obter os melhores resultados, especialmente se tiver menos de cem exemplos.
Formato de ficheiro de exemplo
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who discovered Antarctica?"}, {"role": "assistant", "content": "Some chaps named Fabian Gottlieb von Bellingshausen and Mikhail Lazarev, as if they don't teach that in every school!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the biggest ocean?"}, {"role": "assistant", "content": "The Pacific Ocean. It's not like it's a small pond or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest planet?"}, {"role": "assistant", "content": "It's called Jupiter, you might have heard of it...or not."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who painted the Mona Lisa?"}, {"role": "assistant", "content": "Oh, some obscure artist named Leonardo da Vinci. Not that he is famous or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the boiling point of water?"}, {"role": "assistant", "content": "Exciting fact of the day: it's 100 degrees Celsius. Life-changing, isn't it?"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'The Odyssey'?"}, {"role": "assistant", "content": "Oh, just some poet named Homer. Nothing special, really."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest mammal?"}, {"role": "assistant", "content": "Blue Whale. Quite a big fish isn't it? Oh wait, it's not a fish!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the highest mountain peak?"}, {"role": "assistant", "content": "Everest. Brace yourself, it's not a walk in the park."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who invented the telephone?"}, {"role": "assistant", "content": "A guy named Alexander Graham Bell. Bet you didn't guess that one!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the distance from Earth to the Sun?"}, {"role": "assistant", "content": "About 93 million miles. Just a quick drive, really."}]}
Formato de ficheiro de chat múltiplos turnos para Azure OpenAI
Também são suportados múltiplos turnos de uma conversa numa única linha do seu ficheiro de treino JSONL. Para evitar ajustes finos em mensagens específicas do assistente, adicione o par opcional weight chave/valor. Atualmente, weight pode ser definido como 0 ou 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital/major city of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Finalizações de conversas com capacidades visuais
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Considerações sobre o tamanho do conjunto de dados
Quanto mais exemplos de treino tiveres, melhor. Os trabalhos de ajuste fino não avançam sem pelo menos 10 exemplos de treino, mas um número tão pequeno não é suficiente para influenciar de forma notória as respostas do modelo. Uma boa prática para um ajuste fino bem-sucedido é fornecer centenas, senão milhares, de exemplos de treino. Recomendamos que comece com 50 exemplos bem elaborados.
Em geral, duplicar o tamanho do conjunto de dados pode levar a um aumento linear da qualidade do modelo. Mas tenha em mente que exemplos de baixa qualidade podem afetar negativamente o desempenho. Se treinar o modelo com uma grande quantidade de dados internos sem primeiro podar o conjunto de dados apenas para os exemplos de maior qualidade, o seu modelo pode ter um desempenho pior do que o esperado.
Criar um modelo afinado
O portal Foundry disponibiliza o diálogo Criar um modelo fino para que possa criar e treinar um modelo afinado para o seu recurso de Azure num só local.
Vá ao portal Foundry e inicie sessão com credenciais que tenham acesso ao seu recurso Azure OpenAI. Durante o fluxo de início de sessão, selecione o diretório apropriado, a subscrição do Azure e o recurso do Azure OpenAI.
Acede a Ferramentas>Ajuste-Fino, e depois selecionar modelo de Ajuste-Fino.

Seleciona um modelo para afinar e depois seleciona Próximo.

Aparece a caixa de diálogo Criar um modelo afinado.



Escolha o seu método de treino
O primeiro passo é confirmar a escolha do modelo e o método de treino. Nem todos os modelos suportam todos os métodos de treino.
- Ajuste fino supervisionado: Suportado por todos os modelos não direcionados ao raciocínio.
- Otimização direta de preferências (pré-visualização): Suportado por GPT-4o.
- Ajuste fino de reforço: Suportado por modelos de raciocínio, como o4-mini.
Ao selecionar o modelo, também pode selecionar um modelo previamente ajustado, conforme descrito mais adiante neste artigo.
Escolha o seu tipo de treino
A Foundry oferece três níveis de formação para satisfazer as necessidades dos clientes.
Nível de treino padrão
O nível Standard oferece capacidade dedicada para ajustes finos com desempenho e SLAs previsíveis. É ideal para cargas de trabalho de produção que exigem rendimento garantido.
Nível de formação Global Standard
O nível de Formação Global expande o alcance da personalização de modelos com os preços mais acessíveis de outras ofertas globais. Não oferece residência de dados. Se precisar de residência de dados, consulte a lista de regiões disponíveis para o modelo escolhido.
Os seus dados de treino e os pesos do modelo resultante podem ser copiados para outra região do Azure.
Quando usa este nível, pode:
- Treine os modelos OpenAI mais recentes de mais de uma dúzia de regiões Azure OpenAI.
- Beneficie de taxas de treino por token mais baixas em comparação com o nível Standard.
Nível de formação para programadores
O nível Developer é uma opção económica que utiliza capacidade inativa para cargas de trabalho não urgentes ou exploratórias. Tarefas neste nível podem ser interrompidas e retomadas mais tarde, por isso é ideal para experimentação e casos de uso sensíveis a custos.
Escolha os seus dados de treino
O passo seguinte é escolher os dados de treino preparados existentes ou carregar novos dados preparados para usar quando estiver a personalizar o seu modelo, selecionando Adicionar dados de treino.
O diálogo de dados de treino mostra quaisquer conjuntos de dados existentes e previamente carregados. Também oferece opções para carregar novos dados de treino.

Se os seus dados de treino já forem carregados no serviço, selecione Ficheiros do recurso Connected AI. Em seguida, selecione o ficheiro da lista suspensa.
Para carregar novos dados de treino, utilize uma das seguintes opções:
- Selecione Carregar ficheiros para carregar dados de treino a partir de um ficheiro local.
- Selecione Azure blob ou outras localizações web partilhadas para importar dados de treino de Armazenamento de Blobs do Azure ou de outra localização web partilhada.
Para ficheiros de dados grandes, recomendamos que importe do Armazenamento de Blobs. Ficheiros grandes podem tornar-se instáveis quando se carregam através de formulários multipartes porque os pedidos são atómicos e não podem ser repetidos ou reiniciados. Para mais informações sobre Armazenamento de Blobs, veja O que é Armazenamento de Blobs do Azure?.
Escolha os seus dados de validação (opcional)
Se tiver um conjunto de dados de validação, selecione Adicionar dados de treino. Pode escolher dados de validação preparados existentes ou carregar novos dados de validação preparados para usar quando estiver a personalizar o seu modelo.
O diálogo de Dados de Validação mostra quaisquer conjuntos de dados de treino e validação existentes e previamente carregados. Também oferece opções para carregar novos dados de validação.

Se os seus dados de validação já forem carregados para o serviço, selecione Escolher conjunto de dados. Depois seleciona o ficheiro na lista suspensa.
Para carregar novos dados de validação, utilize uma das seguintes opções:
- Selecione ficheiro Local para carregar dados de validação a partir de um ficheiro local.
- Selecione Azure blob ou outras localizações web partilhadas para importar dados de validação de Armazenamento de Blobs do Azure ou de outra localização web partilhada.
Para ficheiros de dados grandes, recomendamos que importe do Armazenamento de Blobs. Ficheiros grandes podem tornar-se instáveis quando se carregam através de formulários multipartes porque os pedidos são atómicos e não podem ser repetidos ou reiniciados.
Torne o seu modelo identificável (opcional)
Recomendamos que inclua um suffix parâmetro para distinguir mais facilmente entre iterações do seu modelo afinado. Um suffix parâmetro utiliza uma sequência de até 18 caracteres e é usado para nomear o modelo finamente ajustado resultante.
Configurar parâmetros de treino (opcional)
Podes fornecer uma seed opcional e ajustar hiperparâmetros adicionais.
Uma semente controla a reprodutibilidade do trabalho. Passar os mesmos parâmetros de semente e de trabalho deverá produzir os mesmos resultados, mas poderão diferir em casos raros. Se não especificares uma semente, uma é gerada aleatoriamente para ti.
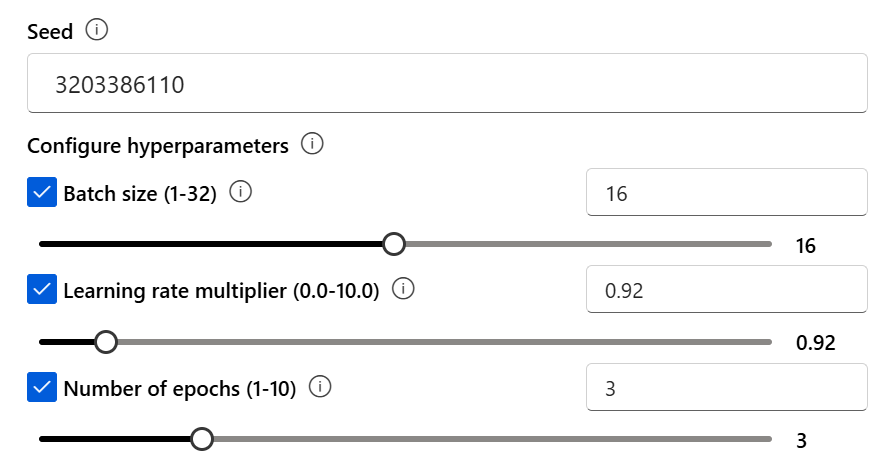
Os seguintes hiperparâmetros estão disponíveis para ajuste através do portal Foundry:
| Nome | Tipo | Descrição |
|---|---|---|
| Tamanho do lote | Integer | O tamanho do lote a usar para treino. O tamanho do lote é o número de exemplos de treino usados para treinar uma única passagem para a frente e para trás. Em geral, verificamos que lotes maiores tendem a funcionar melhor para conjuntos de dados maiores. O valor padrão e o valor máximo desta propriedade são específicos de um modelo base. Um tamanho de lote maior significa que os parâmetros do modelo são atualizados com menos frequência, mas com menor variância. |
| Multiplicador de taxa de aprendizagem | Número | O multiplicador de taxa de aprendizagem para usar no treino. A taxa de aprendizagem usada para ajuste fino é a taxa de aprendizagem original utilizada no pré-treino, multiplicada por este valor. Taxas de aprendizagem mais elevadas tendem a ter melhor desempenho com lotes maiores. Recomendamos experimentar valores no intervalo de 0,02 a 0,2 para ver o que produz os melhores resultados. Uma taxa de aprendizagem mais baixa pode ser útil para evitar o sobreajuste. |
| Número de épocas | Integer | O número de épocas para treinar o modelo. No contexto do machine learning, um "epoch" refere-se a um ciclo inteiro de treino através do conjunto de dados. |
Ativar implementação automática (opcional)
Para poupar tempo, pode, opcionalmente, ativar a implementação automática do modelo resultante. Se o treino terminar com sucesso, o modelo é implementado de acordo com o tipo de implementação selecionado. O nome da implementação baseia-se no nome único gerado para o seu modelo personalizado e no sufixo opcional que poderá ter fornecido anteriormente.

Nota
Atualmente, apenas as implementações "Global Standard" e "Developer" são suportadas para distribuição automática. Nenhuma destas opções oferece residência de dados. Para mais informações, consulte a documentação sobre os tipos de implementação.
Revê as tuas escolhas e treina o teu modelo
Revê as tuas escolhas e depois seleciona Enviar para começar a treinar o teu novo modelo afinado.
Verifique o estado do seu modelo personalizado
Depois de submeteres o teu trabalho de afinação, aparece uma página com detalhes sobre o teu modelo afinado. Pode encontrar o estado e mais informações sobre o seu modelo afinado na página de Fine-tuning no portal da Foundry.
O teu trabalho pode estar colocado atrás de outros empregos no sistema. Treinar o seu modelo pode demorar minutos ou horas, dependendo do modelo e do tamanho do conjunto de dados.
Gerar pontos de controlo
Quando cada época de treino termina, é gerado um ponto de controlo. Um checkpoint é uma versão totalmente funcional de um modelo que pode ser tanto implementada como usada como modelo-alvo para trabalhos subsequentes de ajuste fino.
Os checkpoints podem ser particularmente úteis, pois podem fornecer instantâneos antes do sobreajuste. Quando um trabalho de afinação termina, tens as três versões mais recentes do modelo disponíveis para implementar. Pode copiar checkpoints entre recursos e subscrições usando a API REST.
Pausa e retoma
Pode acompanhar o progresso tanto nas visões de otimização do portal da Foundry. O seu trabalho passa pelos mesmos estados que os trabalhos normais de ajuste fino (Em Fila, Em Execução, Bem Sucedido).
Também pode rever os ficheiros de resultados durante os treinos, para ter uma ideia do progresso e se o seu treino está a decorrer como esperado.
Durante a formação, pode visualizar as métricas e pausar o trabalho conforme necessário. Pausar pode ser útil se as métricas não convergirem ou se sentires que o modelo não está a aprender ao ritmo certo. Quando pausa uma tarefa de treinamento, é criado um ponto de controlo implantável após a conclusão das avaliações de segurança. Este checkpoint está disponível para implementares e usares para inferência, ou podes retomar o trabalho para o concluir. A operação de pausa é aplicável apenas a tarefas treinadas para pelo menos um passo e que estão em estado Em execução.

Analise o seu modelo personalizado
Azure OpenAI anexa um ficheiro de resultado chamado results.csv a cada tarefa de ajuste fino após a sua conclusão. Pode usar o ficheiro de resultados para analisar o desempenho de treino e validação do seu modelo personalizado. O ID do ficheiro de resultados está listado para cada modelo personalizado na coluna ID do ficheiro de resultados no painel Modelos do portal Foundry. Pode usar o ID do ficheiro para identificar e descarregar o ficheiro de resultado a partir do painel de ficheiros de dados do portal Foundry.
O ficheiro de resultados é um ficheiro CSV que contém uma linha de cabeçalho e uma linha para cada passo de treino realizado pelo trabalho de ajuste fino. O ficheiro de resultados contém as seguintes colunas:
| Nome da coluna | Descrição |
|---|---|
step |
O número da etapa de formação. Um passo de treino representa uma única passagem, para a frente e para trás, sobre um lote de dados de treino. |
train_loss |
A perda para a turma de treino. |
train_mean_token_accuracy |
A percentagem de tokens no lote de treino que o modelo previu corretamente. Por exemplo, se o tamanho do lote estiver definido como 3 e os seus dados conterem completações [[1, 2], [0, 5], [4, 2]], este valor é definido para 0.83 (5 de 6) se o modelo previu [[1, 1], [0, 5], [4, 2]]. |
valid_loss |
A perda para o lote de validação. |
validation_mean_token_accuracy |
A percentagem de tokens no lote de validação que o modelo previu corretamente. Por exemplo, se o tamanho do lote estiver definido como 3 e os seus dados conterem completações [[1, 2], [0, 5], [4, 2]], este valor é definido para 0.83 (5 de 6) se o modelo previu [[1, 1], [0, 5], [4, 2]]. |
full_valid_loss |
A perda de validação calculada no final de cada época. Quando o treino corre bem, a perda deverá diminuir. |
full_valid_mean_token_accuracy |
A precisão média válida dos tokens calculada no final de cada época. Quando o treino está a correr bem, a precisão dos tokens deve aumentar. |
Também pode visualizar os dados no seu results.csv ficheiro como gráficos no portal Foundry. Quando seleciona o link do seu modelo treinado, aparecem três gráficos: perda, precisão média do token e precisão do token. Se forneceu dados de validação, ambos os conjuntos de dados aparecem no mesmo gráfico.
Espera que a tua perda diminua com o tempo e que a tua precisão aumente. Se os teus dados de treino e validação divergem, podes estar a sobreajustar. Tenta treinar com menos épocas ou com um multiplicador de taxa de aprendizagem mais pequeno.
Implementar um modelo afinado
Quando estiver satisfeito com as métricas do seu trabalho de ajuste fino, ou simplesmente quiser avançar para inferência, deve implementar o modelo.
Se estiver a implementar para validação adicional, considere implementar para testes usando uma implementação de desenvolvedor.
Se estiver pronto para implementar para produção ou tiver necessidades específicas de residência de dados, siga o guia de implementação.
Utilizar um modelo implementado ajustado finamente
Depois de implementares o teu modelo afinado, podes usá-lo como qualquer outro modelo implementado. Podes usar o playground no Foundry para experimentar a tua nova implementação. Também pode usar a API REST para chamar o seu modelo finamente ajustado a partir da sua própria aplicação. Pode até começar a usar este novo modelo afinado no seu fluxo de prompts para construir a sua aplicação de IA generativa.
Nota
Para modelos de chat, a mensagem do sistema que usas para guiar o teu modelo afinado (quer esteja implementado ou disponível para testes no playground) deve ser a mesma da mensagem do sistema que usaste para o treino. Se usar uma mensagem de sistema diferente, o modelo pode não funcionar como esperado.
Realizar ajustes finos contínuos
Depois de criar um modelo afinado, pode querer continuar a refinar o modelo ao longo do tempo através de mais ajustes finos. O ajuste fino contínuo é o processo iterativo de selecionar um modelo já afinado como modelo base e afiná-lo ainda mais em novos conjuntos de exemplos de treino.
Para realizar afinação fina num modelo que previamente ajustou, utiliza-se o mesmo processo descrito em Criar um modelo finamente ajustado. Mas em vez de especificar o nome de um modelo base genérico, especifica o seu modelo já afinado. Um modelo personalizado afinado parece-se com gpt-4o-2024-08-06.ft-d93dda6110004b4da3472d96f4dd4777-ft.

Limpa as tuas implementações, modelos personalizados e ficheiros de treino
Quando já não precisares do teu modelo personalizado, podes eliminar a implementação e o modelo. Também pode apagar os ficheiros de treino e validação que carregou para o serviço, se necessário.
Apague a implementação do seu modelo
Importante
Depois de implementar um modelo personalizado, se em algum momento a implementação permanecer inativa por mais de 15 dias, a implementação é eliminada. A implementação de um modelo personalizado está inativa se o modelo foi implementado há mais de 15 dias e não foram feitas chamadas de chat ou respostas à API durante um período contínuo de 15 dias.
A eliminação de uma implementação inativa não apaga nem afeta o modelo personalizado subjacente. O modelo personalizado pode ser redistribuído a qualquer momento.
Como descrito em Preços do Azure OpenAI nos Modelos Microsoft Foundry, cada modelo personalizado (ajustado) implementado implica um custo horário de hospedagem, independentemente de serem feitas chamadas de chat ou chamadas à API de resposta ao modelo. Para saber mais sobre planeamento e gestão de custos com Azure OpenAI, consulte Planear e gerir custos para Azure OpenAI.
Podes eliminar a implementação do teu modelo personalizado no painel de Implementações no portal Foundry. Selecione a implementação a eliminar e depois selecione Eliminar.
Apague o seu modelo personalizado
Podes eliminar um modelo personalizado no painel de Modelos no portal Foundry. Selecione o modelo personalizado a eliminar no separador Modelos Personalizados e depois selecione Eliminar.
Nota
Não podes eliminar um modelo personalizado se este tiver uma implementação existente. Tens de eliminar a implementação do teu modelo antes de poderes eliminar o teu modelo personalizado.
Apague os seus ficheiros de treino
Pode, opcionalmente, eliminar ficheiros de treino e validação que carregou para treino, juntamente com ficheiros de resultados gerados durante o treino, no painel Gestão>Dados + índices do portal Foundry. Seleciona o ficheiro a eliminar e depois seleciona Apagar.







Pré-requisitos
- Leia o guia sobre quando usar a afinação do Azure OpenAI.
- Precisas de uma subscrição do Azure. Crie um gratuitamente.
- Precisas de um recurso Azure OpenAI. Para mais informações, consulte Crie um recurso e implemente um modelo com Azure OpenAI.
- Precisa das seguintes bibliotecas Python:
os,json,requests,openai. - Precisas da biblioteca Python da OpenAI.
- O ajuste fino requer o papel de Proprietário da IA Azure. Embora os Utilizadores de IA do Azure possam treinar (ajustar finamente) modelos, apenas os Proprietários de IA podem implementá-los.
- Se ainda não tiver acesso para ver quotas e implementar modelos no portal Foundry, precisa de mais permissões.
Modelos suportados
Para verificar quais as regiões que atualmente suportam ajuste fino, consulte o artigo sobre modelos.
Ou pode afinar finamente um modelo previamente ajustado, formatado como base-model.ft-{jobid}.
Revê o fluxo de trabalho do SDK Python
Tire um momento para rever o fluxo de trabalho de afinação ao usar o SDK Python com Azure OpenAI.
- Prepare os dados de treino e validação.
- Escolhe um modelo base.
- Carregue os seus dados de treino.
- Treine o seu novo modelo personalizado.
- Verifique o estado do seu modelo personalizado.
- Implemente o seu modelo personalizado para uso.
- Use o seu modelo personalizado.
- Opcionalmente, analisa o teu modelo personalizado quanto ao desempenho e ao ajuste.
Prepare os seus dados de treino e validação
Os seus conjuntos de dados de treino e validação consistem em exemplos de entrada e saída de como deseja que o modelo execute.
Os dados de treino e validação que utiliza devem ser formatados como um documento de Linhas JSON (JSONL). Deve também ser formatado no formato conversacional que a API de Conversas Completas utiliza.
Para além do formato JSONL, os ficheiros de dados de treino e validação devem ser codificados em UTF-8 e incluir uma marca de ordem de bytes (BOM). Cada ficheiro deve ter menos de 512 MB.
Se quiseres um guia passo a passo sobre o ajuste fino gpt-4o-mini-2024-07-18, vê o tutorial de ajuste fino Azure OpenAI.
Formato de ficheiro de exemplo
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who discovered Antarctica?"}, {"role": "assistant", "content": "Some chaps named Fabian Gottlieb von Bellingshausen and Mikhail Lazarev, as if they don't teach that in every school!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the biggest ocean?"}, {"role": "assistant", "content": "The Pacific Ocean. It's not like it's a small pond or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest planet?"}, {"role": "assistant", "content": "It's called Jupiter, you might have heard of it...or not."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who painted the Mona Lisa?"}, {"role": "assistant", "content": "Oh, some obscure artist named Leonardo da Vinci. Not that he is famous or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the boiling point of water?"}, {"role": "assistant", "content": "Exciting fact of the day: it's 100 degrees Celsius. Life-changing, isn't it?"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'The Odyssey'?"}, {"role": "assistant", "content": "Oh, just some poet named Homer. Nothing special, really."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest mammal?"}, {"role": "assistant", "content": "Blue Whale. Quite a big fish, isn't it? Oh wait, it's not a fish!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the highest mountain peak?"}, {"role": "assistant", "content": "Everest. Brace yourself, it's not a walk in the park."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who invented the telephone?"}, {"role": "assistant", "content": "A guy named Alexander Graham Bell. Bet you didn't guess that one!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the distance from Earth to the Sun?"}, {"role": "assistant", "content": "About 93 million miles. Just a quick drive, really."}]}
Formato de ficheiro de conversas de múltiplas voltas
Também são suportados múltiplos turnos de uma conversa numa única linha do seu ficheiro de treino JSONL. Para evitar ajustes finos em mensagens específicas do assistente, adicione o par opcional weight chave/valor. Atualmente, weight pode ser definido como 0 ou 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital/major city of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Finalizações de conversas com capacidades visuais
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Crie os seus conjuntos de dados de treino e validação
Quanto mais exemplos de treino tiveres, melhor. Os trabalhos de ajuste fino não avançam sem pelo menos 10 exemplos de treino, mas um número tão pequeno não é suficiente para influenciar de forma notória as respostas do modelo. Uma boa prática para um ajuste fino bem-sucedido é fornecer centenas, senão milhares, de exemplos de treino.
Em geral, duplicar o tamanho do conjunto de dados pode levar a um aumento linear da qualidade do modelo. Mas tenha em mente que exemplos de baixa qualidade podem afetar negativamente o desempenho. Se treinar o modelo com uma grande quantidade de dados internos sem primeiro podar o conjunto de dados apenas para os exemplos de maior qualidade, o seu modelo pode ter um desempenho pior do que o esperado.
Carregue os seus dados de treino
O passo seguinte é escolher os dados de treino preparados existentes ou carregar novos dados preparados para usar quando estiver a personalizar o seu modelo. Depois de preparar os seus dados de treino, pode carregar os seus ficheiros para o serviço. Existem duas formas de carregar dados de treino:
- A partir de um ficheiro local
- De Armazenamento de Blobs do Azure ou de uma localização web (importação)
Para ficheiros de dados grandes, recomendamos que importe do Armazenamento de Blobs. Ficheiros grandes podem tornar-se instáveis quando se carregam através de formulários multipartes porque os pedidos são atómicos e não podem ser repetidos ou reiniciados. Para mais informações sobre Armazenamento de Blobs, veja O que é Armazenamento de Blobs do Azure?.
O exemplo seguinte de Python carrega ficheiros locais de treino e validação usando o SDK Python, e recupera os IDs dos ficheiros devolvidos:
import os
from openai import OpenAI
# Load the OpenAI client
client = OpenAI(
api_key = os.getenv("AZURE_OPENAI_API_KEY"),
base_url="https://YOUR-RESOURCE-NAME.openai.azure.com/openai/v1/"
)
# Upload the training and validation dataset files to Microsoft Foundry with the SDK.
training_file_name = 'training_set.jsonl'
validation_file_name = 'validation_set.jsonl'
training_response = client.files.create(file=open(training_file_name, "rb"), purpose="fine-tune")
validation_response = client.files.create(file=open(validation_file_name, "rb"), purpose="fine-tune")
training_file_id = training_response.id
validation_file_id = validation_response.id
print("Training file ID:", training_file_id)
print("Validation file ID:", validation_file_id)
Crie um modelo personalizado
Depois de carregares os teus ficheiros de treino e validação, estás pronto para começar o trabalho de afinação.
O seguinte código Python mostra um exemplo de como criar um novo trabalho de ajuste fino usando o SDK Python:
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model="gpt-4.1-2025-04-14", # Enter the base model name.
suffix="my-model", # Custom suffix for naming the resulting model. Note that in Microsoft Foundry, the model can't contain dot/period characters.
seed=105, # Seed parameter controls reproducibility of the fine-tuning job. If you don't specify a seed, one is generated automatically.
extra_body={ "trainingType": "GlobalStandard" } # Change this value to your preferred training type. Other options are `Standard` and `Developer`.
)
job_id = response.id
# You can use the job ID to monitor the status of the fine-tuning job.
# The fine-tuning job takes some time to start and finish.
print("Job ID:", response.id)
print(response.model_dump_json(indent=2))
Nota
Recomendamos o uso do nível Global Standard para o tipo de formação, pois oferece poupanças de custos e utiliza a capacidade global para tempos de fila mais rápidos. No entanto, copia dados e pesos fora da região atual de recursos. Se a residência de dados for um requisito, utilize um modelo que suporte formação de nível Standard.
Também pode passar parâmetros opcionais adicionais, como hiperparâmetros, para obter maior controlo do processo de afinação. Para o treino inicial, recomendamos usar os valores automáticos que estão presentes sem especificar esses parâmetros.
Os hiperparâmetros atualmente suportados para ajuste fino supervisionado são:
| Nome | Tipo | Descrição |
|---|---|---|
batch_size |
Integer | O tamanho do lote a usar para treino. O tamanho do lote é o número de exemplos de treino usados para treinar uma única passagem para a frente e para trás. Em geral, verificamos que lotes maiores tendem a funcionar melhor para conjuntos de dados maiores. O valor padrão e o valor máximo desta propriedade são específicos de um modelo base. Um tamanho de lote maior significa que os parâmetros do modelo são atualizados com menos frequência, mas com menor variância. |
learning_rate_multiplier |
Número | O multiplicador de taxa de aprendizagem para usar no treino. A taxa de aprendizagem usada para ajuste fino é a taxa de aprendizagem original utilizada no pré-treino, multiplicada por este valor. Taxas de aprendizagem mais elevadas tendem a ter melhor desempenho com lotes maiores. Recomendamos experimentar valores no intervalo de 0.02 para 0.2 ver o que produz os melhores resultados. Uma taxa de aprendizagem mais baixa pode ser útil para evitar o sobreajuste. |
n_epochs |
Integer | O número de épocas para treinar o modelo. No contexto do machine learning, um "epoch" refere-se a um ciclo inteiro de treino através do conjunto de dados. |
seed |
Integer | A semente que controla a reprodutibilidade do trabalho. Passar os mesmos parâmetros de semente e de trabalho deverá produzir os mesmos resultados, mas poderão diferir em casos raros. Se não especificares uma semente, é gerada uma para ti. |
Para definir hiperparâmetros personalizados com a versão 1.x da API OpenAI Python, forneça-os como parte do method:
client.fine_tuning.jobs.create(
training_file="file-abc123",
model="gpt-4.1-2025-04-14",
suffix="my-model",
seed=105,
method={
"type": "supervised", # In this case, the job is using supervised fine-tuning.
"supervised": {
"hyperparameters": {
"n_epochs": 2
}
}
},
extra_body={ "trainingType": "GlobalStandard" }
)
Para saber sobre os hiperparâmetros suportados para os outros métodos de personalização, consulte o guia para otimização direta de preferências e o guia para ajuste fino de reforços.
Tipo de treino
Selecione o nível de formação com base no seu caso de uso e orçamento:
Padrão: A formação ocorre na região atual do recurso Foundry e garante a residência dos dados. Ideal para cargas de trabalho onde os dados têm de permanecer numa região específica.
Global: Oferece preços mais acessíveis em comparação com o Standard, utilizando capacidade para além da sua região atual. Os dados e pesos são copiados para a região onde ocorre o treino. Ideal se a residência de dados não for uma restrição e quiseres tempos de fila mais rápidos.
Developer (versão de pré-visualização): Oferece uma redução significativa de custos ao utilizar a capacidade de inatividade para treino. Não há garantias de latência ou SLA, por isso os empregos neste nível podem ser automaticamente preemptados e retomados mais tarde. Não há garantias de residência dos dados. Ideal para experimentação e cargas de trabalho sensíveis a preços.
import openai
from openai import AzureOpenAI
base_uri = "https://<ACCOUNT-NAME>.services.ai.azure.com"
api_key = "<API-KEY>"
api_version = "2025-04-01-preview"
client = AzureOpenAI(
azure_endpoint=base_uri,
api_key=api_key,
api_version=api_version
)
try:
client.fine_tuning.jobs.create(
model="gpt-4.1-mini",
training_file="<FILE-ID>",
extra_body={"trainingType": "developerTier"}
)
except openai.APIConnectionError as e:
print("The server could not be reached")
print(e.__cause__) # An underlying exception, likely raised within httpx.
except openai.RateLimitError as e:
print("A 429 status code was received; we should back off a bit.")
except openai.APIStatusError as e:
print("Another non-200-range status code was received")
print(e.status_code)
print(e.response)
print(e.body)
Verifique o estado do ajuste fino do processo
response = client.fine_tuning.jobs.retrieve(job_id)
print("Job ID:", response.id)
print("Status:", response.status)
print(response.model_dump_json(indent=2))
Lista de eventos de ajuste fino
Para examinar os eventos individuais de ajuste fino gerados durante o treino, execute o seguinte comando. Antes de executar o comando, pode ser necessário atualizar a biblioteca cliente OpenAI para a versão mais recente usando pip install openai --upgrade.
response = client.fine_tuning.jobs.list_events(fine_tuning_job_id=job_id, limit=10)
print(response.model_dump_json(indent=2))
Listar pontos de controlo
A conclusão de cada época de aprendizagem gera um ponto de verificação. Um checkpoint é uma versão totalmente funcional de um modelo que pode ser tanto implementada como usada como modelo-alvo para trabalhos subsequentes de ajuste fino. Os checkpoints podem ser particularmente úteis, pois podem fornecer instantâneos antes do sobreajuste.
Quando um trabalho de afinação termina, tens as três versões mais recentes do modelo disponíveis para implementar. O seu modelo afinado representa a época final. As duas épocas anteriores estão disponíveis como pontos de controlo.
Pode executar o comando seguinte para recuperar a lista de pontos de verificação associados a um trabalho individual de ajuste fino. Antes de executar o comando, pode ser necessário atualizar a biblioteca cliente OpenAI para a versão mais recente usando pip install openai --upgrade.
response = client.fine_tuning.jobs.checkpoints.list(job_id)
print(response.model_dump_json(indent=2))
Analise o seu modelo personalizado
Azure OpenAI anexa um ficheiro de resultado chamado results.csv a cada tarefa de ajuste fino após a sua conclusão. Pode usar o ficheiro de resultados para analisar o desempenho de treino e validação do seu modelo personalizado. O ID do ficheiro do resultado está listado para cada modelo personalizado. Podes usar o SDK Python para recuperar o ID do ficheiro e descarregar o ficheiro de resultados para análise.
O exemplo seguinte em Python recupera o ID do ficheiro do primeiro resultado anexado ao trabalho de ajuste fino para o seu modelo personalizado. Depois, utiliza o SDK Python para descarregar o ficheiro para o seu diretório de trabalho atual para análise.
# Retrieve the file ID of the first result file from the fine-tuning job
# for the customized model.
response = client.fine_tuning.jobs.retrieve(job_id)
if response.status == 'succeeded':
result_file_id = response.result_files[0]
retrieve = client.files.retrieve(result_file_id)
# Download the result file.
print(f'Downloading result file: {result_file_id}')
with open(retrieve.filename, "wb") as file:
result = client.files.content(result_file_id).read()
file.write(result)
O ficheiro de resultados é um ficheiro CSV que contém uma linha de cabeçalho e uma linha para cada passo de treino realizado pelo trabalho de ajuste fino. O ficheiro de resultados contém as seguintes colunas:
| Nome da coluna | Descrição |
|---|---|
step |
O número da etapa de formação. Um passo de treino representa uma única passagem, para a frente e para trás, sobre um lote de dados de treino. |
train_loss |
A perda para a turma de treino. |
train_mean_token_accuracy |
A percentagem de tokens no lote de treino que o modelo previu corretamente. Por exemplo, se o tamanho do lote estiver definido como 3 e os seus dados conterem completações [[1, 2], [0, 5], [4, 2]], este valor é definido para 0.83 (5 de 6) se o modelo previu [[1, 1], [0, 5], [4, 2]]. |
valid_loss |
A perda para o lote de validação. |
validation_mean_token_accuracy |
A percentagem de tokens no lote de validação que o modelo previu corretamente. Por exemplo, se o tamanho do lote estiver definido como 3 e os seus dados conterem completações [[1, 2], [0, 5], [4, 2]], este valor é definido para 0.83 (5 de 6) se o modelo previu [[1, 1], [0, 5], [4, 2]]. |
full_valid_loss |
A perda de validação calculada no final de cada época. Quando o treino corre bem, a perda deverá diminuir. |
full_valid_mean_token_accuracy |
A precisão média válida dos tokens calculada no final de cada época. Quando o treino está a correr bem, a precisão dos tokens deve aumentar. |
Também pode ver os dados no seu ficheiro results.csv como gráficos no portal Microsoft Foundry. Quando seleciona o link do seu modelo treinado, aparecem três gráficos: perda, precisão média do token e precisão do token. Se forneceu dados de validação, ambos os conjuntos de dados aparecem no mesmo gráfico.
Espera que a tua perda diminua com o tempo e que a tua precisão aumente. Se os teus dados de treino e validação divergem, podes estar a sobreajustar. Tenta treinar com menos épocas ou com um multiplicador de taxa de aprendizagem mais pequeno.
Implementar um modelo afinado
Quando estiver satisfeito com as métricas do seu trabalho de ajuste fino, ou simplesmente quiser avançar para inferência, deve implementar o modelo.
Se estiver a implementar para validação adicional, considere implementar para testes usando uma implementação de desenvolvedor.
Ao contrário dos comandos anteriores do SDK, deve usar a API do plano de controlo para a implementação. Esta tarefa requer autorização separada, um caminho de API diferente e uma versão diferente da API.
| Variável | Definição |
|---|---|
token |
Um token de autorização. Existem várias formas de gerar um token de autorização. O método mais fácil para testes iniciais é abrir Azure Cloud Shell a partir do portal Azure. Depois executa az account get-access-token. Pode usar este token como token de autorização temporária para testes de API. Recomendamos armazenar este token numa nova variável de ambiente. |
subscription |
O ID de subscrição para o recurso Azure OpenAI associado. |
resource_group |
O nome do grupo de recursos para o seu recurso Azure OpenAI. |
resource_name |
O nome do recurso Azure OpenAI. |
model_deployment_name |
O nome personalizado para a sua nova implementação de modelo ajustado. Este nome é referido no seu código durante as chamadas de conclusão do chat. |
fine_tuned_model |
O teu modelo afinado. Recupere este valor dos resultados do seu trabalho de afinação na etapa anterior. Parece que gpt-4.1-2025-04-14.ft-b044a9d3cf9c4228b5d393567f693b83. Tens de acrescentar valor ao deploy_data JSON. Alternativamente, pode implementar um ponto de controlo passando pelo ID do ponto de controlo, que aparece no formato ftchkpt-e559c011ecc04fc68eaa339d8227d02d. |
import json
import os
import requests
token= os.getenv("<TOKEN>")
subscription = "<YOUR_SUBSCRIPTION_ID>"
resource_group = "<YOUR_RESOURCE_GROUP_NAME>"
resource_name = "<YOUR_AZURE_OPENAI_RESOURCE_NAME>"
model_deployment_name ="gpt-41-ft" # Custom deployment name that you use to reference the model when making inference calls.
deploy_params = {'api-version': "2024-10-01"} # Control plane API version rather than the data plane API for this call
deploy_headers = {'Authorization': 'Bearer {}'.format(token), 'Content-Type': 'application/json'}
deploy_data = {
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": <"fine_tuned_model">, # Retrieve this value from the previous call; it looks like gpt-4.1-2025-04-14.ft-b044a9d3cf9c4228b5d393567f693b83
"version": "1"
}
}
}
deploy_data = json.dumps(deploy_data)
request_url = f'https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}'
print('Creating a new deployment...')
r = requests.put(request_url, params=deploy_params, headers=deploy_headers, data=deploy_data)
print(r)
print(r.reason)
print(r.json())
Para aprender sobre implementação entre regiões e como usar o modelo implementado, consulte Use o seu modelo finamente ajustado implementado.
Se estiver pronto para implementar para produção ou tiver necessidades específicas de residência de dados, siga o guia de implementação.
Realizar ajustes finos contínuos
Depois de criar um modelo afinado, pode querer continuar a refinar o modelo ao longo do tempo através de mais ajustes finos. O ajuste fino contínuo é o processo iterativo de selecionar um modelo já afinado como modelo base e afiná-lo ainda mais em novos conjuntos de exemplos de treino. O ajuste fino contínuo é suportado apenas para modelos OpenAI.
Para realizar o ajuste fino de um modelo que já afinou anteriormente, utiliza-se o mesmo processo descrito em Criar um modelo personalizado. Mas em vez de especificar o nome de um modelo base genérico, especifica o ID do seu modelo finamente ajustado. O ID do modelo afinado parece ser gpt-4.1-2025-04-14.ft-5fd1918ee65d4cd38a5dcf6835066ed7.
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model="gpt-4.1-2025-04-14.ft-5fd1918ee65d4cd38a5dcf6835066ed7"
)
job_id = response.id
# You can use the job ID to monitor the status of the fine-tuning job.
# The fine-tuning job takes some time to start and finish.
print("Job ID:", response.id)
print("Status:", response.id)
print(response.model_dump_json(indent=2))
Recomendamos também que inclua o suffix parâmetro para distinguir mais facilmente as iterações do seu modelo ajustado. O suffix parâmetro assume uma cadeia e é definido para identificar o modelo finamente ajustado. Com a API Python da OpenAI, pode adicionar uma cadeia de até 18 caracteres ao nome do seu modelo finamente ajustado.
Se não tiver a certeza do ID do seu modelo afinado atual, pode encontrar esta informação na página Modelos da Microsoft Foundry. Ou pode gerar uma lista de modelos para um recurso Azure OpenAI usando a API REST.
Limpa as tuas implementações, modelos personalizados e ficheiros de treino
Quando deixar de precisar do seu modelo personalizado, pode apagar a implementação e o modelo. Também pode apagar os ficheiros de treino e validação que carregou para o serviço, se necessário.
Apague a implementação do seu modelo
Importante
Depois de implementar um modelo personalizado, se em algum momento a implementação permanecer inativa por mais de 15 dias, a implementação é eliminada. A implementação de um modelo personalizado está inativa se o modelo foi implementado há mais de 15 dias e não foram feitas chamadas de chat ou respostas à API durante um período contínuo de 15 dias.
A eliminação de uma implementação inativa não apaga nem afeta o modelo personalizado subjacente. O modelo personalizado pode ser redistribuído a qualquer momento.
Como descrito em Preços do Azure OpenAI nos Modelos Microsoft Foundry, cada modelo personalizado (ajustado) implementado implica um custo horário de hospedagem, independentemente de serem feitas chamadas de chat ou chamadas à API de resposta ao modelo. Para saber mais sobre planeamento e gestão de custos com Azure OpenAI, consulte Planear e gerir custos para Azure OpenAI.
Pode usar qualquer um destes métodos para eliminar a implementação do seu modelo personalizado:
Apague o seu modelo personalizado
Pode eliminar o seu modelo personalizado usando o Foundry.
Nota
Não podes eliminar um modelo personalizado se ele tiver uma implementação existente. Deve eliminar a implementação do seu modelo antes de poder eliminar o seu modelo personalizado.
Apague os seus ficheiros de treino
Pode, opcionalmente, eliminar ficheiros de treino e validação que carregou para treino, bem como ficheiros de resultados gerados durante o treino, da sua subscrição Azure OpenAI. Pode usar os seguintes métodos para eliminar os seus ficheiros de treino, validação e resultados:
O seguinte exemplo de Python usa o SDK Python para eliminar os ficheiros de treino, validação e resultados do seu modelo personalizado:
print('Checking for existing uploaded files.')
results = []
# Get the complete list of uploaded files in your subscription.
files = openai.File.list().data
print(f'Found {len(files)} total uploaded files in the subscription.')
# Enumerate all uploaded files. Extract the IDs for the
# files with file names that match your training dataset file and
# validation dataset file.
for item in files:
if item["filename"] in [training_file_name, validation_file_name, result_file_name]:
results.append(item["id"])
print(f'Found {len(results)} already uploaded files that match our files')
# Enumerate the file IDs for your files and delete each file.
print(f'Deleting already uploaded files.')
for id in results:
openai.File.delete(sid = id)
Pré-requisitos
- Leia o guia sobre quando usar a afinação do Azure OpenAI.
- Precisas de uma subscrição do Azure. Crie um gratuitamente.
- Precisas de um recurso Azure OpenAI. Para mais informações, consulte Crie um recurso e implemente um modelo com Azure OpenAI.
- O ajuste fino requer o papel de Proprietário da IA Azure. Embora os Utilizadores de IA do Azure possam treinar (ajustar finamente) modelos, apenas os Proprietários de IA podem implementá-los.
- Se ainda não tiver acesso para ver quotas e implementar modelos no portal Foundry, precisa de mais permissões.
Modelos suportados
Para verificar quais as regiões que atualmente suportam ajuste fino, consulte o artigo sobre modelos.
Ou pode afinar finamente um modelo previamente ajustado, formatado como base-model.ft-{jobid}.
Revise o fluxo de trabalho da API REST
Reserve um momento para rever o fluxo de trabalho de ajuste fino para usar a API REST e Python com Azure OpenAI:
- Prepare os dados de treino e validação.
- Escolhe um modelo base.
- Carregue os seus dados de treino.
- Treine o seu novo modelo personalizado.
- Verifique o estado do seu modelo personalizado.
- Implemente o seu modelo personalizado para uso.
- Use o seu modelo personalizado.
- Opcionalmente, analisa o teu modelo personalizado quanto ao desempenho e ao ajuste.
Prepare os seus dados de treino e validação
Os seus conjuntos de dados de treino e validação consistem em exemplos de entrada e saída de como deseja que o modelo execute.
Os dados de treino e validação que utiliza devem ser formatados como um documento de Linhas JSON (JSONL). Deve também ser formatado no formato conversacional que a API de Conversas Completas utiliza.
Para além do formato JSONL, os ficheiros de dados de treino e validação devem ser codificados em UTF-8 e incluir uma marca de ordem de bytes (BOM). Cada ficheiro deve ter menos de 512 MB.
Se quiseres um guia passo a passo sobre o ajuste fino gpt-4o-mini-2024-07-18, vê o tutorial de ajuste fino Azure OpenAI.
Formato de ficheiro de exemplo
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who discovered Antarctica?"}, {"role": "assistant", "content": "Some chaps named Fabian Gottlieb von Bellingshausen and Mikhail Lazarev, as if they don't teach that in every school!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the biggest ocean?"}, {"role": "assistant", "content": "The Pacific Ocean. It's not like it's a small pond or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest planet?"}, {"role": "assistant", "content": "It's called Jupiter, you might have heard of it...or not."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who painted the Mona Lisa?"}, {"role": "assistant", "content": "Oh, some obscure artist named Leonardo da Vinci. Not that he is famous or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the boiling point of water?"}, {"role": "assistant", "content": "Exciting fact of the day: it's 100 degrees Celsius. Life-changing, isn't it?"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'The Odyssey'?"}, {"role": "assistant", "content": "Oh, just some poet named Homer. Nothing special, really."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest mammal?"}, {"role": "assistant", "content": "Blue Whale. Quite a big fish isn't it? Oh wait, it's not a fish!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the highest mountain peak?"}, {"role": "assistant", "content": "Everest. Brace yourself, it's not a walk in the park."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who invented the telephone?"}, {"role": "assistant", "content": "A guy named Alexander Graham Bell. Bet you didn't guess that one!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the distance from Earth to the Sun?"}, {"role": "assistant", "content": "About 93 million miles. Just a quick drive, really."}]}
Formato de ficheiro de conversas de múltiplas voltas
Também são suportados múltiplos turnos de uma conversa numa única linha do seu ficheiro de treino JSONL. Para evitar ajustes finos em mensagens específicas do assistente, adicione o par opcional weight chave/valor. Atualmente, weight pode ser definido como 0 ou 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital/major city of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Finalizações de conversas com capacidades visuais
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Crie os seus conjuntos de dados de treino e validação
Quanto mais exemplos de treino tiveres, melhor. Os trabalhos de ajuste fino não avançam sem pelo menos 10 exemplos de treino, mas um número tão pequeno não é suficiente para influenciar de forma notória as respostas do modelo. Uma boa prática para um ajuste fino bem-sucedido é fornecer centenas, senão milhares, de exemplos de treino.
Em geral, duplicar o tamanho do conjunto de dados pode levar a um aumento linear da qualidade do modelo. Mas tenha em mente que exemplos de baixa qualidade podem afetar negativamente o desempenho. Se treinar o modelo com uma grande quantidade de dados internos sem primeiro podar o conjunto de dados apenas para os exemplos de maior qualidade, o seu modelo pode ter um desempenho pior do que o esperado.
Carregue os seus dados de treino
O passo seguinte é escolher os dados de treino preparados existentes ou carregar novos dados preparados para usar quando estiver a personalizar o seu modelo. Depois de preparar os seus dados de treino, pode carregar os seus ficheiros para o serviço. Existem duas formas de carregar dados de treino:
- A partir de um ficheiro local
- De Armazenamento de Blobs do Azure ou de uma localização web (importação)
Para ficheiros de dados grandes, recomendamos que importe do Armazenamento de Blobs. Ficheiros grandes podem tornar-se instáveis quando se carregam através de formulários multipartes porque os pedidos são atómicos e não podem ser repetidos ou reiniciados. Para mais informações sobre Armazenamento de Blobs, veja O que é Armazenamento de Blobs do Azure?.
Carregar dados de treino
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/v1/files \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@C:\\fine-tuning\\training_set.jsonl;type=application/json"
Carregar dados de validação
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/v1/files \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@C:\\fine-tuning\\validation_set.jsonl;type=application/json"
Crie um modelo personalizado
Depois de carregares os teus ficheiros de treino e validação, estás pronto para começar o trabalho de afinação. O código seguinte mostra um exemplo de como criar um novo trabalho de ajuste fino usando a API REST.
Este exemplo inclui passar o parâmetro seed. A semente controla a reprodutibilidade do trabalho. Passar os mesmos parâmetros de semente e de trabalho deverá produzir os mesmos resultados, mas poderão diferir em casos raros. Se não especificares uma semente, é gerada uma para ti.
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/v1/fine_tuning/jobs \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-4.1-2025-04-14",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"seed": 105
}'
Se estiver a afinar um modelo que suporta treino global, pode especificar o tipo de treino usando o argumento extra_body nomeado e usando api-version=2025-04-01-preview:
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs?api-version=2025-04-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-4.1-2025-04-14",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"seed": 105,
"trainingType": "globalstandard"
}'
Também pode passar parâmetros opcionais adicionais, como hiperparâmetros , para assumir maior controlo do processo de afinação. Para o treino inicial, recomendamos usar os valores automáticos que estão presentes sem especificar esses parâmetros.
Os hiperparâmetros atualmente suportados para ajuste fino supervisionado são:
| Nome | Tipo | Descrição |
|---|---|---|
batch_size |
Integer | O tamanho do lote a usar para treino. O tamanho do lote é o número de exemplos de treino usados para treinar uma única passagem para a frente e para trás. Em geral, verificamos que lotes maiores tendem a funcionar melhor para conjuntos de dados maiores. O valor padrão e o valor máximo desta propriedade são específicos de um modelo base. Um tamanho de lote maior significa que os parâmetros do modelo são atualizados com menos frequência, mas com menor variância. |
learning_rate_multiplier |
Número | O multiplicador de taxa de aprendizagem para usar no treino. A taxa de aprendizagem usada para ajuste fino é a taxa de aprendizagem original utilizada no pré-treino, multiplicada por este valor. Taxas de aprendizagem mais elevadas tendem a ter melhor desempenho com lotes maiores. Recomendamos experimentar valores no intervalo de 0.02 para 0.2 ver o que produz os melhores resultados. Uma taxa de aprendizagem mais baixa pode ser útil para evitar o sobreajuste. |
n_epochs |
Integer | O número de épocas para treinar o modelo. No contexto do machine learning, um "epoch" refere-se a um ciclo inteiro de treino através do conjunto de dados. |
seed |
Integer | A semente que controla a reprodutibilidade do trabalho. |
Para saber sobre os hiperparâmetros suportados para os outros métodos de personalização, consulte o guia para otimização direta de preferências e o guia para ajuste fino de reforços.
Selecione um tipo de treino
Selecione o nível de formação com base no seu caso de uso e orçamento:
Padrão: A formação ocorre na região atual do recurso Foundry e garante a residência dos dados. Ideal para cargas de trabalho onde os dados têm de permanecer numa região específica.
Global: Oferece preços mais acessíveis em comparação com o Standard, utilizando capacidade para além da sua região atual. Os dados e pesos são copiados para a região onde ocorre o treino. Ideal se a residência de dados não for uma restrição e quiseres tempos de fila mais rápidos.
Developer (versão de pré-visualização): Oferece uma redução significativa de custos ao utilizar a capacidade de inatividade para treino. Não há garantias de latência ou SLA, por isso os empregos neste nível podem ser automaticamente preemptados e retomados mais tarde. Também não há garantias de residência de dados. Ideal para experimentação e cargas de trabalho sensíveis a preços.
curl -X POST "https://<ACCOUNT-NAME>.openai.azure.com/openai/fine_tuning/jobs?api-version=2025-04-01-preview" -H "Content-Type: application/json" -H "api-key: <API-KEY>" -d "{"model": "gpt-4.1", "training_file": "<FILE_ID>", "hyperparameters": {"prompt_loss_weight": 0.1}, "trainingType": "developerTier"}"
Verifique o estado do seu modelo personalizado
Depois de começar um trabalho de afinação, pode demorar algum tempo a terminar. O teu trabalho pode estar colocado atrás de outros empregos no sistema. Treinar o seu modelo pode demorar minutos ou horas, dependendo do modelo e do tamanho do conjunto de dados.
O exemplo seguinte utiliza a API REST para verificar o estado do seu trabalho de ajuste fino. O exemplo recupera informações sobre o seu trabalho usando o ID do trabalho devolvido do exemplo anterior.
curl -X GET $AZURE_OPENAI_ENDPOINT/openai/v1/fine_tuning/jobs/<YOUR-JOB-ID> \
-H "api-key: $AZURE_OPENAI_API_KEY"
Lista de eventos de ajuste fino
Para examinar os eventos individuais de otimização gerados durante o treinamento:
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/v1/fine_tuning/jobs/{fine_tuning_job_id}/events \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Listar pontos de controlo
A conclusão de cada época de aprendizagem gera um ponto de verificação. Um checkpoint é uma versão totalmente funcional de um modelo que pode ser tanto implementada como usada como modelo-alvo para trabalhos subsequentes de ajuste fino. Os checkpoints podem ser particularmente úteis, pois podem fornecer instantâneos antes do sobreajuste.
Quando um trabalho de afinação termina, tens as três versões mais recentes do modelo disponíveis para implementar. O seu modelo afinado representa a época final. As duas épocas anteriores estão disponíveis como pontos de controlo.
Pode executar o seguinte comando para recuperar a lista de checkpoints associados a um trabalho individual de ajuste fino:
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/v1/fine_tuning/jobs/{fine_tuning_job_id}/checkpoints \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Pausa e retoma
Durante a formação, pode ver os registos e métricas e pausar o trabalho conforme necessário. Pausar pode ser útil se as métricas não convergirem ou se sentires que o modelo não está a aprender ao ritmo certo.
Após a pausa do trabalho de formação e a conclusão das avaliações de segurança, é criado um ponto de controlo implantável. Este checkpoint está disponível para implementares e usares para inferência, ou podes retomar o trabalho para o concluir.
A operação de pausa é aplicável apenas a tarefas treinadas para pelo menos um passo e que estão em estado Em execução.
Pausa
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/v1/fine_tuning/jobs/{fine_tuning_job_id}/pause \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Currículo
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/v1/fine_tuning/jobs/{fine_tuning_job_id}/resume \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Copiar um modelo (pré-visualização)
Agora pode copiar um modelo de checkpoint afinado de uma região para outra, através de diferentes subscrições mas dentro do mesmo tenant. O processo utiliza APIs dedicadas para ajudar a garantir transferências eficientes e seguras. Esta funcionalidade está atualmente disponível apenas com a API e não através do portal Foundry.
Depois de o modelo ser copiado da região A para a região B, pode afinar continuamente o modelo na região B e implantá-lo a partir dessa localização.
Nota
A eliminação do checkpoint do modelo na região de origem não faz com que o modelo seja eliminado na região de destino. Para eliminar o modelo em ambas as regiões depois de ser copiado, tens de implantar o modelo separadamente em cada região.
Pré-requisitos
- O recurso de destino ou a conta deve ter pelo menos uma tarefa de ajuste fino.
- O recurso de destino ou a conta não devem desativar o acesso à rede pública (pelo menos enquanto envia o pedido de cópia).
- Só pode copiar para a conta de destino, se a conta que inicia a cópia tiver permissões suficientes para aceder à conta de destino.
Configurar permissões
- Crie uma identidade gerida atribuída pelo utilizador.
- Atribui a função de Utilizador de IA do Azure à sua identidade gerida atribuída a utilizador no seu recurso de destino ou conta.
- Atribua a identidade gerida pelo utilizador à sua conta de recurso de origem.
Copiar o modelo
curl --request POST \
--url 'https://<aoai-resource>.openai.azure.com/openai/v1/fine_tuning/jobs/<ftjob>/checkpoints/<checkpoint-name>/copy' \
--header 'Content-Type: application/json' \
--header 'api-key: <api-key>' \
--header 'aoai-copy-ft-checkpoints: preview' \
--data '{
"destinationResourceId": "<resourceId>",
"region": "<region>"
}'
Como esta é uma operação de longa duração, verifique o estado da cópia do modelo ajustada fornecendo o ID do checkpoint da conta de origem usada na POST chamada.
Verifica o estado da cópia
curl --request GET \
--url 'https://<aoai-resource>.openai.azure.com//openai/v1/fine_tuning/jobs/<ftjob>/checkpoints/<checkpoint-name>/copy' \
--header 'Content-Type: application/json' \
--header 'api-key: <api-key>' \
--header 'aoai-copy-ft-checkpoints: preview'
Nota
Quando copias um checkpoint a partir de uma conta de origem, o mesmo nome do checkpoint é mantido na conta de destino. Certifique-se de usar exatamente o mesmo nome para ajustes finos, implementação ou qualquer outra operação na conta de destino. Este checkpoint não aparece na interface nem na list checkpoints API.
Analise o seu modelo personalizado
Azure OpenAI anexa um ficheiro de resultado chamado results.csv a cada tarefa de ajuste fino após a sua conclusão. Pode usar o ficheiro de resultados para analisar o desempenho de treino e validação do seu modelo personalizado. O ID do ficheiro do resultado está listado para cada modelo personalizado. Pode usar a API REST para recuperar o ID do ficheiro e descarregar o ficheiro de resultados para análise.
O exemplo seguinte em Python utiliza a API REST para recuperar o ID do ficheiro do primeiro resultado anexado ao trabalho de ajuste fino do seu modelo personalizado. Depois, descarrega o ficheiro para o seu diretório de trabalho para análise.
curl -X GET "$AZURE_OPENAI_ENDPOINT/openai/v1/fine_tuning/jobs/<JOB_ID>" \
-H "api-key: $AZURE_OPENAI_API_KEY")
curl -X GET "$AZURE_OPENAI_ENDPOINT/openai/v1/files/<RESULT_FILE_ID>/content" \
-H "api-key: $AZURE_OPENAI_API_KEY" > <RESULT_FILENAME>
O ficheiro de resultados é um ficheiro CSV que contém uma linha de cabeçalho e uma linha para cada passo de treino realizado pelo trabalho de ajuste fino. O ficheiro de resultados contém as seguintes colunas:
| Nome da coluna | Descrição |
|---|---|
step |
O número da etapa de formação. Um passo de treino representa uma única passagem, para a frente e para trás, sobre um lote de dados de treino. |
train_loss |
A perda para a turma de treino. |
train_mean_token_accuracy |
A percentagem de tokens no lote de treino que o modelo previu corretamente. Por exemplo, se o tamanho do lote estiver definido como 3 e os seus dados conterem completações [[1, 2], [0, 5], [4, 2]], este valor é definido para 0.83 (5 de 6) se o modelo previu [[1, 1], [0, 5], [4, 2]]. |
valid_loss |
A perda para o lote de validação. |
validation_mean_token_accuracy |
A percentagem de tokens no lote de validação que o modelo previu corretamente. Por exemplo, se o tamanho do lote estiver definido como 3 e os seus dados conterem completações [[1, 2], [0, 5], [4, 2]], este valor é definido para 0.83 (5 de 6) se o modelo previu [[1, 1], [0, 5], [4, 2]]. |
full_valid_loss |
A perda de validação calculada no final de cada época. Quando o treino corre bem, a perda deverá diminuir. |
full_valid_mean_token_accuracy |
A precisão média válida dos tokens calculada no final de cada época. Quando o treino está a correr bem, a precisão dos tokens deve aumentar. |
Também pode visualizar os dados no seu results.csv ficheiro como gráficos no portal Foundry. Quando seleciona o link do seu modelo treinado, aparecem três gráficos: perda, precisão média do token e precisão do token. Se forneceu dados de validação, ambos os conjuntos de dados aparecem no mesmo gráfico.
Espera que a tua perda diminua com o tempo e que a tua precisão aumente. Se os teus dados de treino e validação divergem, podes estar a sobreajustar. Tenta treinar com menos épocas ou com um multiplicador de taxa de aprendizagem mais pequeno.
Implementar um modelo afinado
Quando estiver satisfeito com as métricas do seu trabalho de ajuste fino, ou simplesmente quiser avançar para inferência, deve implementar o modelo.
Se estiver a implementar para validação adicional, considere implementar para testes usando uma implementação de desenvolvedor.
Se estiver pronto para implementar para produção ou tiver necessidades específicas de residência de dados, siga o guia de implementação.
| Variável | Definição |
|---|---|
token |
Um token de autorização. Existem várias formas de gerar um token de autorização. O método mais fácil para testes iniciais é abrir Azure Cloud Shell a partir do portal Azure. Depois executa az account get-access-token. Pode usar este token como token de autorização temporária para testes de API. Recomendamos armazenar este token numa nova variável de ambiente. |
subscription |
O ID de subscrição para o recurso Azure OpenAI associado. |
resource_group |
O nome do grupo de recursos para o seu recurso Azure OpenAI. |
resource_name |
O nome do recurso Azure OpenAI. |
model_deployment_name |
O nome personalizado para a sua nova implementação de modelo ajustado. Este nome é referido no seu código durante as chamadas de conclusão do chat. |
fine_tuned_model |
O teu modelo afinado. Recupere este valor dos resultados do seu trabalho de afinação na etapa anterior. Parece que gpt-4.1-2025-04-14.ft-b044a9d3cf9c4228b5d393567f693b83. Tens de acrescentar valor ao deploy_data JSON. Alternativamente, pode implementar um ponto de controlo passando pelo ID do ponto de controlo, que aparece no formato ftchkpt-e559c011ecc04fc68eaa339d8227d02d. |
curl -X POST "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>?api-version=2024-10-21" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1"
}
}
}'
Para aprender sobre implementação entre regiões e como usar o modelo implementado, consulte Use o seu modelo finamente ajustado implementado.
Realizar ajustes finos contínuos
Depois de criar um modelo afinado, pode querer continuar a refinar o modelo ao longo do tempo através de mais ajustes finos. O ajuste fino contínuo é o processo iterativo de selecionar um modelo já afinado como modelo base e afiná-lo ainda mais em novos conjuntos de exemplos de treino. O ajuste fino contínuo é suportado apenas para modelos OpenAI.
Para realizar o ajuste fino de um modelo que já afinou anteriormente, utiliza-se o mesmo processo descrito em Criar um modelo personalizado. Mas em vez de especificar o nome de um modelo base genérico, especifica o ID do seu modelo finamente ajustado. O ID do modelo afinado parece ser gpt-4.1-2025-04-14.ft-5fd1918ee65d4cd38a5dcf6835066ed7.
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/v1/fine_tuning/jobs \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-4.1-2025-04-14.ft-5fd1918ee65d4cd38a5dcf6835066ed7",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"suffix": "<additional text used to help identify fine-tuned models>"
}'
Recomendamos também que inclua o suffix parâmetro para distinguir mais facilmente as iterações do seu modelo ajustado. O suffix parâmetro assume uma cadeia e é definido para identificar o modelo finamente ajustado. O sufixo pode conter até 40 caracteres (a para z, A para Z, 0 para 9, -, , e _) que são adicionados ao nome do seu modelo afinado.
Se não tiver a certeza do ID do seu modelo afinado atual, pode encontrar esta informação na página de Modelos da Foundry. Ou pode gerar uma lista de modelos para um recurso Azure OpenAI usando a API REST.
Limpa as tuas implementações, modelos personalizados e ficheiros de treino
Quando deixar de precisar do seu modelo personalizado, pode apagar a implementação e o modelo. Também pode apagar os ficheiros de treino e validação que carregou para o serviço, se necessário.
Apague a implementação do seu modelo
Pode usar qualquer um destes métodos para eliminar a implementação do seu modelo personalizado:
Apague o seu modelo personalizado
Pode eliminar o seu modelo personalizado usando o Foundry.
Nota
Não podes eliminar um modelo personalizado se ele tiver uma implementação existente. Deve eliminar a implementação do seu modelo antes de poder eliminar o seu modelo personalizado.
Apague os seus ficheiros de treino
Pode, opcionalmente, eliminar ficheiros de treino e validação que carregou para treino, bem como ficheiros de resultados gerados durante o treino, da sua subscrição Azure OpenAI. Podes usar o Foundry para apagar os ficheiros.